AISHELL-3: A MULTI-SPEAKER MANDARIN TTS CORPUS AND THE BASELINES 论文理解
0. 说明
很好的中文多说话人 TTS 语料, 谢谢各位老师们~

0. 摘要
在本文中,我们提出了AISHELL-3,一个大规模和高保真的多说话人普通话语音语料库,可用于训练多说话人文本到语音(TTS)系统。该语料库包含了大约85小时的由218名母语为汉语的人所说的不带感情色彩的录音。他们的辅助属性如性别、年龄组和母语口音在语料库中被明确标记和提供。相应地,汉字级和拼音级的抄本与录音一起提供。我们提出了一个基线系统,使用AISHELL-3进行多说话人Madarin语音合成。多说话人语音合成系统是塔科龙-2的扩展,其中说话人验证模型和相应的语音相似性损失作为反馈约束被结合 (The multi-speaker speech synthesis system is an extension on Tacotron-2 where a speaker verification model and a corresponding loss regarding voice similarity are incorporated as the feedback constraint)。我们的目标是使用提出的语料库来建立一个健壮的合成模型,能够实现零镜头的声音克隆。在该数据集上训练的系统也很好地概括了在训练过程中从未见过的说话者。实验的客观评价结果表明,所提出的多扬声器合成系统在说话人嵌入相似度和等差错率度量方面都达到了较高的语音相似度。数据集1、基线系统代码和生成的样本2可在线获得
- www.aishelltech.com/aishell_3
- sos1sos2sixteen.github.io/aishell3

1. INTRODUCTION
TTS 泛指简介略
TTS的一个关键特征是缺乏约束,这使得任务本质上是一对多的映射[1]。由于只给定文本内容,由男性或女性发出的带有激动或中性声音的讲话同样是有效的输出。但是这种系统的实际应用需要健壮和一致的行为。这就引出了一个问题,我们是否可以向系统提供进一步的规范,以获得比传统方法更大的灵活性。该领域对设计更加灵活并允许对其行为进行更强约束的TTS系统越来越感兴趣。最近关于表达或韵律TTS系统的出版物倾向于将声学模型与显式控制信号(例如,监督设置的音调/能量[8]和非监督变体的学习嵌入[9,10,11])相关联,作为除标准化文本之外的增强输入。语音的一个更突出和更直观的特征是说话者身份,多说话者声学模型使TTS系统能够通过明确地将模型调节到期望的说话者来从合成话语的文本内容中分离出感知的说话者身份[12,13,14,15]
训练这样的系统自然需要大量的 注释数据。VCTK [16]是一个免费提供的多说话人语料库,可以用来训练这样的系统。但是,VCTK只包含英文录音。正如以前的研究[17,18]所表明的,尽管英语作为一种通用语言在学术界有文化影响,但语言特定的子系统和模型修改确实是一个活跃的研究领域。考虑到汉语普通话和日语复杂的声调和韵律结构,以声调语言为目标的TTS系统面临着困难的局面[19]。由于缺乏一个适用于TTS系统培训的可公开获得的多语种普通话数据集,这使得该领域的研究更加困难和昂贵,并且缺乏跨研究可比较的客观指标。
为此,我们在本文中介绍了AISHELL-3语料库 填补开放资源的空缺。AISHELL-3包含来自218个母语人士的大约85小时高保真普通话语音记录,以拼音符号的形式手动转录汉字和发音。此外,我们提出了一个多说话人说话人转换系统的训练数据集作为基线系统。对合成样本的客观评估显示出与先前在具有相同架构的VCTK系统上进行的研究一致的行为
2. THE AISHELL-3 DATASET
AISHELL-3数据集是一个多说话人汉语语音语料库,可用于训练多说话人语音合成系统。总共有来自218个母语人士的88035份录音,他们带着中立的情绪朗读给定剧本中的文本。所有话语都是在安静的室内环境中使用高保真麦克风(44.1千赫,16位深度)记录的,麦克风距离扬声器20厘米。文本内容的主题范围很广

每个录音都包含汉字和拼音的伴随成绩单,这是标记中文发音的官方拉丁文记号。拼音笔录是通过人类的听力测试获得的,并且直接对应于说话者的实际读数,解决了通过字典查找自动从汉字中导出它们时遇到的四个主要困难:1.同形异义词。某些字符可能会根据其所驻留的文本上下文以多种方式发音[20]。 2.音调变调。一些音调在某些语音环境下会发生变化,一个很好的例子是,通常,连续的第三音调的起始部分中的字符会移至第二音调,例如,第二个音调。 guan3 li3(用于管理)应发音为guan2li3,但此规则不适用于所有此类情况。 3. Erization(二花)。儿子的汉字(发音为er2)在某些情况下的行为与普通字符类似,但是它也充当了变义标记,表明前面的字符有变义的结尾。 4.重音和错语。上述困难使语音化过程变得不容易,并且手动标记的成绩单对于获得用于训练高质量TTS模型的纯数据集以及进一步开发更复杂的转换系统非常有价值

3. BASELINE SYSTEM
The baseline system is a composition of three independently designed components: a textual-frontend, which performs necessary analysis and conversion on the textual input, an acoustic model, which maps textual and speaker specifications to a series of feature vectors, and a neural vocoder to decode the feature sequence into audio waveforms
