【论文笔记_知识蒸馏_2022】Knowledge Distillation from A Stronger Teacher

来自一个更强的教师的知识蒸馏
摘要
不同于现有的知识提取方法侧重于基线设置,其中教师模型和培训策略不如最先进的方法强大和有竞争力,本文提出了一种称为DIST的方法,以从更强的教师中提取更好的知识。我们从经验上发现,学生和更强的老师之间的预测差异可能会相当严重。因此,KL散度预测的精确匹配将干扰训练,并使现有方法表现不佳。在本文中,我们证明了简单地保持教师和学生的预测之间的关系就足够了,并提出了一种基于相关性的损失来显式地捕捉来自教师的内在类间关系。此外,考虑到不同实例对每个类具有不同的语义相似性,我们还将这种关系匹配扩展到类内级别。我们的方法简单而实用,大量实验表明,它能很好地适应各种体系结构、模型大小和训练策略,并能在图像分类、对象检测和语义分割任务中始终达到最先进的性能。
1.介绍
…
为了理解是什么造就了更强的教师以及他们对知识发现的影响,我们系统地研究了设计和训练深度神经网络的流行策略,并表明:
1.除了扩大模型规模之外,还可以通过高级培训策略(如标签平滑和数据扩充)获得更强的教师[50]。然而,如果有一个更强的老师,学生在普通KD上的表现可能会下降,甚至比没有KD从头开始训练更糟糕,如图1所示
2.当我们将教师和学生的培训策略转换为更强的策略时,他们之间的差异往往会变得更大(见图2)。在这种情况下,通过KL散度准确恢复预测可能是具有挑战性的,并导致传统KD的失败
3.保持教师和学生之间的预测关系是充分和有效的。当将知识从老师传递给学生时,我们真正关心的是保留老师的偏好(预测的相对等级),而不是准确地恢复绝对值。教师和学生预测之间的相关性有利于放松KL散度的精确匹配并提取内在关系。
因此,在本文中,我们利用皮尔逊相关系数[32]作为一种新的匹配方式来取代KL散度。此外,除了预测向量中的类间关系之外(见图3),凭着不同实例相对于每个类具有不同相似性谱的直觉,我们还建议提取类内关系以进一步提高性能,如图3所示。具体地说,对于每一个类,我们成批地收集其相应的所有实例的预测概率,然后将这种关系从教师传递给学生。我们提出的方法(称为DIST)超级简单、高效、实用,只需要几行代码就可以实现(见附录A.1),而且训练成本几乎与传统的KD相同。因此,学生可以从与优秀教师的精确输出相匹配的负担中解放出来,但只能被适当地引导以提取那些真正有价值的关系。
在基准数据集上进行了大量实验,以验证我们在各种任务上的有效性,包括图像分类、对象检测和语义分割。实验结果表明,我们的DIST明显优于传统的知识发现和那些精心设计的最新知识发现方法。例如,在ImageNet上使用相同的基线设置,我们的DIST在ResNet-18上实现了最高的72.07%的准确率。使用更强的策略,我们的方法在最近的transformer Swin-T [26]上获得了82.3%的准确性,将KD提高了1%。

图3:我们的DIST和现有KD方法之间的差异。传统的KD逐点匹配学生(s ∈ R5)和教师(t ∈ R5)的输出;实例关系方法在特征级上操作,并且分别测量学生和教师中的实例之间的内部相关性,然后将教师的相关性传递给学生。我们的DIST主张维持学生和老师之间的类别间和类别内的关系。类间关系:教师和学生的每个实例的预测概率分布之间的相关性。类内关系:每个类上所有实例的概率的相关性。
2.重访KD的预测匹配
在常规知识提炼[15]中,通过最小化教师和学生模型的预测分数之间的差异,将知识从预先训练的教师模型转移到学生模型。在形式上,对于学生和教师网络的逻辑Z(s) ∈ RB×C和Z(t) ∈ RB×C,其中B和C分别表示批量大小和类别数量,标准KD损失[15]表示为:
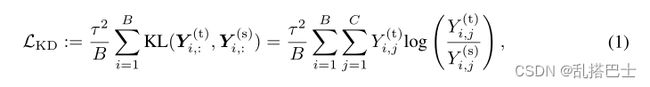
其中KL是指KL散度。
 是概率预测向量,τ是控制logits的软度的温度因子。
是概率预测向量,τ是控制logits的软度的温度因子。
除了老师在等式1中的软知识,KD[15]指出,与地面真实标签一起训练学生是有益的,并且总的训练损失由原始分类损失Lcls和KD损失LKD组成,即:

