如何使用YOLOV4的darknet训练自己的数据集?
0 我的环境
ubuntu 16.04
GPU 2080Ti
CUDA: 10.0.0
cuDNN: 7.4.1
1 下载darknet源码
方式一:首先我们需要下载yolov4的darknet源码:https://github.com/AlexeyAB/darknet
方式二:因为从github下载源码比较慢,可是使用另外一种方法,将github上的源码保存在gitee中,然后从gitee上下载源码。gitee毕竟是国内的嘛,下载速度会开很多。
具体操作就是:
(1) 创建gitee账号并且登录
(2) 点击新建仓库

(3) 新建仓库会弹出一个新的界面,然后将界面拉到最底部,点击import

点击import之后,然后在其中输入github上darknet的地址就行

(4) 这样你就会创建一个darknet的仓库,内容和github的内容一样

然后点击copy复制地址,使用git clone 的方在终端中进行下载。
2 创建数据集文件目录
首先我们需要下载yolov4的darknet源码:https://github.com/AlexeyAB/darknet
因为从github下载源码比较慢,可是使用另外一种方法,将github上的源码保存在gitee中,然后从gitee上下载源码。gitee毕竟是国内的嘛,下载速度会开很多。
如果不对yolov4源码进行修改的,但是想使用yolov4训练自己的数据集,我们需要按照yolov4读取数据集的方式,创建相应的数据集文件目录。最终的数据集目录结构是这个样子的:
darknet-master
---- data
---- obj.names # 物体类别名称(如果有两类物体,就写上两类物体的名称)
---- obj.data # 将数据集的信息保存在这个文件中,yolov4从这个文件中读取数据集信息
---- obj # 存放图片以及每个图片的标签信息
---- train.txt # 存放训练集地址 (相对地址,比如: data/obj/image1.jpg)
---- test.txt # 存在测试集地址 (相对地址,比如: data/obj/image3.jpg)我分别介绍一个data文件夹下五个文件或文件夹的作用以及格式:
(1) obj.names 该文件中保存的是检测物体的名称。假设有一个安全帽检测的项目,检测有没有戴安全帽。没有戴安全帽的标签是people,戴安全帽的标签是hat。那么obj.names文件中就这样写:
person
hat每一类名称独占一行,这样是为了方便读取文件中的内容,我们只需要通过换行符就可以轻松分割并读取obj.names中每个类别的名称。
(2) obj.data 该文件中保存着五类信息:类别数量,训练集,验证集,类别名称和保存权重的文件
classes= 2 # 2表示数据集中只有两类可检测的物体
train = data/train.txt # 表示保存训练数据集的地址
test= data/test.txt # 表示保存验证数据集的地址
names = data/obj.names # 表示可检测物体的名称
backup = backup/ # 表示保存训练权重的文件obj.data文件其实就是一个汇总文件,yolov4需要的数据集地址,数据集标签以及信息的时候就是从这个文件中得到的。该文件涉及的内容在上下文都有涉及,这里就不再赘述。
(3) obj 该文件夹中存放着整个数据集(训练集和验证集)的图片(.jpg格式)以及它们的标签(.txt)文件。也就是说每一张图片都对应一个txt标签文件。比如image1.jpg图片对应的标签文件就是image1.txt文件。将数据集图片和标签放在一起有一个好处就是,我们不需要单独将图片和标签放在不同的文件夹下,只需要提供一个文件路径,得到所有的.jpg图片之后将其后缀改成.txt就可以得到相应的标签文件,这样做方便有简洁。
每个标签文件中包含如下五个信息:
object-class: 表示物体的数字标签。比如0, 1, 2等整数。
举例来说:
如果一幅图片中包含不止一个物体,那么每幅图片的标签信息应该如何填写?举例来说,对于image1.jpg图片有三个物体,image1.txt文件就是这样:
1 0.716797 0.395833 0.216406 0.147222
0 0.687109 0.379167 0.255469 0.158333
1 0.420312 0.395833 0.140625 0.166667(4) train.txt 该文件中保存着所有训练集的相对地址。比如:
data/obj/img1.jpg
data/obj/img2.jpg
data/obj/img3.jpg(5) test.txt 该文件中保存着所有验证集的相对地址。比如:
data/obj/img11.jpg
data/obj/img21.jpg
data/obj/img31.jpg到这,数据集的搭建就已经完成了。下面我们需要对yolov4的配置文件进行修改。
3 修改配置文件
(1) 复制yolov4.cfg文件将其重命名为yolov4-obj.cfg。这样就不会对原始文件进行修改。
(2) 修改yolov4-obj.cfg如下内容:
# step1: 修改batch和subdivisions
L2: batch=64 # 原来就是64,根据gpu自己选择
L3: subdivisions=16 # 原来是8,根据自己的gpu选择
# step2: 修改图片的尺寸
L7: width=608 # 这边我就不进行修改了
L8: height=608 # 这边我也不修改
# step3: 修改classes(每个yolo层都需要修改一次,一共需要修改三次)
L968: classes=2 # 我只需要识别两类物体,因此需要修改成2
L1056: classes=2
L1144: classes=2
# step4: 需要修改每个yolo相邻的上一个convolution层的filter
L961: filters=21 # 因为我预测两类物体:21 = 3*(5+2)
