matlab有pytorch框架,图解Faster-RCNN的PyTorch实现
本文用图解的方式,分析Faster-RCNN的PyTorch实现,以便直观地了解各个模块之间的调用和依赖关系,以及对NMS和ROI Align的CUDA实现的解读。
下面我们以trainval_net.py为入口,解读一下Faster-RCNN的PyTorch实现过程。
我们采用的数据集是PASCAL VOC 2007,采用的CNN模型是ResNet-101。
数据读取
数据读取过程大致为:提前读取训练样本的包围框(后文用bounding box的简称bbox指代),把bbox的坐标等信息保存在内存里。该步骤并不需要把训练集的图片存在内存里,但会对长宽比超过一定范围的bbox做一下筛选,同时也会根据需要产生水平翻转的bbox,便于在训练过程中增加模型的泛化能力。当需要用dataloader读取样本时,才从硬盘上读取图像数据,进行预处理,并缩放到所需的大小。
下面详细介绍数据读取的代码。
bbox的读取
下图描述了combined_roidb('voc_2007_trainval')函数内部的调用关系。(图片是在diagrams.net画的)
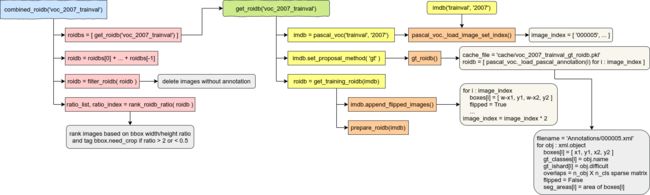
bbox的读取过程如下:
有的数据集可以利用两个或多个不同的子样本集合并成一个更大更丰富的训练集,子样本集之间用“+”分割,比如COCO的“coco_2014_train+coco_2014_valminusminival”。这里用roi_data_layer.roidb.combined_roidb.get_roidb()分别读取各个子样本集的bbox。具体来说:
get_roidb('voc_2007_trainval')用Lambda函数创建了一个lib.datasets.pascal_voc.pascal_voc类实例,而这个类是从lib.datasets.imdb.imdb继承来的。imdb这个类用来保存不同样本集的图片编号、bbox、类别信息等。pascal_voc('trainval', '2007')在初始化时会创建一个名为image_index的list,其中保存了所有样本图片的编号(比如“000005”),根据这些编号就可以从硬盘读取图片。
用lib.datasets.imdb.imdb.set_proposal_method('gt')方法将lib.datasets.imdb.imdb.roidb_handler成员设置为在lib.datasets.pascal_voc.pascal_voc当中定义的gt_roidb()方法。这个方法是用来读取样本集的ground truth bbox的。另外,在lib.datasets.pascal_voc.pascal_voc中还定义了一个rpn_roidb()方法,就是用RPN网络选取bbox的实现。在这个过程中,真实的bbox是从PASCAL VOC数据集的Annotations文件夹中取得的(比如“000005.xml”)。最后得到一个dict,包含了“boxes”,“gt_classes”,“gt_ishard”,“overlaps”,“flipped”,“seg_areas”几个key,分别代表bbox坐标、bbox类别、是否为难样本、标记类别的one-hot稀疏矩阵、是否为水平翻转的图片、bbox面积。
用roi_data_layer.roidb.combined_roidb.get_training_roidb(imdb)对bbox做一下预处理。包括用lib.datasets.imdb.imdb.append_flipped_images()把所有bbox做一下水平翻转,同时把image_index增长为原来的两倍,然后用roi_data_layer.roidb.combined_roidb.prepare_roidb(imdb)预先计算一下后面训练过程中可能会用到的值。
把从各个子样本集得到的bbox的list合并成一个list。
过滤掉没有bbox的样本。
根据bbox的宽高比对样本排序。其中宽高比大于2或小于0.5的bbox会标记为“need_crop”,便于后面对这些样本做裁剪。
dataloader的实现
下图描述了传入torch.utils.data.DataLoader的roi_data_layer.roibatchLoader.roibatchLoader类的依赖关系,这个类用来创建兼容PyTorch的dataset对象,以便在训练和预测过程中被DataLoader调用,读取样本的mini-batch。
