TextCNN文本分类实践
CNN介绍
CNN是特殊的全连接层,包含两个特性:平移不变性和只和周边位置相关
CNN用于处理图像,也可以处理文本和语音,处理图像时,基础的CNN不能解决旋转和放大缩小问题,因为神经网络输入是一行像素转换成向量,所以大小不同的同一张图片对于神经网络的输入是不一样的。常见的操作是卷积和pool(可以省略),卷积kernal_size不同决定了视野范围不同,pool有max,mean,相当于去除了奇数行和列,在围棋中就不可以用pool,pool之后就flatten,softmax
传统文本分类方法
1.训练集(文本预处理)
2.特征工程

常用特征:
Bag of Words:
此向量表示法不会保存原始句子中词的顺序

TF-IDF:

文档可以看作段落,陌生词可以用一个符号表示,如UNK
3.分类器
分类器:SVM,朴素贝叶斯,LR等
深度学习文本文类方法:

word embedding:
word2vec训练词向量算法:CBOW SKIP-GRAM
GLOVE无监督
fasttext可以做文本分类和词向量训练,有监督任务学习,反向传播更新embedding矩阵
TextCNN简介
将卷积神经网络CNN应用到文本分类任务,利用多个不同大小的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能更好捕捉局部相关性
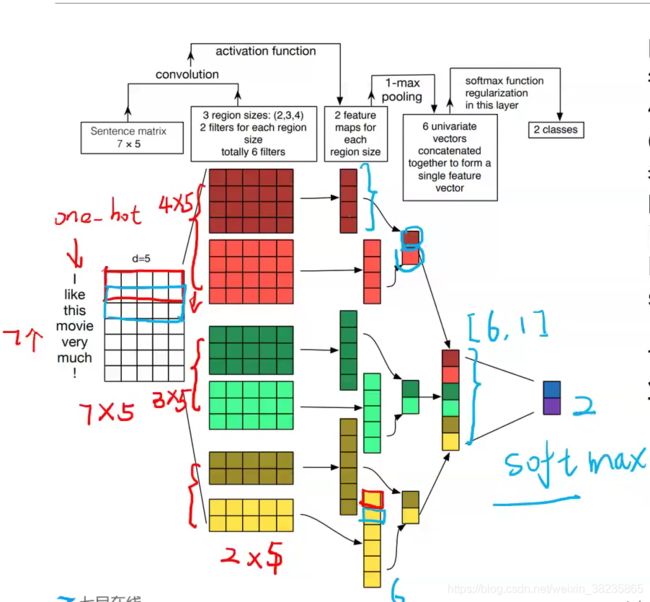
第二层可以理解为某个词,2gram 3gram 4gram

目标:对数据进行而分类,判断是否两句话是同一个含义
模型关键代码
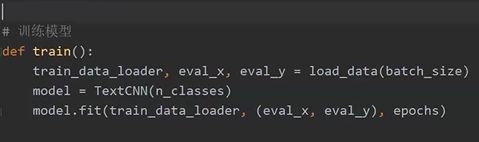
BaseModel 重写nn.module
线性及全连接层(out_chanels大写,提取到的特征会更多)
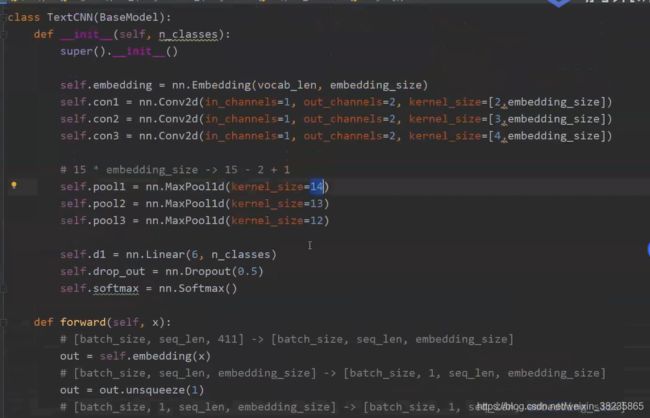
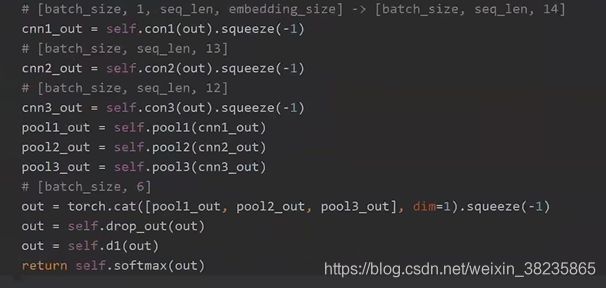
TEXTCNN模型全部代码:
import torch.nn as nn
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn.functional as F
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torch.nn.functional as F
import argparse
import pickle
from torch.utils.data import Dataset, DataLoader
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
# 参数
class Config(object):
def __init__(self,
word_embedding_dimension=100,
word_num=20000,#20000,train 1-19015
epoch=5,
sentence_max_size=61,#40,59
cuda=False,
label_num=5,
learning_rate=0.03,
batch_size=256,
out_channel=200 # acc: 0.4994
):
self.word_embedding_dimension = word_embedding_dimension # 词向量的维度
self.word_num = word_num
self.epoch = epoch # 遍历样本次数
self.sentence_max_size = sentence_max_size # 句子长度
self.label_num = label_num # 分类标签个数
self.lr = learning_rate
self.batch_size = batch_size
self.out_channel=out_channel
self.cuda = cuda
config = Config()
class TextDataset(data.Dataset):
def __init__(self,train_data_list,label_list):
self.set = torch.tensor(train_data_list)
self.label = torch.tensor(label_list)
def __getitem__(self, index):
return (self.set[index], self.label[index])
def __len__(self):
return len(self.set)
class TextCNN(nn.Module):
def __init__(self, config):
super(TextCNN, self).__init__()
self.config = config
self.out_channel = config.out_channel
self.conv3 = nn.Conv2d(1, 1, (2, config.word_embedding_dimension))
self.conv4 = nn.Conv2d(1, 1, (3, config.word_embedding_dimension))
self.conv5 = nn.Conv2d(1, 1, (4, config.word_embedding_dimension))
self.Max3_pool = nn.MaxPool2d((self.config.sentence_max_size - 2 + 1, 1))
self.Max4_pool = nn.MaxPool2d((self.config.sentence_max_size - 3 + 1, 1))