L1049: filters=21
L1137: filters=21
4 修改makefile文件
darknet使用c语言编写的,因此我们需要对其进行编译。在编译之前我们需要修改makefile文件,并修改如下内容:
(1) GPU=1: 表示在训练的时候使用CUDA进行加速训练(CUDA应该在 /usr/local/cuda文件夹下)
(2) CUDNN=1: 表示在训练的过程中使用CUDNN v5-v7进行加速(cuDNN应该在 /usr/local/cudnn文件夹下)
(3) CUDNN_half=1: 为Tensor Cores (在Titan V / Tesla V100 / DGX-2等)上进行加速训练和推理。
(4) OPENCV=1: 编译OpenCV 4.x/3.x/2.4.x等。OpenCV可以读取视频或者图片。
(5) DEBUG=1: 编译debug版本的Yolo
(6) OPENMP=1:使用OpenMP进行编译,能够使用多核的CPU进行加速
(7) LIBOS=1: 编译构建darknet.so动态库。
(8) ZED_CAMREA=0: 置为1的时候表示构建ZED-3D-camera的库。这里我们不使用
5 配置OpenCV
这里参考了这位老哥的博客
(1) 下载相关库文件
# step1
sudo apt-get install build-essential
# step2
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
# step3
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
(2) 安装cmake
sudo apt-get install cmake(3) 下载opencv并进行编译
step1: opencv3.4.9下载地址(选择sources):https://opencv.org/releases/
step2: 解压,并且创建build文件夹,对opencv进行编译(这里面我是将opencv放在darknet-master文件夹下,然后编译的)
# step1: 切换到opencv目录下
cd opencv
# step2: 创建build文件夹
mkdir build
# step3: 切换到build文件夹
cd build
# step4: 使用camke进行生成CMakeLists文件
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
# step5: 使用make命令进行编译
sudo make -j8
# step6
sudo make install
(4) 将opencv的库添加到路径中,从而让系统能够找到
# step1: 打开文件
sudo gedit /etc/ld.so.conf.d/opencv.conf
# step2: 向文件中加上下面命令
export /usr/local/
# step3: 让动戴链接库为系统所享
sudo ldconfig
# step4: 配置bashrc
sudo gedit /etc/bash.bashrc
# step5: 在文件中加上下面两行命令
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
# step6: 最后再终端中source一下
source /etc/bash.bashrc(5) 最后,我们需要编译darknet
darknet是使用c语言开发的框架,如果要使用的话,我们需要对其进行编译。具体操作就是打开终端,然后转到darnet-master文件夹下,输入make进行编译就可以了。
# step1: 转到darknet所在的文件夹
cd darknet-master
# step2: 使用make进行编译
make这时候你会发现文件夹下会多出来一些东西,比如darknet可执行文件,backup文件等。我们通过运行darknet就可以进行训练或者检测,backup是存放我们训练权重的文件夹。
6 进行训练
(1) 下载预训练权重: yolov4.conv.137
(2) 执行下面命令:
./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -map(3) 在训练的过程中,darknet会自动保存权重文件
- backup文件夹下的yolo-obj_last.weights文件会每隔100个iterations保存一次,新的会替代旧的
- backup文件夹下的yolo-obj_xxxx.weights文件会每隔1000个iterations保存一次
darknet总的训练步长可以在yolov4-obj.cfg文件中修改max_batches的大小(默认max_batches = 500500)
补充:如果想要指定具体的gpu进行训练,可以使用-i来指定,比如我想使用索引为2的gpu进行训练,可以这样写:
./darknet detector train data/obj.data cfg/yolov4-obj.cfg yolov4.conv.137 -i 2 -map
7 训练yolov4-tiny
(1) yolov4-tiny前29层的预训练权重:点击这里
(2) 基于yolov4-tiny-obj.cfg进行修改配置文件
(3) 执行下面的命令进行训练:
./darknet detector train data/obj.data cfg/yolov4-tiny-obj.cfg yolov4-tiny.conv.29
8 什么时候该停止训练
随着训练的进行,不可避免的会出现过拟合现象的发生,那我们什么时候应该停止训练呢?
通常来说每一类都要充分训练2000个iterator,而且不少于训练集中图片的数量,总共不应小于6000个iterations。但是为了获得一个更好的训练精度,你应该手动停止训练,停止的时机可以参考下面;
(1) 在训练的过程中,你会看到各种各样的指标,当0.xxxxxxx avg不再变化的时候,你就应该停止训练

-
9002:表示当前的iteration
-
0.600730:表示平均的损失函数(越小越好)
当你观察到平均损失函数(average loss)0.xxxxxxx avg不再变化的时候,你就应该停止训练。最终的平均损失函数在0.5(对于小的模型、简单的数据集)到3.0(对于较大的模型、复杂的数据集)之间。
或者当你在终端中加上 -map 参数的时候,你就会看到mAP指标,Last accuracy [email protected] = 18.50%,这个指标比损失函数作为指标要合适的多,因此在训练的过程中mAP不断增加,你就应该继续进行训练。
(2) 一旦你停止了训练,你就应该在backup文件夹中选择最合适的权重。
举例来说,如果你在9000 iterations停止训练,但是最好的模型在7000, 8000, 9000之间,而且不确定会不会产生过拟合,因此你需要找到提前停止训练的点(Early Stopping Point)。
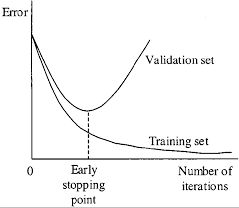
首先,准备验证集。你需要在 obj.data中将valid = data/test.txt 修改成 valid = data/valid.txt (valid.txt的格式和train.txt的合适一样),如果你没有验证集,你可以直接将train.txt的内容直接复制到valid.txt文件中。
其次,对候选的权重测试mAP。如果你是在9000 iterations停止训练的,你就需要对之前保存的权重进行测试。
# step1: 测试7000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_7000.weights
# step2: 测试8000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_8000.weights
# step3: 测试9000 iterations的mAP
./darknet detector map data/obj.data yolo-obj.cfg backup\yolo-obj_9000.weights然后选择一个mAP最高的权重作为最优的训练权重。
(3) 当然,你也可以在训练的时候就显示mAP,然后根据训练过程图选择最合适的权重(上文使用的就是这样方式)

由上图所示,我们可以选择8000 iteration的权重作为最终的训练权重。
9 进行检测
训练好权重之后,我们可以使用权重进行检测,在终端中输入下面命令就行:
./darknet detector test data/obj.data cfg/yolo-obj.cfg yolo-obj_8000.weights加载模型之后,需要我们输入图片的地址:

10 检测视频
(1)只显示FPS,但是不显示图像:
./darknet detector demo data/obj.data cfg/yolov4-obj.cfg backup/yolov4-obj_9000.weights data/demo3.mp4 -dont_show -ext_output
(2)显示FPS也显示图像,并且保存检测视频结果:
./darknet detector demo data/obj.data cfg/yolov4-obj.cfg backup/yolov4-obj_9000.weights data/demo3.mp4 -ext_output -out_filename res.mp4