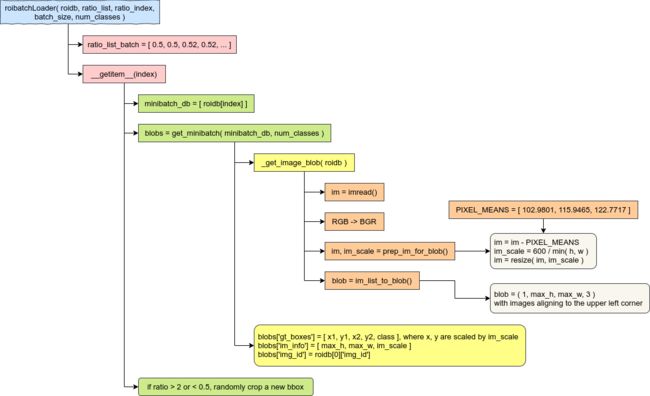
在roibatchLoader类初始化时,会根据之前得到的排好序的ratio_list和ratio_index产生一个长度等于总样本量的list,其中每连续batch_size个数值都是相同的。如果宽高比(后文用ratio指代)小于1,则选取最小的ratio作为这个batch的统一ratio;如果ratio大于1,则选取最大的ratio作为统一ratio值。这样是为了使同一个batch内的ratio保持相同。
DataLoader需要通过索引值从dataset里获取某一个样本,该过程靠__getitem__(self, index)来实现,具体过程如下:
根据index从前文得到的roidb里获取bbox信息。如果是训练模式,则通过ratio_index间接获取index。然后将包含bbox信息的dict存在一个长度为1名为“minibatch_db”的list中。
用roi_data_layer.minibatch.get_minibatch(minibatch_db, num_classes)读取图片并产生一个mini-batch。具体来说:
读取图片并构造batch主要是在roi_data_layer.minibatch._get_image_blob(roidb, 0)当中实现的,具体步骤包括
用imread读取图片。原repo用的是scipy.misc.imread,我这里改为调用imageio.imread,当然用OpenCV的cv2.imread也是可以的;
把图片的色彩空间从RGB转化为OpenCV默认的BGR。所以如果上一步用的是cv2.imread,那么这一步是不需要的;
如果该bbox被标记为“flipped”,则将图片水平翻转;
用lib.model.utils.blob.prep_im_for_blob()减去样本集的均值(这个均值对不同的CNN在训练和预测时都是同一组值)然后缩放到较短边为600的尺寸;
用lib.model.utils.blob.im_list_to_blob()创建一个尺寸为(1, max_h, max_w, 3)的张量,并按照左上角对齐的方式把图片矩阵拷贝进来。
以同样的比例缩放bbox,然后把样本的相关信息保存在一个dict当中(即blobs)。
最后,检查一下bbox是否因为宽高比超出范围需要裁剪,在较长边的方向上按照2倍的比例随机剪裁。
模型整体结构
基于ResNet-101的Faster-RCNN模型结构和数据传递过程如下图所示。
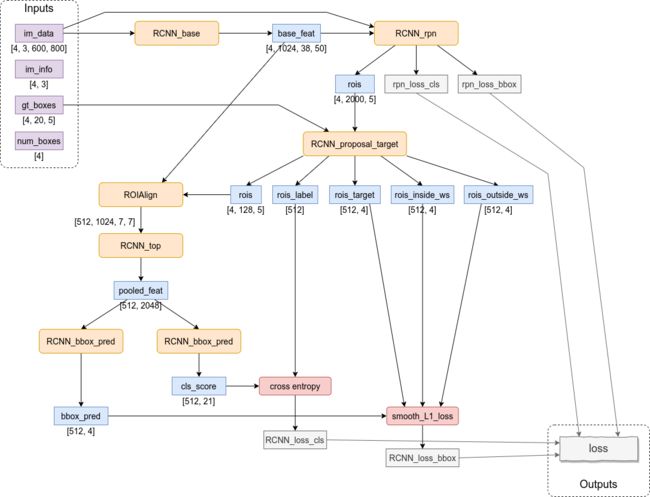
整个模型相当于把ResNet分成了两部分。第一部分包含ResNet的输入层和前3组residual blocks(图中表示为RCNN_base),然后把此时产生的feature map(图中表示为名为base_feat的张量)传入RPN网络,进行一次初步筛选(这里用到了NMS)给出2000个bbox,同时也给出置信度最高的256个bbox(包括128个前景bbox和128个背景bbox)的分类交叉熵误差和坐标的smooth-L1误差。第二部分包含一个ROI Align层和ResNet的第4组residual block(图中表示为RCNN_top),然后再根据此时产生的feature map(图中)得到置信度最高的128个bbox的分类误差和坐标误差。最后,把前面得到的4组误差值加起来,就是整个模型最终的误差。
输入数据的解释:
im_data。尺寸为[4, 3, 600, 800]的张量,是经过dataloader缩放过的样本图像,不同原始尺寸的图像都被缩放至短边长度为600,所以另一条边的长度不一定总是800。
im_info。尺寸为[4, 3]的张量,其中第一个维度的4代表batch size,第二个维度的3保存了每幅图像的高度、宽度和长宽比。因为im_data是按照这组batch中尺寸最大的那幅图像构造出来的,同一组batch中可能存在稍小一些的图像,所以图像的实际尺寸需要从im_info当中获取。值得注意的是,在目前的代码中,图像的实际长度和宽度信息只被用于对超过图像边界的bbox裁剪,另外长宽比这个值没有用到,是冗余的。
gt_boxes。尺寸为[4, 20, 5]的张量,其中第三个维度的5代表真实bbox(ground truth)的坐标和类标签(所以需要4+1个值)。类标签的维度其实有些冗余,因为类别信息本身可以从第二个维度的索引得到,这样设计应该是为了便于直接与网络的预测值(需要同时预测bbox的坐标和类标签)相比较。