self.Max5_pool = nn.MaxPool2d((self.config.sentence_max_size - 4 + 1, 1))
self.linear1 = nn.Linear(3, config.label_num)
self.dropout = nn.Dropout(p=0.5) # dropout训练
self.softmax = nn.Softmax()
def forward(self, x):
batch = x.shape[0]
# Convolution
x1 = F.relu(self.conv3(x))
x2 = F.relu(self.conv4(x))
x3 = F.relu(self.conv5(x))
# Pooling
x1 = self.Max3_pool(x1)
x2 = self.Max4_pool(x2)
x3 = self.Max5_pool(x3)
# capture and concatenate the features
x = torch.cat((x1, x2, x3), -1)
x = x.view(batch, 1, -1)
x = self.dropout(x)
# project the features to the labels
x = self.linear1(x)
x = x.view(-1, self.config.label_num)
return F.softmax(x, dim=1) # F.softmax(self.softmax(x), dim=1) #
# 自定义token
class Token(object):
def __init__(self, vocab_file_path, max_len=202):
self.vocab_file_path = vocab_file_path
self.max_len = max_len
self.word2id, self.id2word = self._load_vovab_file() # 得到词典
# 进行参数验证
if self.max_len > 510: # 表示超过了bert限定长度
raise Exception(print('设置序列最大长度超过bert限制长度,建议设置max_len<=510'))
# 加载词表生成word2id和id2word列表
def _load_vovab_file(self):
with open(self.vocab_file_path, 'r', encoding='utf-8') as fp:
vocab_list = [i.replace('\n', '') for i in fp.readlines()]
word2id = {}
id2word = {}
for index, i in enumerate(vocab_list):
word2id[i] = index
id2word[index] = i
return word2id, id2word
# 定义数据编码encode并生成pytorch所需的数据格式
def encode_str(self, txt_list: list):
# 针对所有的输入数据进行编码
return_txt_id_list = []
for txt in txt_list:
inner_str = txt
inner_str_list = list(inner_str)
inner_seq_list=[]
for char in inner_str_list:
char_index = self.word2id.get(char, False)
if char_index == False: # 表示该字符串不认识
inner_seq_list.append(self.word2id.get('[UNK]'))
else:
inner_seq_list.append(char_index)
#inner_seq_list.append(self.word2id.get('[SEP]')) # 跟上结尾token
# 执行padding操作
inner_seq_list += [self.word2id.get('[PAD]')] * (self.max_len - len(inner_str_list))
return_txt_id_list.append(inner_seq_list)
return return_txt_id_list#return_data
# 定义解码操作
def decode_str(self, index_list):
return ''.join([self.id2word.get(i) for i in index_list])
def eval_score(preds_prob, label):
preds = [0 if row[0] > 0.5 else 1 for row in preds_prob]
pd_data = pd.concat([pd.DataFrame(preds, columns=['预测值']), pd.DataFrame(label, columns=['真实值'])], axis=1)
# 计算总体的召回率 精准度 f1值
# loc index,Single label,List of labels.
total_TP = len(pd_data.loc[(pd_data.真实值 == 1) & (pd_data.预测值 == 1)]) # 真正例
total_TN = len(pd_data.loc[(pd_data.真实值 == 0) & (pd_data.预测值 == 0)]) # 真反例
total_FN = len(pd_data.loc[(pd_data.真实值 == 1) & (pd_data.预测值 == 0)]) # 假反例
total_FP = len(pd_data.loc[(pd_data.真实值 == 0) & (pd_data.预测值 == 1)]) # 假正例
