最新综述!自动驾驶中Camera/Lidar/Radar如何识别异常目标和场景(CVPRW2022)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
后台回复【数据集下载】获取计算机视觉近30种数据集!
论文链接:https://arxiv.org/pdf/2204.07974.pdf
1摘要
现如今,自动驾驶汽车的感知在封闭路况下表现良好,但是仍然难以应对意外情况。本文对基于Camera、LiDAR、Radar、多模态和抽象目标级数据的异常检测技术展开全面调研。本文系统化地分析了包括检测方法、极端案例(corner case)的级别、在线应用程序的能力以及其他属性等方面。
本文从五个角度展开调研,即:重建、预测、生成式、置信度和特征提取。置信度方法一般由后处理得到,并不会影响模型的训练,可以进一步细分为贝叶斯方法、可学习得分和通过后处理获得的得分。重建方法尝试重建常态并将任何形式的偏离视为异常。生成式方法和重建方法类似,但也考虑了判别器的决策或与训练数据分布的差距。特征提取可以基于手工或者学习得到的特征来确定类标签或比较各种特征级别的模态。基于预测的方法预测正常情况下的下一帧实现异常检测,概览如下图所示。

2Anomaly Detection on Camera Data
自动驾驶汽车通常配备不同的摄像头系统,如双目、单目和鱼眼摄像头,以确保对环境充分的感知。因此,基于相机的异常检测对于更高层次的视觉感知有巨大潜力。在本节中,本文在Fishyscapes (FS) 基准 [31]上引入另外两个标准:辅助数据和再训练。前者表示算法在训练期间是否需要异常数据。再训练特指算法是否不能使用预训练模型,但需要特殊的损失函数或者再训练,因为这可能会降低性能[31]。所有基于相机的方法都在下图中。

置信度:基于置信度分数的方法构成了基于CNN中不确定性估计的异常检测的基线。早期的工作Bayesian SegNet [51]通过Monte Carlo dropout采样推导出语义分割网络SegNet的不确定性,其中越高的类间方差表示越高的不确定性。不确定性可以理解为像素级的异常分数,用来检测道路上的障碍物[69,89]。Jung 等人提出了一种类似的方法来检测道路上的未知障碍物[48]。其获得了分割网络中类条件下的标准化max logits。动机是[48]发现max logits对于不同的预测类别有各自的范围。这意味着可以从训练样本中确定平均值和标准偏差。因此,标准化可以归类为可学习的置信度分数方法。[28] 提出了通用学习框架虚拟异常值合成(Virtual Outlier Synthesis,VOS),其通过合成虚拟异常值来对比地塑造神经网络的决策边界。
重建:重建和生成式的方法主要用于对目标级的异常检测,即模型在没有任何异常目标辅助数据的情况下学习重现训练数据的正态性。[89]提出重建模块JSR-Net,以基于像素分数检测道路异常。其通过将已知类别的信息整合到异常分数中来增强语义分割网络。Ohgushi [69]尝试了类似的方法,在有真实和合成道路障碍物的高速公路数据集上进行实验。其将语义分割的entropy loss同真实图像和重建图像之间的感知损失相结合,生成异常图。随后进行一系列后处理操作,最终的障碍物预测结果由语义信息、异常图和用于细化局部区域的超像素共同得到。
生成式:根据FS、LaF和Segment Me If You Can (SMIYC) 障碍物跟踪基准,基于密集异常检测的算法NFlowJS [35]大幅超越了前人工作,代表了当前基于相机的异常检测的最新技术。NFlowJS使用联合训练以在常规图像上生成具有归一化流(NF)的合成异常图像,同时基于这些合成的混合图像训练密集预测网络。合成的异常图像被定义为异常Mask,在训练期间,判别模型用于区分合成异常图像和常规图像。[68]采用并增强了Lee等人的生成式方法[54]用于异常物体检测。[68]提出了一种辅助生成式对抗网络(GAN),其鼓励目标分类器区分训练分布之外的样本。[60]提出了一种检测域偏移的方法。自编码器以自监督的方式学习训练集特定的域,该方法通过自编码器的峰值信噪比(PSNR)的分布来表征训练数据域。在推理过程中,域失配 (domain mismatch,DM) 通过比较学习得到的PSNR和输入的PSNR分布来判断是否异常。
特征提取:Bolte[10]等人提出了另一种域偏移检测,其通过比较特征图的均方误差(MSE)实验异常检测。类似,[101]提出了DeepRoad框架,其使用VGG特征的分布距离来验证输入图像是否正常。
总结来说,先前的许多工作没有使用额外数据,但需要对提出的扩展模块或整个检测框架重新训练才能实现异常检测。
3Anomaly Detection on Lidar Data
大多数情况下,自动驾驶并非仅依赖摄像头,尽管相机的分辨率最高,但却缺少深度信息。因此,LiDAR也是常用的传感器。虽然有很多关于像素级LiDAR局部去噪的研究[3,74],但本文聚焦于目标级和域级的异常检测,其中整个点云簇或外观的大且恒定的变化被认为是异常。尤其是雨、雪、霭等天气条件严重影响数据质量。所有基于LiDAR的方法见下图。