num_boxes。尺寸为[4]的张量,原本是用来表示图像中存在的bbox数量,但这个张量在模型中没有用到,所以也不需要关心它的作用。
图中与ResNet网络有关的模块有2个:
RCNN_base。包含ResNet的输入层和前3个residual block:
self.RCNN_base = nn.Sequential(resnet.conv1, resnet.bn1,resnet.relu,
resnet.maxpool,resnet.layer1,resnet.layer2,resnet.layer3)
而且其中的所有conv层和bn层都不参与训练;
RCNN_top。包含ResNet的第4个residual block:
self.RCNN_top = nn.Sequential(resnet.layer4)
而且其中的所有bn层都不参与训练,但是conv层会被微调(fine-tuning),以适应新的数据和误差函数。
模块和层的依赖关系
lib.model.faster_rcnn.faster_rcnn._fasterRCNN,定义了Faster-RCNN的基类。其中调用了:
lib.model.rpn.rpn._RPN,RPN网络,用来产生大量的bbox,然后对这些bbox做一次初步筛选,得到2000个bbox。在这个网络中,调用了:
lib.model.rpn.proposal_layer._ProposalLayer,用来根据事先定义好的9组anchor产生大量的bbox(比如为600*800的图像产生17100个bbox),然后用NMS做一下粗筛,保留下2000个bbox。这里的NMS是利用CUDA在GPU上计算的。
lib.model.rpn.anchor_target_layer._AnchorTargetLayer,用来在经过ResNet前3个residual block处理得到的feature map上的每个像素处都产生9个bbox,并给出每个bbox的预测类标号和坐标,这些bbox会用来计算两组误差rpn_loss_cls和rpn_loss_bbox。
lib.model.rpn.proposal_target_layer_cascade._ProposalTargetLayer,在前一步筛选出的2000个bbox当中再做一次筛选,得到128个bbox。
lib.model.roi_layers.roi_align.ROIAlign,ROI Align层,用来把不同尺寸的feature map归一化到相同大小,方便最后的输出层产生长度相同的预测张量。这里的ROI Align是利用CUDA在GPU上计算的。
lib.model.faster_rcnn.resnet.resnet,继承自_fasterRCNN,定义了RCNN_base, RCNN_top等模块。
下面我们按照模型的计算顺序解释网络的各部分的具体作用和计算逻辑。
bbox的产生
在模型lib.model.faster_rcnn.resnet.resnet初始化的过程中,会在lib.model.rpn.rpn._RPN当中创建一个lib.model.rpn.proposal_layer._ProposalLayer层。在这个_ProposalLayer层初始化的时候,会调用lib.model.rpn.generate_anchors.generate_anchors()函数。这个函数是用来依据3种不同的长宽比(即0.5,1,2)和3种不同的尺寸比例(即8,16,32)产生9组基本的bbox坐标(被称为anchor),这9组anchor用来在图像上(具体地说,是在经过卷积计算得到的feature map上)的不同位置产生大量的bbox。这些bbox就可以作为候选的目标框,经过后续步骤来筛选出最优的检测窗。
产生的9组anchors坐标如下图所示。

需要注意的是,由于计算过程中的浮点数取整规则的不同,实际得到的矩阵的某些值可能会有正负1的误差。如果你是在写论文的话,需要注意检查这个矩阵的值是否和论文作者给出的Matlab结果相同。
RPN的计算
RPN网络的计算过程如下图所示。
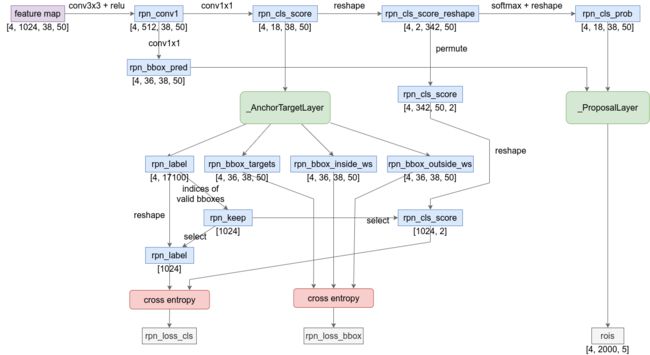
这里的feature map是从ResNet的前3个residual block计算得到的。尺寸为[4, 3, 600, 800]的原始样本张量被映射到一个尺寸为[4, 1024, 38, 50]的feature map。