其中Lcls通常是学生网络和真实标签的预测之间的交叉熵损失,α和β是平衡损失的因子。
2.1与更强教师的灾难性差异
如第1节所述,教师对知识发现的影响尚未得到充分研究,尤其是当经过预培训的教师的表现变得更强时,如使用更大的模型规模或使用更先进的竞争策略进行培训,如标签平滑、混淆[50]、自动增强[8]等。在这方面,如图2所示,我们使用策略B1和策略B2单独训练ResNet-18和ResNet-50,并获得4个训练模型(R18B1、R18B2、R50B1和R50B2,准确率分别为69.76%、73.4%、76.13%和78.5%),然后使用预测概率Y的KL散度(τ = 1和τ = 4)比较它们的差异。我们有以下观察结果:
1.与ResNet-50相比,ResNet-18的输出在采用更强策略的情况下变化不大。这意味着代表能力限制了学生的表现,并且当他们的差异变大时,学生要完全匹配老师的输出往往是相当具有挑战性的
2.当用更强的策略训练教师和学生模型时,教师和学生之间的差异会更大。这表明,当我们采用具有更强得策略来进行KD时,KD损失和分类损失之间的错位会更严重,从而干扰学生的训练。
因此,与KL差异的精确匹配(当且仅当教师和学生的输出完全相同时,损失达到最小)似乎过于雄心勃勃和要求过高,因为学生和教师之间的差异可能相当大。因为精确的匹配对更强的老师是有害的,我们的直觉是发展一种轻松的方式来匹配老师和学生之间的预测。
3.DIST:从更强的老师那里升华
3.1使用关系的轻松匹配
预测分数表明教师对所有班级的信心(或偏好)。对于老师和学生之间轻松的预测匹配,我们被激励去考虑我们真正关心老师的输出是什么。事实上,在推理过程中,我们只关心它们之间的关系,即老师的预测的相对排名,而不是精确的概率值。
这样,对于具有RC × RC → R+的某个度量d(·,·),精确匹配可以被公式化为如果a = b,则d(a,b) = 0,对于任意两个预测向量作为Y (s) i,:和Y(t) i,:在等式1的KL散度中。那么作为一个宽松的匹配,我们可以引入额外的映射φ(·)和ψ(·),其中RC → RC使得
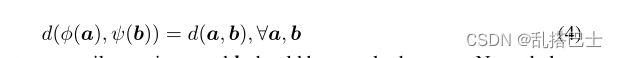
所以d(a,b) = 0不一定要求a和b应该完全一样。然而,由于我们关心a或b间的关系,映射φ和ψ应该是同调的,并且不影响预测向量的语义信息和推理结果。在这点上,同调映射的简单而有效的选择是正线性变换,即:
![]()
其中m1、m2、n1和n2是常数,m1 ×m2 > 0。因此,这种匹配在预测的尺度和偏移的单独变化下可以是不变的。实际上,为了满足等式。(5),我们可以采用广泛使用的皮尔逊距离作为度量,即:
![]()
ρp(u,v)是两个随机变量u和v之间的皮尔逊相关系数:
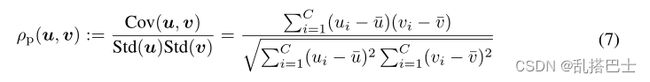
其中Cov(u,v)是u和v的协方差,u和Std(u)分别表示u的均值和标准差。这样,我们可以将这种关系定义为相关性。更具体地说,传统KD [15]中的原始精确匹配因此可以通过最大化线性相关性来放松和替换,以在每个实例的概率分布上保持教师和学生的关系,我们称之为类间关系。形式上,对于每对预测向量Y (s) i:和Y (t) i:来说,相互关系损失可以用公式表示为:
一些同调映射或度量也可用于放松匹配,如等式。(4)如第4.5节中根据经验调查的余弦相似性;其他更高级、更微妙的选择可以留待将来的工作来做。
3.2更好地利用内部关系进行蒸馏
除了类间关系之外,对于每个类,不同实例的预测分数也可以是有信息的和有用的。例如,假设我们有三个输入图像,分别包含“飞机”、“狗”和“猫”。关于“猫”类中的预测得分,“平面”的值应该是最小的,“狗”的量级适中,“猫”的置信度应该最高。此外,即使对于来自同一类的图像,语义相似度的内在类内方差实际上也是有信息的。它表明老师的先验知识,在这个班里选哪个更可靠。
因此,我们也鼓励提取这种内部关系以获得更好的性能。实际上,将预测矩阵Y (s)和Y (t)定义为每一行都是Y (s) i,:和Y (t) i,:,那么上面的相互关系就是最大化行方向的相关性(见图3)。相反,对于内部关系,相应的损失因此是使列方向的相关性最大化,即:

结果,总训练损失Ltr可以由分类损失、类间KD损失和类内KD损失组成,即:
![]()
其中,α、β和γ是平衡损耗的系数。这样,通过关系损失,我们或多或少地赋予了学生自适应匹配教师网络输出的自由,从而在很大程度上提高了提取性能。
4.实验
4.1实验设置
培训策略。表1总结了图像分类任务的训练策略CIFAR-100。为了公平比较,我们使用相同的训练策略(参见表1中的A1)和遵循CRD [40]的预训练模型。ImageNet。B1:为了与以前的KD方法进行比较,我们使用与CRD [40]相同的简单训练策略来训练我们的基线。B2:为了验证KD方法对现代训练策略的有效性,我们遵循EfficientNet [39]并设计了训练策略B2,与B1相比,它可以显著提高性能。B3:B3策略用于训练Swin-Transformers [26],包含更强大的数据扩充和正则化。
…
5.结论
提出了一种新的知识蒸馏方法——DIST法,以实现从更强的教师那里得到更好的知识提取。我们实证研究了学生和一个更强的老师之间的灾难性差异问题,并提出了一个基于关系的损失来放宽线性意义下KL散度的精确匹配。我们的方法DIST在处理强势老师方面既简单又有效。大量的实验表明了我们在各种基准测试任务中的优越性。例如,DIST甚至优于专门为对象检测和语义分割设计的最先进的KD方法。