置信度:张[100]等人的研究表明降雨会影响LiDAR的测量质量,因为由此产生的点云更稀疏、更嘈杂,且平均强度更低。因此,[100]的目标是使用深度半监督异常检测(DeepSAD)算法[77]来量化激光雷达的退化程度。其首先将3D LiDAR数据投影到2D强度图像中,然后DeepSAD提取图像特征,其中所有正常图像(没有下雨)落入超球体中,所有异常图像(下雨图像)都映射到远离超球体中心的位置。即通过超球面学习来区分正常和异常的数据。尽管该方法是针对雨天和正常天气的,但原理上也可以扩展至其他天气。
过去,已经有如VoxelNet [102]、PointRCNN [82]和PointNet++ [73]等点云检测算法。但是这些算法都是基于闭集训练的。相比之下,开集检测算法能够检测闭集之外的目标,将其作为未知目标输出。Wong 等人[94]最先提出了用于3D点云的开集检测算法,其提出一个开集实例分割网络(OSIS),该网络学习一个与类别无关的嵌入,以将点聚类到实例中,并不考虑类别。推理基于鸟瞰 (BEV) 激光雷达框架,包括两个阶段:闭集和开集感知。闭集感知就是常规的检测阶段,开集感知是OSIS 的核心,学习与类别无关的嵌入空间。通过开集感知就可以进行异常检测。
重建:Masuda等[65]提出了一种检测目标点云是否异常的方法。与前面的方法相比,该技术针对单个封闭目标的点云。由于车载激光雷达提供整个环境的点云信息,因此需要首先通过检测或聚类方法获取单个目标的RoI。所提出的VAE基于FoldingNet 解码器[98],并学习重建被认为是正常的一组已知目标。然后基于重建信息和Chamfer距离得到异常分数,进而得到点云异常的目标。
总结来说,在研究了各种闭集检测结构的基础上,LiDAR中目标级别的异常检测方兴未艾。
4Anomaly Detection on Radar Data
Radar是自动驾驶中常用的第三种传感器。与LiDAR相比,它以较低的分辨率和稀疏的空间信息为代价获取较高的感知范围。与前两种传感器相比,Radar对不断变化的天气和白天条件适应性更强[90]。在下文中,本文专注于介绍为车载雷达系统设置的异常检测算法,如环绕、远程和短程雷达,并排除基于超宽带和穿墙雷达的算法。所有基于Radar的方法见下表。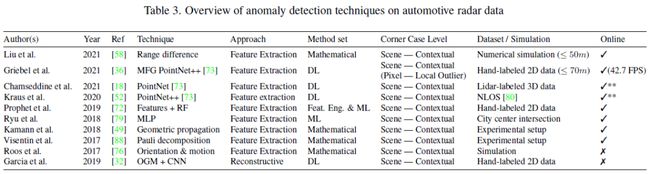
Radar通过测量电磁多径波的飞行时间及其反射来估计物体的位置。由于多径传播,Radar甚至可以检测到被遮挡的物体[86],同时也会导致噪声、反射和伪影。特别是如高速公路上的栏杆或者光滑的墙壁这种反射表面,会产生不存在的伪影,通常被称为“幽灵目标”(ghost target)[18,79,90]。这些是影响车载Radar的长期挑战[58],出于这个原因,由于本文关注像素级以上的异常感知,因此特别关注检测幽灵目标的方法。
特征提取:Liu 等[58] 提出了一种多路径传播模型,基于栏杆的反射,并根据目标的距离差来识别和去除鬼影。虽然这种数学方法在模拟中简单有效,但必须考虑其约束条件,因为它仅限于具有三个固定大小车道的类似高速公路的驾驶场景。并且,目标与栏杆间的距离仅取三个值,并不能模拟真实车辆的变道。此外,还有一些类似的工作[43, 49, 88, 76]。
最新的机器学习算法用于检测更多驾驶场景中的雷达异常,而不受上述数学模型的限制。这种算法将幽灵目标都定义为一个单独的类。例如,Griebel 等[36] 利用 PointNet++ 实现了一种深度学习算法,首先使用多尺度分组层(multi-scale grouping,MSG)来提取点云中不同尺度的特征。此外,该算法不仅关注多路径异常检测,还关注由多普勒速度模糊或朝向估计错误引起的其他单目标异常。
重建:Garcia等[32]使用占用网格和移动检测图组成的双通道图像作为全卷积网络的(FCN)的输入。所提出的算法包含编码器和解码器两个部分。前者将语义信息提取为较低分辨率的表示,而后者则重建空间信息并将提取的特征表示映射回原图大小。预测结果中,移动的目标被认为是幽灵目标。该方法在50张图像的测试机上准确率达到92%。
总结来说,许多方法假设幽灵目标和真实目标可以通过它们的特征区别来区分,而不是传统的,即重建或基于置信度的方法。尽管如此,未来的工作可以考虑时间信息来进一步优化。
5Anomaly Detection on Multimodal Data
既然汽车配备了多种传感器,多模态的方法自然也是其中之一,下表列出了所有异常检测中的所有多模态方法。

特征提取:继之前在雷达数据中检测幽灵目标后,Wang等[90]提出一种多模态算法,Transformer非常适合 3D 点云,因其注意力机制是置换不变的,这对传统CNN来说很困难。此外,与前面提到的PointNet++等架构相比,Transformer显式地对点的交互进行建模。作者采用多模态Transformer网络通过参考LiDAR来检测Radar幽灵目标。Radar点云相比于LiDAR稀疏的多,这阻碍了两种数据的匹配。因此,单个Radar点通过KNN查询周围的LiDAR点并提供局部特征信息,就像放大镜一样。进一步对非结构化的雷达数据本身使用self-attentation来识别幽灵目标。值得一提的是,幽灵目标的GT是通过比较Radar和LiDAR数据生成的。
Sun等[85]提出一种基于RGB-D数据的语义分割实时融合网络。多模态的方式是通过结合深度信息来改进图像分割。此外,他们认为多源分割框架还能够检测道路障碍,提供统一的像素级场景理解。另一种基于RGB-D的道路障碍物检测算法是MergeNet[37]。
Ji等[46]提出一种有监督的VAE来合并不同维度的多模态数据。这对于融合密集的激光雷达数据和较低分辨率的雷达数据特别有用。[46]在训练后放弃解码器,并使用学习到的编码器作为特征提取器。然后,模态的潜在表示与其他编码模态一起输入到全连接层中,以识别车辆的异常操作模式。虽然这个方法是为机器人设计的,但原理上可以扩展到自动驾驶中。
总之,所有多模态异常检测技术都是基于多个模态提取特征的比较。本文认为多模态检测可以互相促进,因为多模态扩大了潜在异常的搜索空间,同时降低了误报的风险。
6Anomaly Detection on Abstract Object Data
前面概述了适用于特定传感器的异常检测方法。下面侧重于更抽象级别的模式分析,即检测场景中的异常行为,并非与传感器绑定。因此,这些方法旨在检测场景级别的异常[13]并处理自车外的危险和异常驾驶行为。所有基于抽象目标的方法见下表。

预测结果:Yang[97]基于隐马尔科夫模型(HMM)评估驾驶车辆的行为以检测异常情况。马尔科夫模型的观察状态由Conditional Monte Carlo Dense Occupancy Tracker (CMCDOT)算法[78]提供,包括速度以及车辆位置。该框架基于点云和里程计数据得出这些观察结果。因此,这种范式可以可靠的推断出模拟多车道高速公路场景中的危险和异常驾驶行为,其中包含了两辆自车之外的车辆。
Bolte等[9]提出了场景级别的异常检测,其在一系列传感器数据(即相机图像)上观察到的模式。他们考虑了下述场景:异常、新颖和有风险的场景[13]。由于场景异常的性质,它们量化了移动物体(如行人/车辆)的异常行为。真实帧和预测帧间的误差当做异常评分。预测帧基于先前输入帧序列由对抗自编码器生成。因此,异常评分也可以解释为模型的不可预测性。该模型使用MSE、PSNR和结构相似性指数测量(SSIM)指标进行评估,异常场景由阈值确定。
重建:Stocco等[84]提出SelfOracle用于检测关乎安全的不当行为,如碰撞和越界。该框架使用VAE重建当前场景的一组由先前输入图像并计算对应的重建误差。在对正常数据进行训练期间,该模型通过最大似然估计将概率分布拟合到观察到的重建误差上。然后可以只用估计的分布来确定阈值以区分异常行为和正常行为。
最后,目标级别的异常检测在很大程度上取决于人为的驾驶行为。因此,随着道路上的自动驾驶汽车的兴起,自动驾驶在行为预测上可能会出现较大的概念漂移。
7总结
本文对自动驾驶领域的异常检测方法进行了广泛的调查。最近大多数方法都与基于图像的异常检测有关,而基于LiDAR和Radar的方法受到的关注较少。原因之一是缺少基准数据集,到目前为止,公开数据集都只有相机数据。公开的异常行为检测数据集还比较少,这使得检测技术的统一比较变得困难。由前文可知,每种模式可能只适合检测一种或几种corner case,例如LiDAR更关注单点异常。总而言之,异常检测还有很长的路要走。
8参考
[1] Anomaly Detection in Autonomous Driving: A Survey
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
