7 Papers & Radios | ICCV 2021获奖论文,MIT华人团队解决持续70年的数学难题
本周论文主要包括ICCV 2021获奖论文等研究。
目录:
-
Revitalizing CNN Attentions via Transformers in Self-Supervised Visual Representation Learning
-
Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
-
Deep Neural Networks and Tabular Data: A Survey
-
Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
-
HighlightMe: Detecting Highlights from Human-Centric Videos
-
Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
-
EQUIANGULAR LINES WITH A FIXED ANGLE
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Revitalizing CNN Attentions via Transformers in Self-Supervised Visual Representation Learning
-
作者:Chongjian Ge、Youwei Liang、Yibing Song、Jianbo Jiao、 Jue Wang、 Ping Luo
-
论文链接:https://arxiv.org/pdf/2110.05340.pdf
**摘要:**来自港大、腾讯 AI Lab、牛津大学的学者在 NeurIPS 2021 发表了一篇文章。该研究受现有自监督表征学习架构 BYOL 的启示,结合前沿的 Transformer ,提出利用 Transfomer 来提升 CNN 注意力的自监督表征学习算法。本文将现有的架构归为 C-stream,另提出 T-stream。在 CNN 骨干网络的输出并行接入 T-stream。将 Transformer 置于 T-stream 中提升 CNN 输出的注意力,并以此结果来监督 CNN 自身的输出,从而达到提升 CNN 骨干网络注意力的效果。在现有的标准数据集中,也进一步提升了 CNN 骨干网络在下游识别任务的各类性能。
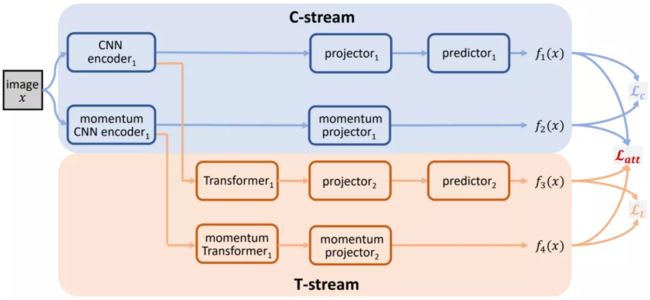
Proposed pipeline
本文提出的算法流程图如上所示。首先将输入图像 x 进行两次不同的预处理得到两个正样本 x_1、x_2。然后,用 C-stream 的两个 CNN 编码器分别提取 x_1、x_2 的特征,其中将一路 CNN 提取的特征输入映射器 projector1 和预测器 predictor1 得到高维特征 f_1(x),同时将另一路 CNN 提取的特征仅输入动量更新的映射器 (momentum projector1) 得到高维特征 f_2(x)。此外,双路 CNN 提取的这两组特征也会被同时输入到 T-stream。其中一路的 Transformer1 提取具有空间注意力的特征,并将此特征输入到映射器 projector2 和预测器 predictor2 得到高维特征 f_3(x)。另一路动量更新的 Transformer 同样提取 CNN 特征并输入动量更新的映射器 momentum projector2 得到高维特征 f_4(x)。
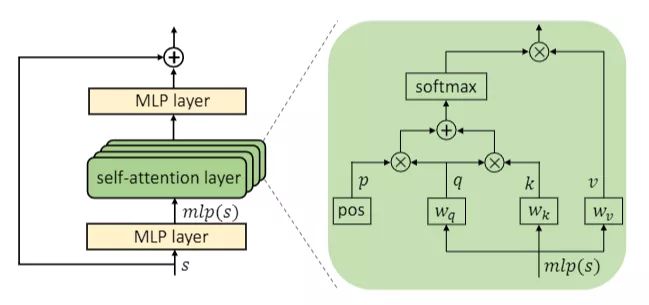
Transformer 结构示意图
**推荐:**用 Transformer 振兴 CNN 骨干网络,入选 NeurIPS 2021。
论文 2:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
-
作者:Philipp Lindenberger、Paul-Edouard Sarlin 等
-
论文链接:https://arxiv.org/pdf/2108.08291.pdf
**摘要:**在多个视图中寻找可重复的局部特征是稀疏 3D 重建的基础。经典的图像匹配范式一次性检测每个图像的全部关键点(keypoint),这可能会产生定位不佳的特征,使得最终生成的几何形状出现较大错误。研究者通过直接对齐来自多个视图的低级图像信息来细化运动恢复结构(structure-from-motion,SFM)的两个关键步骤:首先在任何几何估计之前调整初始关键点位置,然后细化点和相机姿态作为一个后处理。这种改进对大的检测噪声和外观变化具有稳健性,因为它基于神经网络预测的密集特征优化了特征度量误差。这显著提高了相机姿态和场景几何的准确性,并适用于各种关键点检测器、具有挑战性的观看条件和现成的(off-the-shelf)深度特征。该系统可以轻松扩展到大型图像集合,从而实现像素完美的大规模众包定位。该方法现已封装为 SfM 软件 COLMAP 的附加组件。
细化几何原本是一种局部操作,但该研究表明局部密集像素可以起到较大的作用。SfM 通常尽可能早地丢弃图像信息,该研究借助直接对齐用几个步骤替代了 SfM。下图 2 是该方法的概览:

**推荐:**ICCV 2021 最佳学生论文奖。
论文 3:Deep Neural Networks and Tabular Data: A Survey
-
作者:Vadim Borisov 、 Tobias Leemann 等
-
论文链接:https://arxiv.org/abs/2110.01889
**摘要:**近日,来自蒂宾根大学等机构的研究者进行了一项表格数据 SOTA 深度学习方法的调查研究。该研究首先将这些方法分为三组:数据转换、专用架构和正则化模型,然后全面概述了每个组中的主要方法。
通过解释表格数据上的深度学习模型,该研究对生成表格数据的深度学习方法展开了详细的讨论。该研究的主要贡献是对领域内的主要研究流派和现有方法进行分类,同时突出相关挑战和开放型研究问题。这是领域内首个深入研究基于表格数据的深度学习方法的工作,可作为表格数据深度学习研究者和从业者的宝贵指南。
该调查的目的是为了提供:
1. 对现有关于表格数据深度学习的科学文献的彻底审查;
2. 对异构表格数据进行分类和回归任务的可用方法的分类学分类;
3. 最先进技术的介绍以及对生成表格数据的有希望的路径的展望;
4. 表格数据深层模型的现有解释方法概述;
5. 关于表格数据深度学习成功有限的主要原因的讨论;
6. 与表格数据深度学习相关的开放挑战列表。
基于此,数据科学从业者和研究人员将能够快速为用例或研究问题确定起点和指导。
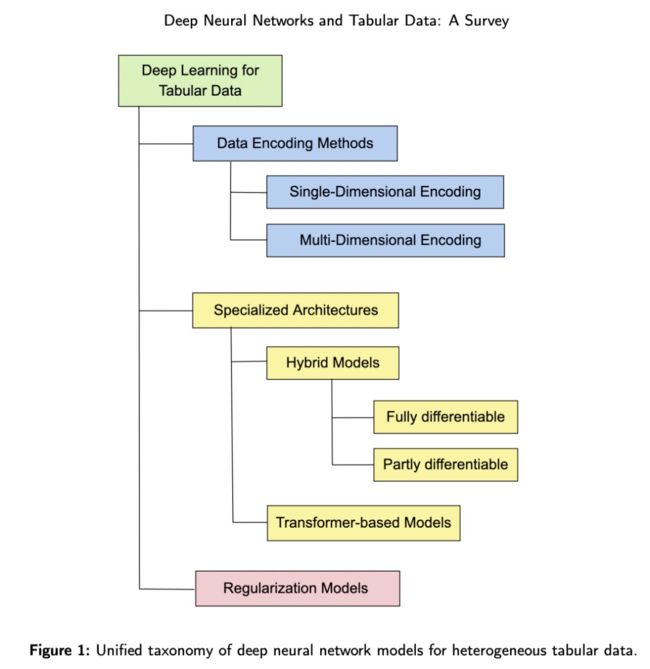
下图 1 是基于表格数据的深度学习模型的概览。

下图 2 是基于表格数据的生成模型的概览(按时间排序)。

**推荐:**首个深入研究基于表格数据的深度学习方法的工作。
论文 4:Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
-
作者:Jonathan T. Barron、Ben Mildenhall、Matthew Tancik 等
-
论文链接:https://arxiv.org/pdf/2103.13415.pdf
**摘要:**NeRF(neural radiance fields)使用的渲染过程以每像素单个光线对场景进行采样,因此当训练或测试图像以不同分辨率观察场景内容时,可能会产生过度模糊的渲染。该研究提出了 mip-NeRF,它以连续值的比例表示场景。他们通过高效地渲染消除反锯齿圆锥锥体( anti-aliased conical frustums)取代光线,mip NeRF 减少了混叠瑕疵(aliasing artifacts),并显著提高了其表示精细细节的能力,同时比 NeRF 快 7%,而大小仅为 NeRF 的一半。与 NeRF 相比,mip NeRF 在数据集上降低了 17% 的平均错误率,在具有挑战性的多尺度变体上降低了 60% 的平均错误率。此外,Mip NeRF 还能够在多尺度数据集上与超采样 NeRF 的精度相匹配,同时速度快 22 倍。

