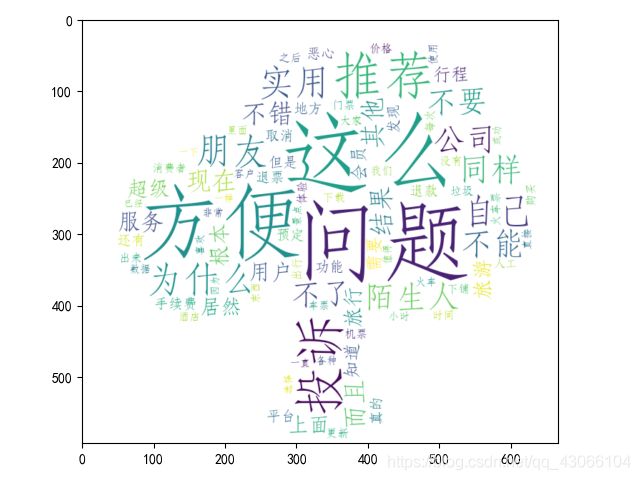
python绘制词云图(新手入门)
步骤
1.用到的库:
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud
2.设定词云图的形状
Mask=np.array(Image.open('E:/市调/tree1.jfif'))
参数mask是来设置词云图形状的,可以自定义设置,最好是已经填充好了颜色的图片,不然可能显示不出词云图。通过导入本地图片,用的背景图是这张:

上传不了JFIF格式的图片,只能截图了。。。
这张图片也可当背景图,从一篇大佬文章里下载的图片:

3.数据清洗,分词处理
这块还在学习,知识有限,不做过多说明了。用到数据是清洗过后的,效果如下:

4.设置参数
wc=WordCloud(
font_path='C:\\Windows\\Fonts\\STFANGSO.TTF',#此行所有电脑都一样,不用更改
background_color='white',width=1000,height=880,mask=Mask
).generate(cut_text)
font_path='C:\\Windows\\Fonts\\STFANGSO.TTF'
#此行所有电脑都一样,不用更改
| background_color | width,height |
|---|---|
| 设置词云图背景色 | 设置 词云图宽度高度 |
mask设置词云图形状
#词云图
import numpy as np
from PIL import Image
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
#显示中文,防止中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#设定词云图的形状
Mask=np.array(Image.open('E:/市调/tree1.jfif'))
#词语来源
path_txt='E:/市调/高频词-高频词.txt'
f=open(path_txt,'r',encoding='gbk').read()
#分词处理
cut_text=" ".join(jieba.lcut(f))
#词云图参数设置
wc=WordCloud(
font_path='C:\\Windows\\Fonts\\STFANGSO.TTF',#此行所有电脑都一样,不用更改
background_color='white',width=1000,height=880,mask=Mask
).generate(cut_text)
plt.imshow(wc,interpolation='bilinear')#显示词云图
plt.show()
效果: