GAN的demo代码注解(基于PyTorch)
参考:https://zhuanlan.zhihu.com/p/57705962
1 导入相关功能包
argparse模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后argparse将弄清如何从sys.argv解析出那些参数。argparse模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。(https://docs.python.org/zh-cn/3/library/argparse.html)。具体用法在代码块2。- os:在python环境下对文件,文件夹执行操作的一个模块(https://docs.python.org/zh-cn/3/library/os.html?highlight=os#)
- numpy:NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。(https://www.runoob.com/numpy/numpy-tutorial.html)
- torchvision.transforms:包含了常见的图像变化(预处理)操作。
- torchvision.utils:里面有make_grid和save_image,后者将输入的Tensor保存为image file
- torchvision.datasets是继承torch.utils.data.Dataset的子类,可以使torch.utils.data.DataLoader对它们进行多线程处理(https://blog.csdn.net/tsq292978891/article/details/79403617)
import argparse
# argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后 argparse 将弄清如何从 sys.argv 解析出那些参数。
import os
# 在python环境下对文件,文件夹执行操作的一个模块
import numpy as np
import math
import torchvision.transforms as transforms
# pytorch中的图像预处理包,包含了很多种对图像数据进行变换的函数
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch2 参数定义
一个比较容易混的点:
- iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数;
- batch-size:1次迭代所使用的样本量;
- epoch:1个epoch表示过了1遍训练集中的所有样本。
os.makedirs("images", exist_ok=True)
'''
makedirs()方法是递归目录创建功能。如果exists_ok为False(默认值),
则如果目标目录已存在,则引发OSError错误,True则不会
'''
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=100, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=128, help="size of the batches")
'''
iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数;
batch-size:1次迭代所使用的样本量;
epoch:1个epoch表示过了1遍训练集中的所有样本。
'''
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate") # 学习率
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient") # 梯度下降方法?
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space") # 隐空间的维度
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
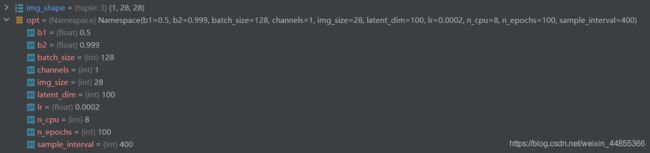
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
# 默认:通道数=1,图片大小=28*28
# 这些参数opt.channels, opt.img_size, opt.img_size便是需要去上一部分设定的参数的位置去找的,都是带有opt. 意思为图像的通道数为1,尺寸大小为28*28,通道数为1表示是灰度图。
cuda = True if torch.cuda.is_available() else False
# 使用GPU的语句,有GPU就可以使用GPU运算可以得到opt初始参数值如下所示:
3 搭建生成器网络和判别器网络
定义自已的网络:
- 需要继承nn.Module类,并实现forward方法。一般把网络中具有可学习参数的层放在构造函数__init__()中,不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
- 只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用if,for,print,log等python语法.
- 每一层的输出作为下一层的输入,这种前馈nn可以不用每一层都重复的写forward()函数,通过Sequential()和ModuleList(),可以自动实现forward。这两个函数都是特殊module, 包含子module。ModuleList可以当成list用,但是不能直接传入输入。
注:Pytorch基于nn.Module构建的模型中,只支持mini-batch的Variable输入方式,比如,只有一张输入图片,也需要变成 N x C x H x W 的形式。
'''
这一部分代码是搭建生成器神经网络,对于小白就当成一个套路来做,就是每次搭建网络都这样写,
只是改变一下*block里面的数字和激活函数来测试就行,等一段时间学懂了在自己变换神经元的层数和神经层。
至于forward中的z是在程序后面的定义的高斯噪声信号,形状为64*100,所以如果你非要问img.size(0)的话,
它为64,也就是一批次训练的数目。
'''
class Generator(nn.Module): # 生成网络
def __init__(self):
super(Generator, self).__init__() # 超类继承
def block(in_feat, out_feat, normalize=True): # 对传入数据应用线性转换(输入节点数,输出节点数)
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) # 批规范化
layers.append(nn.LeakyReLU(0.2, inplace=True)) # 激活函数
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
) # 快速搭建网络, np.prod 用来计算所有元素的乘积
def forward(self, z): # 前向传播 z代表输入
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img'''
这段定义了一个判别网络,也可以是先拿一个套路来看
'''
class Discriminator(nn.Module): # 判别网络
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity4 定义损失函数、选择优化器和MINST数据集下载
- DataLoader接口的应用
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。
# 定义了一个损失函数nn.BCELoss(),输入(X,Y), X 需要经过sigmoid, Y元素的值只能是0或1的float值,依据这个损失函数来计算损失。
# Loss function
adversarial_loss = torch.nn.BCELoss()
# 初始化生成器和判别器
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
# 给有英伟达显卡的电脑使用GPU加速运算的代码
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# 创建多级目录(刚开始介绍过),用来储存mnist的数据资料,这个网络也是用mnist数据集训练的
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
# DataLoader接口的应用
'''
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,
只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有
的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该
接口有点承上启下的作用,比较重要。
'''
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
# 其作用就是先将输入归一化到(0,1),再使用公式”(x-mean)/std”,将每个元素分布到(-1,1)
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# 定义了神经网络的优化器,Adam就是一种优化器
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor5 开始训练
# **********************************************************************************************************
# 开始训练
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs): # 训练的次数就是opt.n_epochs,epoch:1个epoch表示过了1遍训练集中的所有样本。
for i, (imgs, _) in enumerate(dataloader):
'''
dataloader中的数据是一张图片对应一个标签,所以imgs对应的是图片,_对应的是标签,而i是enumerate输出的功能,
enumerate用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用
在 for 循环当中,所以i就是相当于1,2,3…..的数据下标。
'''
# Adversarial ground truths
# vaild可以想象成是64行1列的向量,就是为了在后面计算损失时,和1比较;fake也是一样是全为0的向量,用法和1的用法相同
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
# 将真实的图片转化为神经网络可以处理的变量
real_imgs = Variable(imgs.type(Tensor))
'''
训练生成网络
'''
# -----------------
# Train Generator
# -----------------
# 在每次的训练之前都将上一次的梯度置为零,以避免上一次的梯度的干扰
optimizer_G.zero_grad()
# Sample noise as generator input
# 输入从0到1之间,形状为imgs.shape[0], opt.latent_dim的随机高斯数据。
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
# 开始得到一个批次的图片,上面说了这些数据是分批进行训练,每一批是64张,所以,这这一批图片为64张。
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
# 计算生成器的损失
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
# 进行反向传播和模型更新
g_loss.backward()
optimizer_G.step()
'''
训练判别网络
'''
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# 在每次的训练之前都将上一次的梯度置为零,以避免上一次的梯度的干扰
# Measure discriminator's ability to classify real from generated samples
# 衡量判别器分类能力(论文公式)
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# 进行反向传播和模型更新
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
训练结果如下:
- iteration:表示1次迭代(也叫training step),每次迭代更新1次网络结构的参数;
- batch-size:1次迭代所使用的样本量;因此一共有469个样本集要训练。
- epoch:1个epoch表示过了1遍训练集中的所有样本。100次。