**推荐:**ICCV 2021 最佳论文荣誉提名奖。
论文 5:HighlightMe: Detecting Highlights from Human-Centric Videos
-
作者:Uttaran Bhattacharya、Gang Wu 等
-
论文链接:https://arxiv.org/pdf/2110.01774.pdf
**摘要:**近日,来自 Adobe Research 的研究人员提出了一种针对以人为主体的视频的自动高亮集锦生成的方法,在无需任何人工注释和用户偏好信息来完成训练的前提下,该方法比现有最优方法在匹配人工注释的准确度上提升了 4%~12%。
具体而言,该研究提出了一种领域和用户偏好无关的方法来检测以人为中心的视频中的高亮片段。他们使用基于图表达的方法作为视频中多个可观察到的以人为中心的模式,如姿势和面孔。研究者使用一个配备了时空图卷积的自动编码器网络来检测基于这些模式的人类活动和交互。该研究基于帧的代表性训练网络,从而将不同模式的基于活动和交互的潜在结构表示映射到每帧的高亮得分。该研究使用这些分数来计算突出哪些帧,并结合相邻帧来产生摘录。他们在大规模动作数据集 AVA-Kinetics 上训练网络,并在 DSH、TVSum、PHD 和 SumMe 四个基准视频高亮数据集上评估网络。在这些数据集中,与最先进的方法相比,该研究在不需要任何用户偏好信息或对新数据集调参的情况下在匹配人工标注的高亮上的平均精度上提高了 4%-12%。

代表性。上图展示了不同视频帧在姿态(左)和地标(右)计算的不同代表性值。该研究根据代表性来学习高亮分数。
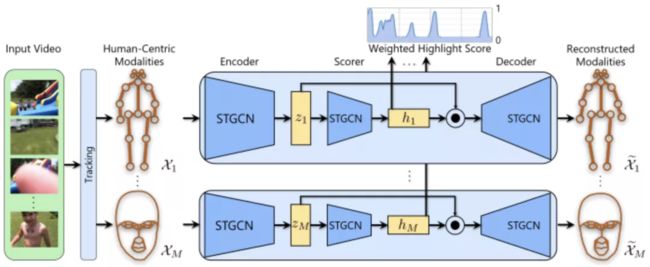
使用以人为中心的模式的高亮检测:学习网络概述,突出显示来自多种以人为中心的模式的分数。使用标准技术 [29,12] 来检测以人为中心的模式。该研究将这些模式表示为二维或三维中的连接点集合,并且并行地训练所有模式的网络。网络之间唯一的交互点是他们预测的高亮分数,该研究将其合并到加权高亮分数中进行训练。
**推荐:**该工作已被 ICCV 2021 接收。
论文 6:Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
-
作者: Jeremy Reizenstein、 Roman Shapovalov 等
-
论文链接:https://arxiv.org/pdf/2109.00512.pdf
**摘要:**由于缺乏真实的以类别为中心的 3D 标注数据,传统的 3D 物体类别学习方法,主要是在合成数据集上进行训练和评估。来自 Facebook AI 研究院、伦敦大学学院的研究者通过收集与现有合成数据类似的真实世界数据来促进该领域的进展。因此,这项工作的主要贡献是一个名为「Common Objects in 3D」的大规模数据集,其中含有真实的多视角物体类别图像,并附有相机姿态和 3D 点云标注真值。
该数据集包含来自近 19,000 个视频的 150 万帧捕获了 50 个 MS-COCO 类别的物体,因此它在类别和物体的数量方面都比其他数据集具有明显优势。研究者利用这个新数据集对几种新视图合成和以类别为中心的 3D 重建方法进行了大规模评估。此外,该研究还贡献了 NerFormer——一种新颖的神经渲染方法,利用强大的 Transformer 来重建仅给定少量视图的物体。


上图报告了所收集视频的总数(右)和每个类别(左)的数量,以及具有准确相机和点云的视频数量。
**推荐:**ICCV 2021 最佳论文荣誉提名奖。
论文 7:EQUIANGULAR LINES WITH A FIXED ANGLE
-
作者:ZILIN JIANG、JONATHAN TIDOR、YUAN YAO 等人
-
论文链接:https://arxiv.org/pdf/1907.12466.pdf
**摘要:**等角线(Equiangular Lane)是一个数学用语,通常在数学上这样表示:在△ABC 中,在线段 BC 上取 P、Q,使得∠BAP=∠CAQ,则称 AP、AQ 为△ABC 中的等角线。

更简单的说,等角线是空间中通过一个点的线,其对角都是相等的。想象一下二维正六边形的三条对角线,三维正二十面体的六个对顶点的连接线,参见下图:

然而,数学家们并不局限于三维。有研究者认为在更高维度也存在等角线,并且在高维度上,等角线的可能性几乎是无限的。据了解,这是一个困惑了数学家们至少 70 年的问题。来自 MIT 的研究者认为在高维空间中等角线并不是无限的。他们突破性的研究决定了可以放置的线的最大可能数量,以便这些线以相同的给定角度成对分开。论文将发表在 2022 年 1 月的《数学年鉴》上。
这篇论文为一个被称为谱图理论(spectral graph theory)的数学领域提供了新的见解,并且为研究网络提供了有力的数学工具。其中谱图理论带来了计算机科学中的重要算法,如谷歌搜索引擎 PageRank 算法。这种对等角线的新理解为编码和通信领域带来了巨大的意义。等角线是「球形编码」的示例,它是信息理论中的重要工具,允许不同方面在一个嘈杂的通信渠道上相互发送信息,如 NASA 与其火星探测器之间发送的信息。
**推荐:**MIT 华人团队用谱图理论解决持续 70 年的数学难题。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
10 NLP Papers.mp3 音频: 进度条 00:00 / 19:30 后退15秒 倍速 快进15秒
本周 10 篇 NLP 精选论文是:
1. UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning. (from Jiawei Han, Wen-tau Yih)
2. Causal Transformers Perform Below Chance on Recursive Nested Constructions, Unlike Humans. (from Stanislas Dehaene)
3. Cross-lingual COVID-19 Fake News Detection. (from Philip S. Yu)
4. HETFORMER: Heterogeneous Transformer with Sparse Attention for Long-Text Extractive Summarization. (from Philip S. Yu)
5. ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. (from William W. Cohen, Ruslan Salakhutdinov)
6. FILM: Following Instructions in Language with Modular Methods. (from Pradeep Ravikumar, Ruslan Salakhutdinov)
7. On Language Model Integration for RNN Transducer based Speech Recognition. (from Hermann Ney)
8. Investigation on Data Adaptation Techniques for Neural Named Entity Recognition. (from Hermann Ney)
9. ActiveEA: Active Learning for Neural Entity Alignment. (from Bing Liu)
10. Learning to Describe Solutions for Bug Reports Based on Developer Discussions. (from Raymond J. Mooney)
10 CV Papers.mp3 音频: 进度条 00:00 / 21:06 后退15秒 倍速 快进15秒
本周 10 篇 CV 精选论文是:
1. Open-Set Recognition: A Good Closed-Set Classifier is All You Need. (from Andrea Vedaldi, Andrew Zisserman)
2. Sub-word Level Lip Reading With Visual Attention. (from Andrew Zisserman)
3. ABO: Dataset and Benchmarks for Real-World 3D Object Understanding. (from Jitendra Malik)
4. Unsupervised Object Learning via Common Fate. (from Thomas Brox, Bernhard Schölkopf)
5. Object-Region Video Transformers. (from Trevor Darrell)
6. Toward a Visual Concept Vocabulary for GAN Latent Space. (from Antonio Torralba)
7. No way to crop: On robust image crop localization. (from Xiangyu Zhang)
8. Deep Long-Tailed Learning: A Survey. (from Shuicheng Yan)
9. Semi-supervised Multi-task Learning for Semantics and Depth. (from Ming-Hsuan Yang)
10. ViDT: An Efficient and Effective Fully Transformer-based Object Detector. (from Ming-Hsuan Yang)
10 ML Papers.mp3 音频: 进度条 00:00 / 20:02 后退15秒 倍速 快进15秒
本周 10 篇 ML 精选论文是:
1. Action-Sufficient State Representation Learning for Control with Structural Constraints. (from Bernhard Schölkopf)
2. Hitting the Target: Stopping Active Learning at the Cost-Based Optimum. (from Eibe Frank)
3. Detecting adversaries in Crowdsourcing. (from Georgios B. Giannakis)
4. Identification of Attack-Specific Signatures in Adversarial Examples. (from Rama Chellappa)
5. Codabench: Flexible, Easy-to-Use and Reproducible Benchmarking for Everyone. (from Isabelle Guyon)
6. Label scarcity in biomedicine: Data-rich latent factor discovery enhances phenotype prediction. (from Alexandre Gramfort, Gaël Varoquaux)
7. SoGCN: Second-Order Graph Convolutional Networks. (from Jianbo Shi)
8. Distinguishing rule- and exemplar-based generalization in learning systems. (from Thomas L. Griffiths)
9. A Meta-learning Approach to Reservoir Computing: Time Series Prediction with Limited Data. (from Michelle Girvan)
10. Multi-Agent MDP Homomorphic Networks. (from Max Welling)
----版权声明----
仅用于学术分享,若侵权请联系删除