刘二大人 《PyTorch深度学习实践》第3讲 梯度下降算法
指路 ☞《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
知识补充:
1、预设一个w值,然后算斜率(梯度),如果梯度大于0,我们要往梯度小的方向进行,即减去它,反之一样。α是学习率,此处设为0.01
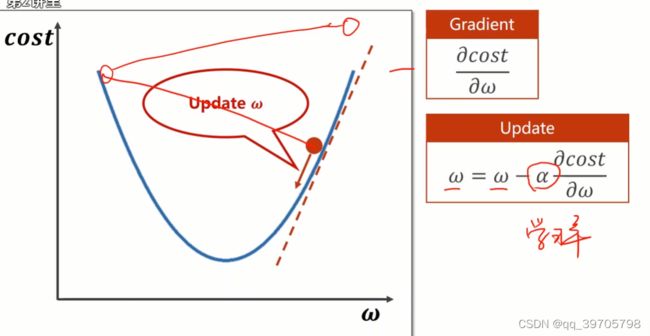
2、梯度下降法只能算出局部最优,没办法得到全局最优
3、鞍点,梯度为0
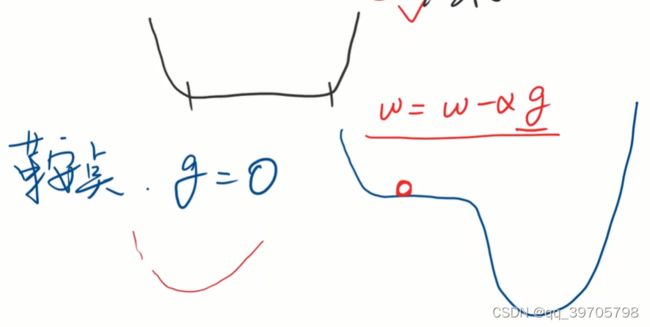
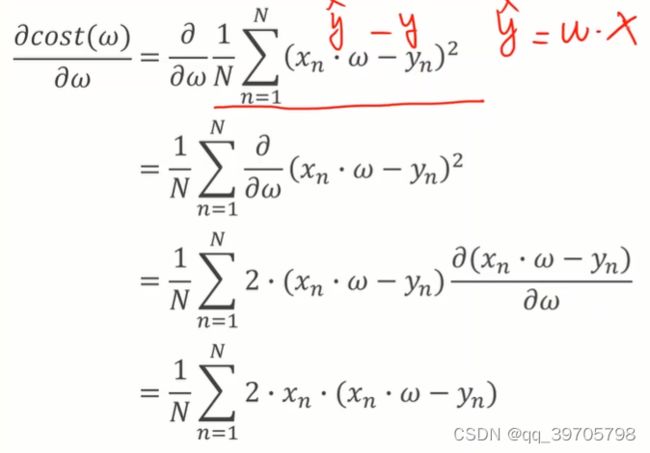
4、如果cost随epoch曲线上升了,原因可能是α取大了;加权均值可以让曲线更圆滑
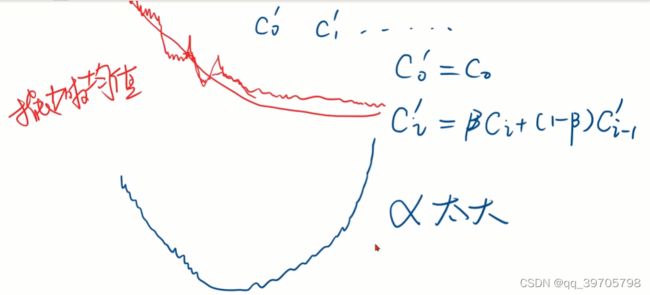
5、随机梯度下降公式
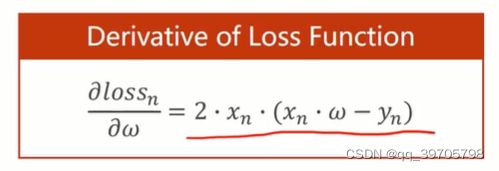
6、梯度下降与随机梯度下降之间的区别

**************************************************************************************************************
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_p = forward(x)
cost += (y_p - y)**2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad = 2 * x * (x * w - y)
grad += grad
return grad / len(xs)
print('before training', 4, forward(4))
epoch_list = []
cost_list = []
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('Epoch=', epoch, 'w={:.2f}'.format(w), 'cost={:.2f}'.format(cost_val))
epoch_list.append(epoch)
cost_list.append(cost_val)
print('after training', 4, '{:.2f}'.format(forward(4)))
plt.plot(epoch_list, cost_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.show()
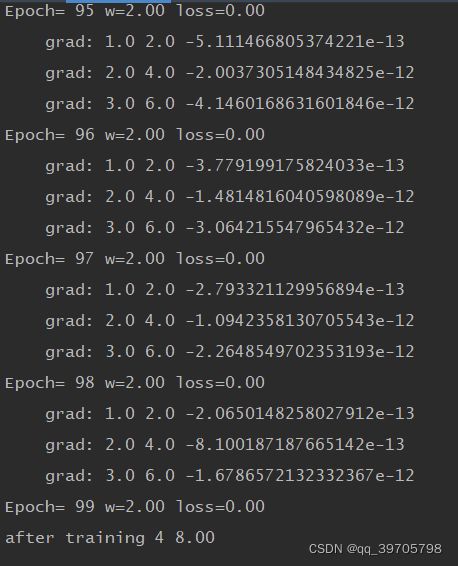
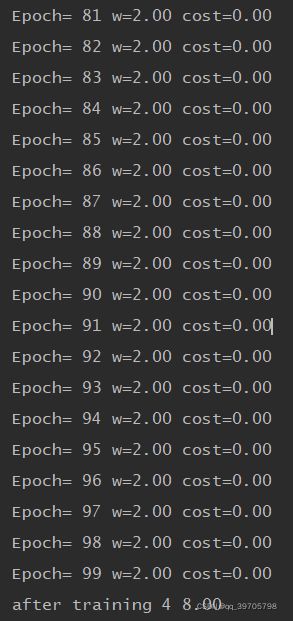
部分运行结果如下:
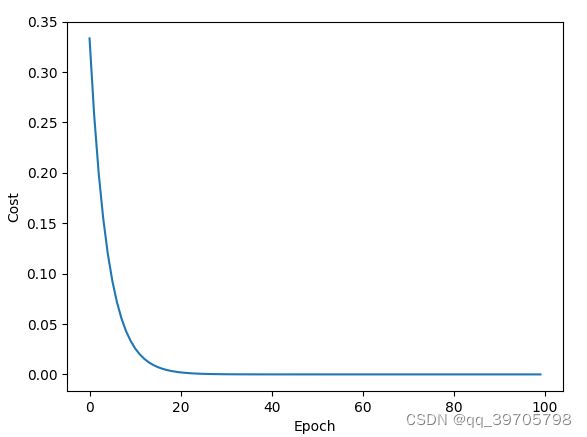
*************************************************************************************************************
更改为随机梯度下降,即将cost 改为loss
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x*w
def loss(x, y):
y_p = forward(x)
return (y_p - y)**2
def gradient(x, y):
return 2 * x * (x*w - y)
print('before training', 4, forward(4))
epoch_list = []
loss_list = []
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w -= 0.01 * grad
print('\tgrad:', x, y, grad)
l = loss(x, y)
print('Epoch=', epoch, 'w={:.2f}'.format(w), 'loss={:.2f}'.format(l))
epoch_list.append(epoch)
loss_list.append(l)
print('after training', 4, '{:.2f}'.format(forward(4)))
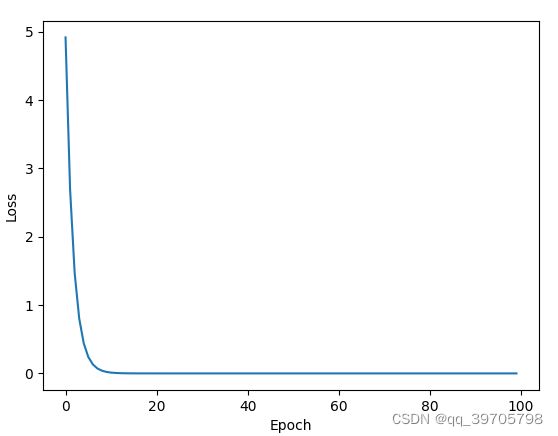
plt.plot(epoch_list, loss_list)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
部分运行结果: