Channel-wise Knowledge Distillation for Dense Prediction阅读笔记
Channel-wise KD阅读笔记
-
- (一) Title
- (二) Summary
- (三) Research Object
- (四) Problem Statement
- (五) Method
-
- 5.1 spatial distillation
- 5.2 Channel-wise Distillation
- (六) Experiments
-
- 6.1 实验设置
- 6.2 和最近knowledge Distillation方法相比
- 6.3 消融实验
- 6.4 目标检测任务
- (七) Conclusion
- (八) Notes
-
- 8.1 Dense Prediction任务中KD之前的工作
(一) Title

论文地址:https://arxiv.org/abs/2011.13256
代码地址:https://github.com/irfanICMLL/TorchDistiller/tree/main/SemSeg-distill
前言:本文的主要工作集中在5.2小节,思路简单并且比较novel
(二) Summary
背景工作:
大量的Knowledge distillation(KD)工作集中在空间域上处理教师网络和学生网络的激活图,具体的做法是将activation values经过normalization之后再最小化point-wise和/或pair-wise的差异。
本文工作:
本文的工作在每一个channel上normalization激活图特征值,从而得到一个soft probability map,通过最小化教师网络和学生网络之间channel-wise probability map的Kullback-Leibler(KL) divergence来实现蒸馏,实现对特征图上突出部分提高注意力。
实验结果:
在目标检测任务中帮助RetinaNet detector(ResNet50)的mAP提升了3.4%,在semantic segmentation任务中帮助mIoU提升了5.81%。
本文贡献:
- 不同于现有的spatial distillation approaches,本文提出的是一种channel-wise distillation,并且是比较简单的.
- 在目标检测任务以及semantic segmentation任务中,取得了超越state-of-the-art KD方法的成绩,并且方法是通用的。
(三) Research Object
本文通过改进前人工作中存在的过于严格的约束,以及不同空间位置在知识transfer过程中等价的问题,提出了一个基于Kullback-Leibler(KL) divergence的方法.
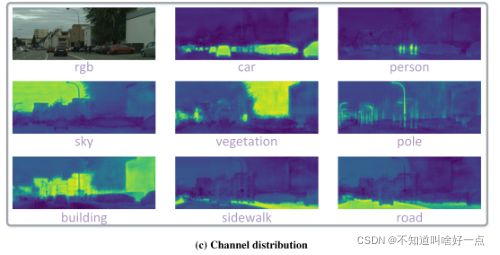
首先,对于特征图的每一个通道进行normalization,最小化经过norm的特征图之间的非对称KL divergence,也就是将每一个channel转换成一个分布,利用分布之间的约束来进行蒸馏,这种对通道进行norm的方式能够凸显需要关注的部分,如下图所示:
通过这种方式处理activation能够更突出significant的激活值,这里一定会有激活值大的地方在知识transfer中得到的关注更多嘛?怎么去看待这个"关注"?第二个问题,一个训练好的网络的激活图norm之后表现情况是上面嘛?尤其是检测任务。
(四) Problem Statement
目前现有的知识蒸馏主要集中在分类任务上,本文希望解决dense prediction下的KD问题,然而简单的pixel-wise的方式并不能够很好的解决当前的问题,本文怎么考虑整个activation feature map中不同spatial position之间的差异以及如何施加不严苛的约束来实现对dense prediction的蒸馏呢?