3.1. The Speaker-agnostic Subsystem
与说话者无关的子系统
The textual-frontend and vocoder modules are implemented as speaker-agnostic considering the textual analysis and acoustic feature inversion processes involved in the TTS pipeline have lower correlations to speaker identities than that of the acoustic model. The textual-frontend, which is used to preprocess the datasets’ raw labels, is composed of a pinyin-parser, a phonetizer, and a LSTM based prosody prediction model. We use a MelGAN [7] model trained with recordings from the AISHELL-3 dataset regardless of speaker labels as the neural vocoder
此外,我们还发现,单纯的塔科龙-2 仅用汉语音素或拼音输入训练,倾向于产生具有单调韵律的合成样本。考虑到韵律与普通话合成中的自然度有很高的相关性,我们应用了一个基于RNN的韵律标签预测模型,该模型在一个标注了韵律标签的语料库上进行训练[21]。然后,韵律注释被添加到音素序列[22]中,作为声学模型的最终输入序列
- [21] Chuxiong Zhang, Sheng Zhang, and Haibing Zhong, “A prosodic mandarin text-to-speech system based on tacotron,” in Proc. ofAPSIPA ASC 2019, pp. 165–169
- [22] CMU Pronouncing Dictionary, “Carnegie-mellon university pronouncing dictionary for american english,” Version 0.6. Available at [www.speech.cs.cmu.edu/cgi-bin/cmudict], 1998
- [23] Xinchi Chen, Xipeng Qiu, and Xuanjing Huang, “A featureenriched neural model for joint chinese word segmentation and part-of-speech tagging,” in Proc. ofIJCAI-17, pp. 3960–3966
韵律标签预测任务被公式化为序列 标记问题:输入序列是一系列可学习的字符嵌入、BMES标记的分词和词性标记。输入序列首先用两层双向长时脉编码,然后由两个完全相连的输出层解码,以产生BMES标记的韵律预测。根据韵律单元结构的分级性质,以分级方式进行预测,其中韵律短语以措辞预测为条件 (不懂)
3.2. The Speaker-aware Subsystem
说话人感知子系统
我们遵循最近发表的关于多说话人TTS的工作,结合说话人嵌入反馈约束[15]来建立我们的说话人感知声学模型。它是一个基于塔可创2的架构,带有一个额外的扬声器编码器模块,如图2所示
- [15] Zexin Cai, Chuxiong Zhang, and Ming Li, “From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint,” in Proc. ofINTERSPEECH 2020
3.2.1. Tacotron-2 backbone
Tacotron-2 主干, 略, 常规~
3.2.2. Speaker encoder
说话人编码器用于从可变长度参考音频输入中提取有区别的说话人信息,在我们的例子中,该输入在训练期间总是基本真实音频。我们遵循[25]实现了一个基于Resnet的说话人验证网络,该网络具有全局均值-标准差池,作为我们的基线多说话人系统的说话人编码器。用于调节我们的声学模型的说话人嵌入向量是合并的均值和标准差特征向量的线性投影 (We follow [25] to implement a Resnet-based speaker verification network with global mean-std pooling as the speaker encoder for our baseline multi-speaker system. The speaker embedding vector used to condition our acoustic model is a linear-projection of the pooled mean and standard deviation feature vectors) (不懂, 不过也不是谷歌的, 先不管也阔以吧~)
- [25] Weicheng Cai, Jinkun Chen, Jun Zhang, and Ming Li, “On the-fly data loader and utterance-level aggregation for speaker and language recognition,” IEEE/ACMTransactions on Audio, Speech, and Language Processing, vol. 28, pp. 1038–1051, 2020.