# if total_TP + total_TP == 0: # 分母可能为0修改错误
if total_TP + total_FP == 0: # 分母可能为0
total_precision = 0
else:
total_precision = total_TP / (total_TP + total_FP)
if total_TP + total_FN == 0:
total_recall = 0
else:
total_recall = total_TP / (total_TP + total_FN)
if total_recall + total_precision == 0:
total_f1 = 0
else:
total_f1 = total_recall * total_precision / (total_recall + total_precision)
# 计算正确率
acc = len(pd_data.loc[pd_data.真实值 == pd_data.预测值]) / len(pd_data)
return (total_precision, total_recall, total_f1, acc), ['精准度', '召回率', 'f1值', '正确率']
def get_dataloader(data_set):
return DataLoader(dataset=data_set,
batch_size=config.batch_size,
num_workers=2)
def loaddata():
path = 'G:/Pythonfile/project/TextCNN/data/train/'
df_train = pd.read_table(path + "gaiic_track3_round1_train_20210228.tsv",
names=['q1', 'q2', 'label']).fillna("0") # (100000, 3)
df_test = pd.read_table(path + 'gaiic_track3_round1_testA_20210228.tsv',
names=['q1', 'q2']).fillna("0") # (25000, 2)
train_num = int(0.7 * df_train.shape[0])
label_list = df_train['label'].values
label_list = [[line] for line in label_list]
train_data_list = (df_train['q1'] + " 19999 " + df_train['q2']).values#ndarray
train_data_list = [line.split(' ') for line in train_data_list]#list
train_data_list = [list(map(int, line)) for line in train_data_list]
sentence_max_size = 61
def add_padding(data_list):
for line_list in data_list:
if len(line_list) <= sentence_max_size:
line_list += [0] * (sentence_max_size - len(line_list))
return data_list
train_data_list = add_padding(train_data_list)
train_set = TextDataset(train_data_list[:train_num], label_list[:train_num])
dev_set = TextDataset(train_data_list[train_num:], label_list[train_num:])
training_iter = get_dataloader(train_set)
valid_iter = get_dataloader(dev_set)
return training_iter,valid_iter
def load_data(path):
token = Token(r'C:\Users\LENOVO\Desktop\AI_\bert-base-chinese\vocab.txt')
df_train = pd.read_csv(path + "\\train.csv").fillna("0") # (100000, 3)
#train_data_list =[token.encode_str(i) for i in (df_train['sentence1'] + "н" + df_train['sentence2']).values]
train_data_list = token.encode_str((df_train['sentence1'] + "н" + df_train['sentence2']).values)
label_data_list =[[line]for line in df_train['label'].values]#array([0, 0, 0, ..., 1, 1, 0], dtype=int64)
training_set = TextDataset(train_data_list,label_data_list)
training_iter = DataLoader(dataset=training_set,
batch_size=config.batch_size,
num_workers=2)
df_dev = pd.read_csv(path + '\\dev.csv').fillna("0") # (25000, 2)