(五) Method
5.1 spatial distillation
现有的空间蒸馏方式如下式所示:
ℓ ( y , y S ) + α ⋅ φ ( ϕ ( y T ) , ϕ ( y S ) ) \ell\left(y, y^{S}\right)+\alpha \cdot \varphi\left(\phi\left(y^{T}\right), \phi\left(y^{S}\right)\right) ℓ(y,yS)+α⋅φ(ϕ(yT),ϕ(yS))
上式中 ℓ ( . ) \ell\left(.\right) ℓ(.)表示当前的任务损失,其中 y y y表示Ground-Truth的标签,然后 y S y^S yS和 y T y^T yT分别表示学生网络和教师网络activations的logits或者inner。 α \alpha α表示平衡损失项的超参数,这里的疑问是 φ \varphi φ和 ϕ \phi ϕ表示的是什么?我认为这两个函数表示应该是教师网络和学生网络之间activation损失的计算,以本文为例,这里的 ϕ \phi ϕ可以表示channel-wise normalization, φ \varphi φ表示Kullback-Leibler divergence function
现有spatial distillation方法的简要概述如下:
- Attention Transfer(AT)[42]中通过使用attention mak来squeeze the feature map into a single channel for distillation。
- pixel-wise loss[17]采用point-wise class probabilities
- loss affinity[35]通过计算center pixel和它8邻域之间的距离来进行蒸馏
- pairwise affinity[25,14,24]用来transfer pixel pairs之间的相似性,
- holistic loss[25,24]通过adversarial scheme来align high-order relations between feature maps from two networks。
这些是整理的之前的一些方法,有时间精力的话再去看看估计不太行,时间不充裕

5.2 Channel-wise Distillation
将教师网络和学生网络对应通道经过softly align activations进行蒸馏,可以将通道的activation转换成概率分布,通过概率分布之间的距离度量比如说KL divergence来度量差异,进行回归。对于分割问题来说,一个好的教师网络学习到的activation maps应该具有category=specific masks对于每一个channel而言,如下图所示:
符号表示: S S S表示学生网络, T T T表示教师网络,学生网络和教师网络的activation maps表示为 y S y^S yS以及 y T y^T yT,通道之间的蒸馏损失可以被形式化为:
φ ( ϕ ( y T ) , ϕ ( y S ) ) = φ ( ϕ ( y c T ) , ϕ ( y c S ) ) \varphi\left(\phi\left(y^{T}\right), \phi\left(y^{S}\right)\right)=\varphi\left(\phi\left(y_{c}^{T}\right), \phi\left(y_{c}^{S}\right)\right) φ(ϕ(yT),ϕ(yS))=φ(ϕ(ycT),ϕ(ycS))
其中 ϕ \phi ϕ用于将activation values转换成概率分布,表现形式如下所示:
ϕ ( y c ) = exp ( y c , i T ) ∑ i = 1 W ⋅ H exp ( y c , i T ) \phi\left(y_{c}\right)=\frac{\exp \left(\frac{y_{c, i}}{\mathcal{T}}\right)}{\sum_{i=1}^{W \cdot H} \exp \left(\frac{y_{c, i}}{\mathcal{T}}\right)} ϕ(yc)=∑i=1W⋅Hexp(Tyc,i)exp(Tyc,i)
其中 c = 1 , 2 , … , C c=1,2, \ldots, C c=1,2,…,C,表示通道的index索引, i i i表示一个特征图通道的空间位置索引, T \mathcal{T} T表示温度超参数,通过softmax normalization将不同网络尺度以及复杂度的影响消除了,这种归一化方式对于KD是有效的,如果学生网络和教师网络的channel数量不匹配,则使用 1 × 1 1\times1 1×1卷积来对学生网络通道数进行上采样, φ \varphi φ用于评估教师网络和学生网络channel分布之间的差异,这里使用的是KL 散度:
φ ( y T , y S ) = T 2 C ∑ c = 1 C ∑ i = 1 W ⋅ H ϕ ( y c , i T ) ⋅ log [ ϕ ( y c , i T ) ϕ ( y c , i S ) ] \varphi\left(y^{T}, y^{S}\right)=\frac{\mathcal{T}^{2}}{C} \sum_{c=1}^{C} \sum_{i=1}^{W \cdot H} \phi\left(y_{c, i}^{T}\right) \cdot \log \left[\frac{\phi\left(y_{c, i}^{T}\right)}{\phi\left(y_{c, i}^{S}\right)}\right] φ(yT,yS)=CT2c=1∑Ci=1∑W⋅Hϕ(yc,iT)⋅log[ϕ(yc,iS)ϕ(yc,iT)]
KL散度并不是对称形式的,从上式中可以看到,当 ϕ ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ϕ(yc,iT)很大时,则 ϕ ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ϕ(yc,iS)也应该同教师网络一样大,从而最小化KL散度,而当 ϕ ( y c , i T ) \phi\left(y_{c, i}^{T}\right) ϕ(yc,iT)很小时,KL散度pay less attention to minimize ϕ ( y c , i S ) \phi\left(y_{c, i}^{S}\right) ϕ(yc,iS),因此,学生网络能够对于前景显著区域的分布较好地学习,而对于背景区域activation的学习较小,这种不对称刚好能够帮助密集预测任务的学习。

(六) Experiments
6.1 实验设置
数据集: semantic segmentation任务采用Cityscapes,ADE20K以及Pascal VOC。object detection任务采用MS-COCO.