3.2.3. Feedback constraint
我们从以前的研究中了解到,仅在编码器隐藏状态上连接说话人嵌入向量并不能对声学模型施加足够强的激励,从而在说话人相似性方面产生高保真度的结果,尤其是当参考音频从未出现在训练数据中时[14]。最近关于说话人身份反馈约束的工作表明,通过在参考嵌入和合成信号的提取嵌入之间添加额外的损失项,产生的语音的鲁棒性和说话人相似性被有效地增加[15]。我们遵循上述研究中的系统描述来修改我们的基线多扬声器声学模型。如图2所示,训练过程中的每个优化步骤都包括一个附加的说话人嵌入余弦相似性损失项。扬声器编码器模块中的参数是预先训练的,并在声学模型的训练过程中冻结。最终的损失函数包括几个项:

- [14] Erica Cooper, Cheng-I Lai, Yusuke Yasuda, Fuming Fang, Xin Wang, Nanxin Chen, and Junichi Yamagishi, “Zero-shot multispeaker text-to-speech with state-of-the-art neural speaker embeddings,” in Proc. ofICASSP 2020, pp. 6184–6188
- [15] Zexin Cai, Chuxiong Zhang, and Ming Li, “From Speaker Verification to Multispeaker Speech Synthesis, Deep Transfer with Feedback Constraint,” in Proc. ofINTERSPEECH 2020
4. EXPERIMENTS
我们实施并培训了基线合成系统,并对合成样本进行了评估。声学模型和神经声码器使用所呈现的数据集来训练,并且说话者编码器模块使用来自AidaTaang[26]和MAGICDATA普通话[27]语料库的775289个话语来单独训练。本节描述了声学模型的详细数据准备过程和评估结果
- [26] aidatatang 200zh, “https://openslr.org/62/,”
- [27] Magic Data Technology Co., Ltd., “https://openslr. com/68/,”
4.1. Data Preparation
4.1.1. Down-sampling
To match the acoustic feature used for training the pre-trained speaker encoder, we downsample the data to 16kHz sample-rate, and uses window and hop lengths of 50 ms and 12.5 ms respectively
4.1.2. Train-test separation
The training and testing data division is in broad terms made randomly based on speaker identities. Of the presented 218 speakers, 44 were drawn randomly from the population to form the unseen speakers test-set. The remaining 174 speakers are used to train the multi-speaker model described in chapter 3. It is worth noting that not all samples from the training set are used in model training, a portion of the utterances for each speaker in the training set are kept for seen speakers validation, The resulting train-set contains 64773 utterances, which is around 60 hours long
4.1.3. Silence trimming
在我们提出的系统中,编码器隐藏状态和解码器解码步骤之间形成的注意力对准直接控制合成话语的定时和节奏。然而,由于比对本身是模型优化过程的无监督副产品,形成良好比对的阶段会有效地影响训练合成模型的整体质量。[28]中的实验证明了这种相关性。在我们的初步研究中,我们通过受控实验发现,在声学模型训练期间,在训练样本的初始位置修整无声段会极大地加快对准形成。因此,我们对所有训练样本的梅尔谱图进行了基于能量的变风量空调,并修剪了所有初始静音段。这导致在2个GTX-1080千兆位图形处理器下的优化步骤方面的对准形成加速10倍