dev_data_list = token.encode_str((df_dev['sentence1'] + "н" + df_dev['sentence2']).values)
dev_label_data_list = [[line]for line in df_train['label'].values]
dev_set = TextDataset(dev_data_list, dev_label_data_list)
dev_iter = DataLoader(dataset=dev_set,
batch_size=config.batch_size,
num_workers=2)
# test_set = TextDataset(df_test)
# test_iter = DataLoader(dataset=test_set,
# batch_size=config.batch_size,
# num_workers=2)
return training_iter,dev_iter
def train_model(training_iter,valid_iter):
# Create the configuration
model = TextCNN(config)
embeds = nn.Embedding(config.word_num, config.word_embedding_dimension)
if torch.cuda.is_available():
model.cuda()
embeds = embeds.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=config.lr)
# Train the model
loss_list =[]
for epoch in range(config.epoch): #
loss_sum = 0
count = 1
sum_out = np.array([])
sum_label = np.array([])
model.train() # 防止过拟合
for i, batch_data in enumerate(training_iter):
data = batch_data[0] # torch.Size([256, 60]) #batchsize_250
label = batch_data[1] # torch.Size([256, 1])
if torch.cuda.is_available(): # config.cuda and
data = data.cuda()
label = label.cuda()
input_data = embeds(autograd.Variable(data))
input_data = input_data.unsqueeze(1) # [256, 202, 100]-->[256, 1, 202, 100]
optimizer.zero_grad()
out = model(input_data)#Expected 4-dimensional input for 4-dimensional weight [1, 1, 3, 100]
loss = criterion(out,
autograd.Variable(label).squeeze()) # out:torch.Size([256, 2]),lable:torch.Size([256, 1])--> torch.Size([256])#autograd.Variable(label.float()))
loss_sum += loss
loss.backward()
optimizer.step()
count = count + 1
model.eval()
for i, batch_data in enumerate(valid_iter):
data = batch_data[0] # torch.Size([256, 60]) #batchsize_250
label = batch_data[1] # torch.Size([256, 1])
if torch.cuda.is_available(): # config.cuda and
data = data.cuda()
label = label.cuda()
input_data = embeds(autograd.Variable(data))
input_data = input_data.unsqueeze(1) # (256,1,60,100)
optimizer.zero_grad()
out = model(input_data)#Expected 4-dimensional input for 4-dimensional weight [1, 1, 3, 100]
sum_out = out.cpu().detach().numpy() if i == 0 else np.append(sum_out, out.cpu().detach().numpy(),axis=0)
sum_label = label.cpu().detach().numpy() if i == 0 else np.append(sum_label, label.cpu().detach().numpy(),axis=0)
print("epoch", epoch+1, end=' ')
print("train The average loss is: %.5f" % (loss_sum / count))
loss_list.append((loss_sum / count).cpu().detach().numpy())
total_res, total_label = eval_score(sum_out, sum_label)
total_precision, total_recall, total_f1, total_acc = total_res
print(f'valid的 precision:{total_precision} recall:{total_recall}, f1:{total_f1} acc: {total_acc}')
print('avery_loss_list',loss_list)
torch.save(model.state_dict(), './data/params.pkl')
#torch.save(model, './model/model.pkl')
print('Model saved successfully')
if __name__ == '__main__':
path = r'G:\Pythonfile\project\bert-utils\data'
training_iter,valid_iter = loaddata()#加载数据 该数据已经脱敏过了,类似句子1:1 23 34 454 232 句子二:1 34 43 11 标签: 0
#training_iter,valid_iter = load_data(path) #加载数据未脱敏,类似‘我想请问借款的日利率计是怎样算的吖?’ ‘微粒贷均采用日固定利率,按借款的实际天数计息。已发放贷款的执行利率固定不变,每日利息=剩余未还本金(借款金额-已还金额)x日利率(当前日利率为0.05%),您也可以在微粒贷页面点击借款,输入具体借款金额查看对应利息。回复以下序号获取答案:1:了解微粒贷计息详情2:多笔借款的利息计算3:我需要人工帮助’ 0
train_model(training_iter,valid_iter)
#model = torch.nn.Module.load_state_dict('./model/params.pkl')#使用反序列化的 state_dict 加载模型的参数字典。
model = TextCNN(config)
model = model.load_state_dict(torch.load('./data/params.pkl'))#使用反序列化的 state_dict 加载模型的参数字典。
相关名词介绍
分布式表达
主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。核心思想也都由两部分组成:一、选择一种方式描述上下文;二、选择一种模型刻画某个词(下文称“目标词”)与其上下文之间的关系。
词的分布式表示:
- 基于矩阵的分布表示
基于矩阵的分布表示通常又称为分布语义模型,在这种表示下,矩阵中的一行,就成为了对应词的表示,这种表示描述了该词的上下文的分布。由于分布假说认为上下文相似的词,其语义也相似,因此在这种表示下,两个词的语义相似度可以直接转化为两个向量的空间距离。
常见到的Global Vector 模型( GloVe模型)是一种对“词-词”矩阵进行分解从而得到词表示的方法,属于基于矩阵的分布表示。 - 基于聚类的分布表示
- 基于神经网络的分布表示,词嵌入( word embedding)
基于神经网络的分布表示一般称为词向量、词嵌入( word embedding)或分布式表示( distributed representation)。
NLP语言模型
语言模型包括文法语言模型和统计语言模型。统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。给定一个词汇集合 V,对于一个由 V 中的词构成的序列S = ⟨w1, · · · , wT ⟩ ∈ Vn,统计语言模型赋予这个序列一个概率P(S),来衡量S 符合自然语言的语法和语义规则的置信度。常见的统计语言模型有N元文法模型(N-gram Model)
Embedding
作用:
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系
引入:
One-hot 编码
首先需要表示的离散或类别变量的总个数 N,然后对于每个变量,用 N-1 个 0 和单个 1 组成的 vector 来表示每个类别。这样做有两个很明显的缺点:
- 对于具有非常多类型的类别变量,变换后的向量维数过于巨大,且过于稀疏。
- 映射之间完全独立,并不能表示出不同类别之间的关系。
# One Hot Encoding Categoricals
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
Similarity (dot product) between First and Second = 0
Similarity (dot product) between Second and Third = 0
Similarity (dot product) between First and Third = 0
虑到这两个问题,表示类别变量的理想解决方案则是我们是否可以通过较少的维度表示出每个类别,并且还可以一定的表现出不同类别变量之间的关系,这也就是 embedding 出现的目的。
改进:
将vector做一些改进:
1、将vector每一个元素由整形改为浮点型,变为整个实数范围的表示;
2、将原来稀疏的巨大维度压缩嵌入到一个更小维度的空间。
为了更好的表示类别实体,可以是用一个 embedding neural network 和 supervised 任务来进行学习训练,以找到最适合的表示以及挖掘其内在联系。
One-hot 编码的最大问题在于其转换不依赖于任何的内在关系,而通过一个监督性学习任务的网络,我们可以通过优化网络的参数和权重来减少 loss 以改善我们的 embedding 表示,loss 越小,则表示最终的向量表示中,越相关的类别,它们的表示越相近。
参考:
NLP公开课七月第四节探索文本分类
word2vec和word embedding有什么区别
Embedding 的理解
万物皆Embedding,从经典的word2vec到深度学习基本操作item2vec