评价指标:semantic segmentation任务中 在single-scale setting下使用mean Intersection-over-Union(mIoU),floating-point operations per second(FLOPs),mean class Accuracy(mAcc).目标检测任务中:采用mAP,FPS以及model size作为评价指标
实现细节: 对于语义分割任务,教师网络采用PSPNet with ResNet101,学生网络采用ResNet18,MobileNetV2来验证方法的有效性。设置温度系数 T = 4 \mathcal{T}=4 T=4,损失权重对于logits map来说是 α = 3 \alpha=3 α=3,对于feature map来说是 α = 50 \alpha=50 α=50.
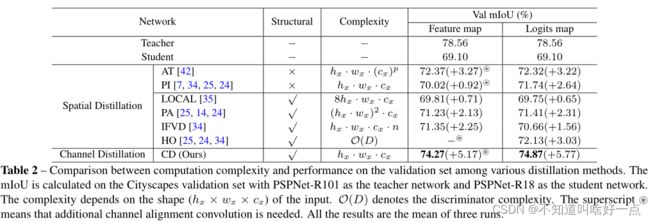
6.2 和最近knowledge Distillation方法相比
在分割任务中将本文提出的方法同其他的distillation方法进行对比,这里同时对最后的logits map以及feature map进行蒸馏.
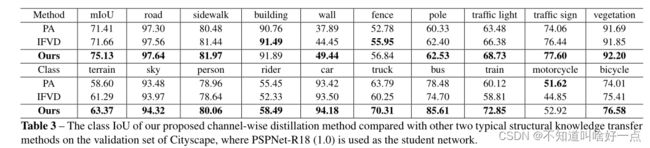
给定输入feature map(logits map),对应的尺寸为 h f × w f × c ( h s × w s × n ) h_{f} \times w_{f} \times c\left(h_{s} \times w_{s} \times n\right) hf×wf×c(hs×ws×n),其中 h f ( h s ) × w f ( w s ) h_{f}(h_{s}) \times w_{f}(w_{s}) hf(hs)×wf(ws)是feature map(logits map)的形状, c c c是channels的数量, n n n是类别的数量。并且从上图中的结果来看,channel wise distillation的工作还是相当不错的.