- [28] Eric Battenberg, RJ Skerry-Ryan, Soroosh Mariooryad, Daisy Stanton, David Kao, Matt Shannon, and Tom Bagby, “Location-relative attention mechanisms for robust long-form speech synthesis,” in Proc. ofICASSP 2020, pp. 6194–6198
4.1.4. Long-form sentence augmentation
长句扩充
据观察,当目标句子在推理阶段太长时,合成的话语显示不稳定的注意对齐或不自然的语速。这是由于混合注意机制的泛化能力差,这种机制在塔可创-2模型中常见的长形式合成中[9,29]。初步实验表明,通过利用纯粹基于位置的注意机制[28],这种泛化问题是以韵律自然性为代价的。然而,在我们的例子中,我们将数据扩充作为这个问题的解决方案
整个数据集的平均句子长度为11.3个字符,相当多的样本覆盖了20多个字符。我们将从同一说话者中随机抽取的N个句子的声学特征和文本标签连接起来,以产生一个更长的训练样本,其中N是从分布中抽取的离散r . v(P2 = 0.6,P3 = 0.2,P4 = 0.2)。这里Pn表示n的概率质量函数fN()。通过这种增加,我们生成了30000个样本作为增加的训练数据。扩充的数据用于微调收敛于原始数据集的TTS模型
4.2. Objective Evaluation
我们进行客观评估,以评估由基线模型产生的合成样本的说话者相似性。评估分两组进行:验证组和测试组,验证组包含与训练组相同的说话者,这反映了模型模仿训练过程中看到的说话者的声音的能力,测试组显示了模型在训练期间看不见的参考说话者上的概括程度

图片文字翻译:
- 说话人嵌入可视化使用t-SNE,从音频记录中提取的嵌入用点表示,用十字合成。从左到右,从上到下:(一)验证集记录;验证集记录&合成;(三)测试集记录;(四)测试集记录&合成。请注意,验证集包含可见的扬声器,而测试集仅包含不可见的扬声器
没太仔细看:
- 在这两个实验中,我们为每个说话者合成了20个文本相关和20个文本无关的话语,其中文本相关意味着具有相同文本内容的基本事实音频被用于提取说话者嵌入,而文本无关则使用说话者各自的平均嵌入向量作为参考。在训练阶段看不到合成样本的文本内容。此外,我们为每个样本合成了3个版本,以说明prenet模块中的丢弃层引入推理阶段的随机性。通过评估产生的注意图,我们消除了错误对齐的样本。这是通过计算输出步骤之间的注意力得分向量的余弦相似性来完成的,因为自然对齐将符合几乎对角的趋势,导致较低的步骤间相似性。为以下测量提取每个选定合成样本的说话者表示
- T-SNE Plot. 我们将提取的说话人表示可视化 空间作为二维散点图使用分布式随机邻居嵌入(SNE)。由于t-SNE图模拟了嵌入向量之间的相对距离,图3中的A和C所示的聚类代表了说话者身份相近的话语组。我们清楚地观察到,来自同一说话者的嵌入形成了与其他说话者空间完全分离的密集簇
- SV-EER。我们还利用说话人验证等差错率的概念作为客观评价指标。能效比在支持向量机任务中被普遍视为系统性能的指针,它也可以被解释为多说话人语音合成系统质量的衡量标准。完美的TTS系统将产生与真实数据无法区分的结果。为了使用能效比测量来评估系统,我们在每次试验中从音频样本池中抽取10,000对样本
余弦相似度。我们使用余弦函数来测量说话人 嵌入向量相似度,这是说话人验证系统中常用的方法。我们测量了合成语音嵌入和从真实音频样本中提取的嵌入之间的余弦相似性。说话人验证系统认为,较高的值意味着合成样本和记录样本之间的相似性较高
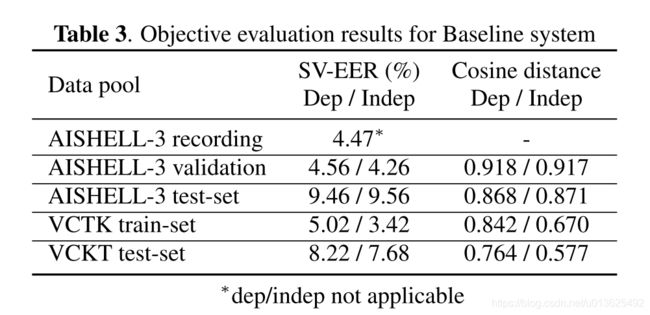
没太仔细看:
- 介绍了我们的结果和在[15]中发布的VCTK数据集上进行的类似实验。据观察,验证集和测试集说话人在合成样本和真实样本之间实现了高平均余弦相似性。验证扬声器的EERs仅比SV基线高0.65%和0.60%。测试集和验证集扬声器之间的能效比下降了约5%,这与在VCTK上获得的结果一致,尽管两个扬声器嵌入网络使用不同的数据进行训练
5. CONCLUSION
本文提出了一个新的可公开使用的普通话语音语料库,用于训练多说话人语音合成系统。该数据集包含从218个母语人士收集的88035个高保真度话语记录,并包括手写标注的完整拼音注释。此外,提出并详细描述了一种基于说话人嵌入反馈约束的基线多说话人说话人转换系统。我们分析了所呈现数据集的特征,并在数据准备过程中加入了一些增强过程,如韵律标签预测、静音修剪和长句子连接。根据说话人相似性和泛化能力进一步评估训练后的模型。我们发现我们提出的多说话人语音合成系统能够产生模仿参考说话人声音的自然语音。基于客观和感性的实验结果,我们得出结论,所提出的语料库对汉语多说话人转换系统的研究是有价值的