这个feature map经过两次conv操作和softmax,通道数从1024减少到18。同时,另一组conv也给出了一个通道数为36的张量。这两个张量都被输入到_ProposalLayer。尺寸为[4, 18, 38, 50]的张量rpn_cls_prob可以理解为在38×50的feature map上的每个像素点都产生9个前景预测值和9个背景预测值,相当于以该像素为中心的9种不同的anchor恰好可以给出前景或背景目标的可能性(因为经过了softmax处理,所以可以直观地看成“可能性”)。类似地,尺寸为[4, 36, 38, 50]的张量rpn_cls_pred可以理解为9个bbox的坐标(4×9=36)在_ProposalLayer中,会根据前面9×4的anchor矩阵,一共会产生38×50=1900组bbox,每组相邻的bbox坐标之间实际上相隔16个像素的距离。每组bbox由9种anchor产生9个bbox,所以总的bbox数量为1900×9=17100个。
这些bbox的坐标4个值并不是直接产生x, y, w, h这样的数值,而是相对anchor的x, y方向的偏移量和缩放系数(bbox的长度和宽度是按照指数缩放的,既保证长宽都为正值,又能产生更大范围的数值)。这样前面的conv层只需要产生在1附近抖动的值,就可以映射为数值范围很大的bbox坐标和尺寸。这个从偏移量和缩放系数映射到实际bbox坐标的过程是在lib.model.rpn.bbox_transform.bbox_transform_inv()函数中完成的。映射完之后,还要调用lib.model.rpn.bbox_transform.clip_boxes()把超出feature map范围的bbox进行裁剪(于是这里就用到了im_info输入数据)。
然后,对这17100个bbox按照rpn_cls_prob值排序,取出前12000个bbox。再用NMS从这12000个bbox里选出与高置信度bbox重叠率比较高的(比如两个矩形的交的面积处以并的面积大于0.7),选出重叠率最高的2000个bbox,输出为rois。
NMS的CUDA实现
我们知道Python支持调用C++实现的扩展,以更好地利用CPU性能。由于Python的GIL所限,Python所执行的多线程代码同一时间只能利用一个CPU核心,所以计算密集型任务始终不能提高CPU的利用率。改为C++扩展实现的话,很容易把CPU利用率提高到100%,提高算法的计算速度。类似地,在Faster-RCNN当中,虽然conv, bn等操作可以依靠PyTorch在GPU上计算,但没有被PyTorch实现的一些算法直接在CPU上计算还是有些慢。特别是像NMS这种可以并行化的算法,用CUDA C来实现,并编译成Python扩展可以显著地提高模型的训练速度。
现在PyTorch已经支持CPU和GPU端的NMS,ROI Pooling,ROI Align实现,接口在torchvision.ops当中:https://pytorch.org/docs/stable/torchvision/ops.html。现在可以直接用torchvision.ops.nms执行NMS的计算。但本着学习的目的,我们仍然采用repo里面所给的CUDA实现。另外,通过下面的介绍你也会发现这里的CUDA代码还有很大的优化空间(比如开辟了冗余的显存空间,频繁地在CPU和GPU之间传递数据等)。如果精力允许,可以再读一下PyTorch实现的NMS。
Python的NMS接口在lib.model.roi_layers.nms当中,然后从这里指向了C++模块_C.nms。这个C++函数声明位于lib/model/csrc/nms.h。可以看到,这个函数接受的输入参数和返回值都是在PyTorch C++ API的ATen中定义的Tensor。当CUDA可用时,输入的Tensor被传入lib/model/csrc/cuda/nms.cu文件中的nms_cuda函数:
at::Tensor nms_cuda(const at::Tensor boxes, float nms_overlap_thresh)
这12000个bbox可以分为若干个组,每组里分别用NMS筛选出一些最优bbox之后再把每组的结果合并,可以近似认为与对原始的12000个bbox整体做一次NMS的结果相同。可能会存在位于另一组的bbox和当前组最优bbox重叠度依然很高的情况,但是NMS的主要作用是筛掉不想要的bbox(即抑制掉不是局部极大值的元素)。所以用并行NMS给出多于2000个bbox,再串行地筛选出评分最高的2000个bbox,也是一个十分合理的策略。