上图是不同类别之间的效果。
6.3 消融实验
教师模型采用PSPNet-R101,学生网络采用PSPNet-R18,实验结果在Cityscapes数据集上进行了验证。
‘PI’表示pixel-level knowledge distillation,也就是每一个空间位置对于activation进行normalize,’ L 2 L_2 L2 w/o NORM’表示直接最小化两个网络feature map之间的差异,将所有的spatial position同等看待.'Bhat’表示Bhattacharyya distance是对称的分布measurement,
不同的损失权重下温度系数的影响
语义分割任务上的对比效果
蒸馏网络师生差异越小,蒸馏性能的提升越不显著


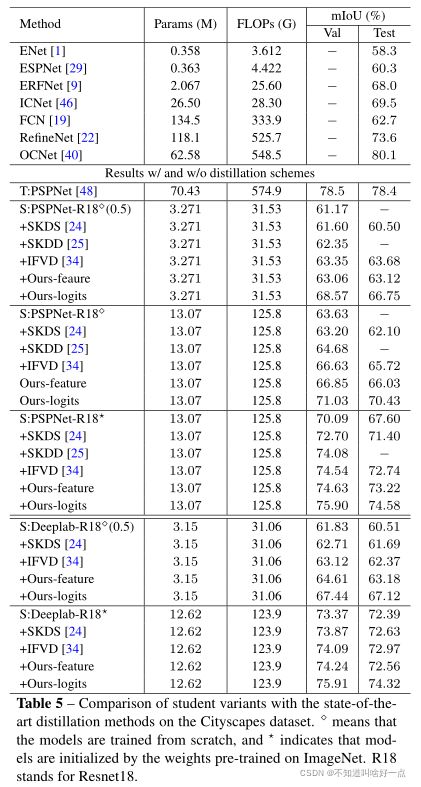
6.4 目标检测任务

(七) Conclusion
本文提出了一种基于channel-wise的用于dense prediction任务的蒸馏方法,这里将每一个通道的activations归一化为一个概率图,接着使用不对称的KL散度来最小化学生网络和教师网络之间的差异,在semantic segmentation以及object detection任务中都能够取得比当前knowledge distillation更好的性能。
(八) Notes
8.1 Dense Prediction任务中KD之前的工作
首先先明确什么是Dense Prediction?首先Dense Prediction就是per-pixel prediction问题,是相对于image-level的分类任务而言的,包括semantic segmentation以及object detection任务。
之前的KD工作是怎么处理Dense Prediction问题?
- 一种方式通过严格的对齐point-wise classification scores或者feature maps,然而过于严苛的约束,导致了sub-optimal solutions
- 另一种方式在不同空间位置上enforce the correlations[对应论文:Structured knowledge distillation for dense prediction,Structured knowledge distillation for semantic segmentation以及Inter-region affinity distillation for road marking segmentation],首先在特征图上每一个spatial location上进行normalize,接着使用aggregation a sub-set of different spatial locations通过pair-wise relations以及inter-class relations。这边没有看懂,上式工作中的问题是在知识transfer过程中每一个空间位置都是等价的,这个没有重点,不合理,
- channel distillation中将activation in each channel transfer into one aggregated scalar,从而帮助进行image-level的分类任务,但是丢失了空间的位置信息。
具体到分割任务中,
- 对应参考文献[35]提到通过构建similarity map来最小化教师网络和学生网络之间的discrepancy of segmented boundary information,将中心pixel和8邻域pixel之间的欧式距离用于knowledge transfer。
- 文献[24,25]中提出两种方式来捕捉pixels之间的结构信息,包括pixel和有discriminator捕获的整体相关性进行pair-wise similarity
- 文献[34]研究具有相同标签的像素之间的类别特征的变化,构建每个像素的特征与其对应的类内原型之间的余弦距离集,从而来传递structural knowledge。
- 文献[14]中通过feature adaptor来缓解师生网络之间特征mismatching的问题。
再具体到目标检测任务中,
- 很多文献都发现了在蒸馏过程是区分背景和前景部分是非常有必要的。MIMIC[20]中通过 L 2 L_2 L2loss来约束学生网络RPN对应的feature map的同教师网络尽可能保持一致,然而直接使用pixel-wise的损失往往会造成目标检测性能损害,对于我自己的情况来看,是损失不容易收敛。
- 文献[32]中提到对fine-grained feature near object anchor locations进行蒸馏.
- 文献[33]中生成mask 来区分前景和背景。
再到channel-wise knowledge
- 文献[50]中通过计算每一个通道activation的均值,并且assigned每一个通道不同的权重来进行加权,进行分类任务的蒸馏工作。
- CSC[26]中通过计算所有空间位置以及所有channel之间的pair-wise relations来进行蒸馏。在我看来这种方式过于强硬。
- 文献[33]中提到每一个channel中包含的信息是通用的,能够在不同的modalities之间进行共享。