在CUDA代码中,建立了一个二维的grid,包含188×188个block。每个block是一维的,包含64或32个thread(最后一个block包含32个thread)。这样,在grid的x或y方向上都包含187×64+32=12000个thread,每个thread都用来计算一个bbox与该block当中最优bbox的重叠率(overlap)。对于重叠率大于0.7的bbox,会在一段连续的内存mask当中以bit为0/1的方式对该bbox是否保留进行标记。由于所有的bbox已经在Python中按照评分排好了序,所以每个block内的各个bbox只需要与该block内的第一个bbox计算重叠率就好。单个bbox的重叠率的计算是在nms_kernel函数中完成的,调用方式如下:
nms_kernel<<>>(boxes_num,
nms_overlap_thresh,
boxes_dev,
mask_dev);
<<<...>>>是CUDA C特有的语法,用来从宿主端(即CPU端)调用CUDA的global函数。这里bbox数据已经从Tensor转换为float数组。
nms_kernel函数格式如下:
__global__ void nms_kernel(const int n_boxes, const float nms_overlap_thresh,
const float *dev_boxes, unsigned long long *dev_mask)
其中又调用了一个device函数来计算两个bbox的重叠率:
__device__ inline float devIoU(float const * const a, float const * const b)
CUDA的global函数(__global__)是运行在设备端(即GPU端),可以通过<<<...>>>语法从宿主端调用的函数,例如在nms_cuda函数中调用nms_kernel;device函数(__device__)是运行在设备端,只能被其他device函数或global函数调用的函数,例如在nms_kernel函数中调用devIoU。global函数一般被称为“kernel”,是并行化后的单个计算单元,在其内部可以通过blockIdx,threadIdx等来获取当前的kernel在整个计算任务当中所处的位置。其实可以理解为kernel是一个2层或多层for循环最里层的循环体,而blockIdx,threadIdx就是那几层for循环的索引变量。
这188*188个block可以看成是一个对称矩阵,矩阵元素(i, j)和(j, i)都表示第i个bbox和第j个bbox之间的重叠率。所以这种计算方式其实浪费了很多的空间和时间。
RPN误差的计算
前面得到的尺寸为[4, 18, 38, 50]的张量rpn_cls_score被传入_AnchorTargetLayer,用于计算RPN网络的误差。在_AnchorTargetLayer当中,用了和_ProposalLayer相同的方法以网格的形式产生了17100个bbox。然后抛弃掉范围超出38×50的feature map的bbox。
比方说现在还剩下5944个落在feature map范围内的有效bbox。调用lib.model.rpn.bbox_transform.bbox_overlaps_batch()函数计算每个bbox与ground truth的重叠率。在这个过程中,如果bbox和某一类的ground truth bbox的重叠率大于0.7,则把标签的预测值标为1(表示前景);如果重叠率小于0.3,则标签预测值标为0(表示背景)。所有的bbox处理完之后,如果标为1的bbox数量超过了128,就随机选出一些bbox,将其对应标签改为-1(表示既不是前景,也不是背景);同样地,如果标为-1的bbox多于128个,也随机地将一部分对应标签改为-1。这样,就保证了现在的5944个bbox的类别预测值当中,刚好有128个前景和128个背景,其余的bbox则全部为-1。
然后,调用lib.model.rpn.bbox_transform.bbox_transform_batch()函数把ground truth bbox映射到与RPN网络预测值相同的格式,即x, y坐标经过平移,长度和宽度经log缩放。
这样,我们就得到了RPN网络的预测bbox类别标签和坐标,以及真实bbox的类标签和坐标。由于类标签是离散值(-1, 0, 1),坐标值是连续值,类标签的预测用交叉熵(cross entropy)作为误差函数按照分类问题进行优化,坐标值用smooth L1误差函数按照回归问题进行优化。cross entropy的输入是重叠率最高的4×(128+128)个bbox(目的在于人为地调整正负样本的比例,避免大量的-1和0类别影响RPN网络对前景目标的识别正确率),而smooth L1的输入是所有的bbox坐标。
smooth L1误差定义如下所示:

代码中还手动设置了两组参数rpn_bbox_inside_ws和rpn_bbox_outside_ws来调整公式中x的系数。但这里两组系数是相同的,都是均匀地初始化。
第二次bbox筛选
在前面的步骤里,RPN网络根据预先定义好的9种anchor以网格的形式产生了17100个bbox(假设输入图像大小是600×800),然后用NMS做初步筛选,保留了2000个bbox,这2000个bbox被保存在张量rois当中,传递给_ProposalTargetLayer,做进一步的筛选。
在_ProposalTargetLayer当中,关键在于lib.model.rpn.proposal_target_layer_cascade._ProposalTargetLayer._sample_rois_pytorch函数。在这个函数里,所有的候选bbox会与每个ground truth bbox计算重叠率,重叠率大于等于0.5的bbox认为是前景,并且把其对应的类别预测值标记为重叠率最高的那个类。如果一幅图像最终得到的前景bbox多于32个,则随机抛弃一些bbox,只保留32个前景bbox。同时,与ground truth bbox重叠率小于0.5的认为是背景,被保留的背景bbox数量要保证每幅图像产生的前景+背景bbox的总数是128。
这128个bbox的坐标也会经过类似于RPN网络当中的过程进行变换,以便于回归优化。
ROI Align
ROI Pooling的作用是把前面得到的4×128个尺寸不一的bbox(假设batch size为4)归一化到同样的大小,便于后面的conv层继续处理。
与ROI Pooling相比,ROI Align对于feature map无法被目标尺寸整除时,有明显的优势。原因在于ROI Align会用双线性内插的方法在不规则大小的feature map当中寻找极值。
ROI Align也是可以并行化的。所以代码中ROI Align也是用CUDA来实现的。这里默认为ROI Align的输出张量维度为[512, 1024, 7, 7],其中1024来自于ResNet第3组residual block的输出,512刚等于4×128,可以一次性处理完4幅输入图像的128个预测bbox。输出张量的第一个维度512也说明了从ROI Align这里开始即把每个预测bbox当作一个单独的样本来对待。
Python的ROI Align API定义在lib.model.roi_layers.roi_align当中,然后指向了C++扩展_C.roi_align_forward和_C.roi_align_backward(分别为正向计算和反向求导),对应的C++头文件为lib/model/csrc/ROIAlign.h。
以前向计算为例,在CUDA可用时,函数的实现位于lib/model/csrc/cuda/ROIAlign_cuda.cu:
at::Tensor ROIAlign_forward_cuda(const at::Tensor& input,
const at::Tensor& rois,
const float spatial_scale,
const int pooled_height,
const int pooled_width,
const int sampling_ratio)
这里依然是传入了at::Tensor,并创建了一个大小为4096的grid(理想情况下可以建立一个大小为1024×7×7的grid,使得每个block对应输出张量的一个元素),每个grid包含512个thread,对应于输出张量的样本维度。
同样地,这里用<<<...>>>的方式调用global函数RoIAlignForward:
template
__global__ void RoIAlignForward(const int nthreads, const T* bottom_data,
const T spatial_scale, const int channels,
const int height, const int width,
const int pooled_height, const int pooled_width,
const int sampling_ratio,
const T* bottom_rois, T* top_data)
这里的模板类类型T被设置为float,这样就可以计算次像素(sub-pixel)级的坐标了。比如,在一个2×2的方格内,取(0.5, 0.5), (0.5, 1.5), (1.5, 0.5), (1.5, 1.5)四个点来进行双线性内插,得到局部极大的像素值。
内插函数定义在一个device函数bilinear_interpolate中:
template
__device__ T bilinear_interpolate(const T* bottom_data,
const int height, const int width,
T y, T x,
const int index /* index for debug only*/)
bbox的最终分类
由ROI Align产生的[512, 1024, 7, 7]张量被传入ResNet的第4组residual block,得到一个维度为[512, 2048]的张量。注意,这些residual block中的bn层没有参与训练,但conv层是参与新样本训练的。
这个大小为[512, 2048]的张量经过RCNN_bbox_pred层(是一个linear层)产生一个[512, 4]张量,表示对4×128个bbox的坐标预测值bbox_pred。
同时,[512, 2048]的张量也会经过RCNN_cls_score层(也是一个linear层)产生一个[512, 21]张量,表示对4×128个bbox的类别预测值(20个正类+1个负类)cls_score。
然后,cls_score由交叉熵误差函数计算分类误差RCNN_loss_cls,bbox_pred由smooth L1误差函数计算坐标回归误差RCNN_loss_bbox。
最后,RPN的两组误差和此处产生的两组误差加在一起,构成模型的最终误差:
loss = rpn_loss_cls.mean() + rpn_loss_box.mean() \
+ RCNN_loss_cls.mean() + RCNN_loss_bbox.mean()
模型的训练
原始repo的README并没有给出所有训练网络所需的准备工作,这里进行一些补充。
安装COCO API
需要最少修改的方法是把COCO API安装在代码目录下的data文件夹里:
cd data && git clone https://github.com/cocodataset/cocoapi.git && cd cocoapi/PythonAPI && make
额外的COCO样本子集
训练脚本
修改好lib/model/faster_rcnn/resnet.py文件中的self.model_path与lib/model/utils/config.py文件中的__C.DATA_DIR之后,用下面的命令编译CUDA代码(别忘了安装requirements.txt里面列出来的依赖包):
cd lib
python setup.py build develop
用下面的命令开始训练:
python trainval_net.py --dataset pascal_voc --net res101 --bs 4 --nw 8 --lr 4e-3 --lr_decay_step 8 --epochs 10 --cuda
在RTX 2080Ti上,训练PASCAL VOC 2007大约耗时130分钟,显存占用约为9309MB,内存占用约为2709MB。
模型的预测
用以下命令用测试集验证模型的性能:
python test_net.py --dataset pascal_voc --net res101 --checksession 1 --checkepoch 10 --checkpoint 2504 --cuda --load_dir models
mAP=0.7573
总结
总结起来,Faster-RCNN的过程是:提前定义好9种anchor,RPN网络根据这9种anchor以网格的形式产生大量的bbox,然后用NMS做初步筛选,保留2000个bbox。在筛选2000个bbox的过程中,没有用到ground truth信息,只是利用了RPN网络给出的bbox属于前景/背景的预测值。但是计算RPN网络的误差时用到了ground truth,其中bbox的类别是用分类方法优化的,坐标值是用回归方法优化的。然后从这2000个bbox里根据与ground truth的匹配程度再做一次筛选,产生128个bbox,再计算这些bbox的具体分类误差(如果训练集包含20类,则需要预测21个类别,多加的那一类表示背景类)和坐标误差,并分别用分类和回归方法进行优化。
把这篇文章分享给你的朋友: