局部敏感哈希算法
私认为,文本的相似性可以分为两类:一类是机械相似性;一类是语义相似性。
机械相似性代表着,两个文本内容上的相关程度,比如“你好吗”和“你好”的相似性,纯粹代表着内容上字符是否完全共现,应用场景在:文章去重;
语义相似性代表着,两个文本语义上的相似程度,比如“苹果”和“公司”的相似性,本篇不做这一讨论,可参考笔者的另外一篇博客:
NLP︱句子级、词语级以及句子-词语之间相似性(相关名称:文档特征、词特征、词权重)
把LSH局部敏感哈希算法讲明白的一篇博客:Locality Sensitive Hashing ( LSH,局部敏感哈希 ) 详解
常规的敏感hash可以将文本降维成简单数字串,但是计算相似时候只能两两比较,计算量巨大。
局部敏感哈希算法一般用在常规Hash之后,相比两两比较,LSH可以实现再降维+局部寻找匹配对。
————————————————————————————————————————————————
一、基本概念界定上的区别
1、Hash叫哈希,也叫散列,可以叫散列算法,也可以叫哈希算法;
2、hash与其他诸如simhash/minhash的区别:
一般的hash可能两个文档本来相似,但是hash之后的值反而不相似了;simhash/minhash可以做到两个文档相似,hash之后仍然相似;
3、simhash与Minhash的区别:
simhash和minhash可以做到两个文档Hash之后仍然相似,但是simhash计算相似的方法是海明距离;而minhash计算距离的方式是Jaccard距离。
4、局部敏感哈希与simhash、minhash的区别。
局部敏感哈希可以在这两者基础上更快的找到相似、可匹配的对象,而且继承了simhash/minhash的优点,相似文档LSH计算之后还是保持相似的。
————————————————————————————————————————————————
二、hash函数拓展simhash、minhash算法
1、海明距离与Jaccard距离
(1)Hamming Distance(海明距离)
Hamming Distance可以用来度量两个串(通常是二进制串)的距离,其定义为这两个二进制串对应的位有几个不一样,那么海明距离就是几,值越小越相似。例如x=1010,y=1011,那么x和y的海明距离就是1。又如x=1000,y=1111,那么x和y的海明距离就是3。
(2)Jaccard Coefficient(Jaccard 系数)
Jaccard Coefficient用来度量两个集合的相似度,设有两个集合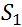 和
和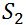 ,它们之间的Jaccard Coefficient定义为:
,它们之间的Jaccard Coefficient定义为:
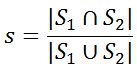 ,值越大越相似。
,值越大越相似。
例如 ,
,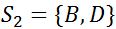 ,则
,则 。
。
2、simhash与minhash
simhash和minhash由于hash之后的算法构造不同,所以需要不同的距离去测度,一般simhash用的是海明距离,而minhash用的是Jaccard距离。
hash原理不展开介绍,放一张图大致了解一下,详情可见参考文献:
(1)simhash:

(2)minhash:
Min-hashing定义为:特征矩阵按行进行一个随机的排列后,第一个列值为1的行的行号。举例说明如下,假设之前的特征矩阵按行进行的一个随机排列如下:
| 元素 |
S1 |
S2 |
S3 |
S4 |
| 他 |
0 |
0 |
1 |
0 |
| 成功 |
0 |
0 |
1 |
1 |
| 我 |
1 |
0 |
0 |
0 |
| 减肥 |
1 |
0 |
1 |
1 |
| 要 |
0 |
1 |
0 |
1 |
最小哈希值:h(S1)=3,h(S2)=5,h(S3)=1,h(S4)=2.
参考文献:
使用simhash进行海量文本去重(来源于:poll的笔记)
局部敏感哈希算法(Locality Sensitive Hashing,LSH)(来源于:poll的笔记)
————————————————————————————————————————————————
三、局部敏感哈希(Locality Sensitive Hashing,LSH)算法
局部敏感哈希算法应该算是 hash㈡(Hash之后再Hash)。
1、LSH算法流程介绍
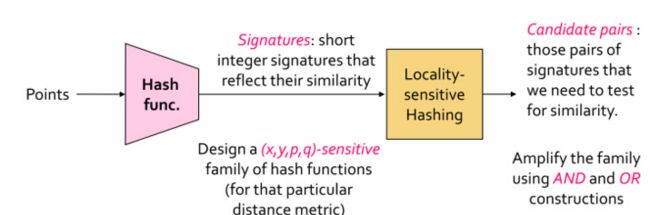
整个流程:
1、一般的步骤是先把数据点(可以是原始数据,或者提取到的特征向量)组成矩阵;
2、第一次hash functions(有多个哈希函数,是从某个哈希函数族中选出来的)哈希成一个叫“签名矩阵(Signature Matrix)”的东西,这个矩阵可以直接理解为是降维后的数据,此时用simhash、minhash来做,第一步的hash过程可以使用不同的functions来做;
3、第二次LSH把Signature Matrix哈希一下,就得到了每个数据点最终被hash到了哪个bucket里,如果新来一个数据点,假如是一个网页的特征向量,我想找和这个网页相似的网页,那么把这个网页对应的特征向量hash一下,看看它到哪个桶里了。
于是bucket里的网页就是和它相似的一些候选网页,这样就大大减少了要比对的网页数,极大的提高了效率。注意上句为什么说是“候选网页”,也就是说,在那个bucket里,也有可能存在和被hash到这个bucket的那个网页不相似的网页,原因请回忆前面讲的“降维”问题。
但LSH的巧妙之处在于可以控制这种情况发生的概率,这一点实在是太牛了,下面会介绍。
2、LSH实质解读
那么可以看出LSH的实质其实就是把hash之上的数据再一次降维。相比两两比较,LSH可以实现再降维+局部寻找匹配对。
降维会对相似性度量造成什么影响?
数据的维数在某种程度上能反映其信息量,一般来说维数越多,其反映的信息量就越大,比如说对于一个人,假设有一个一维数据:(姓名),有一个三维数据(姓名,身高,体重),那么这个三维数据反映的信息是不是要比一维的多?如果我们知道的信息越多,是不是就能越准确地判定两个东西的相似性?
所以,降维就在某种程度上造成的信息的丢失,在降维后的低维空间中就很难100%保持原始数据空间中的相似性,所以刚才是说“保持一定的相似性”。
一方面想把数据降维,一方面又希望降维后不丢失信息。
那么LSH就要做一个妥协了,双方都让一步,那么就可以实现在损失一点相似性度量准确性的基础上,把数据降维
3、LSH局部敏感哈希算法
LSH流程中有两个流程,第一个hash是用simhash,minhash来做,在第一部分里面有,第二个hash才是局部敏感哈希的内容。
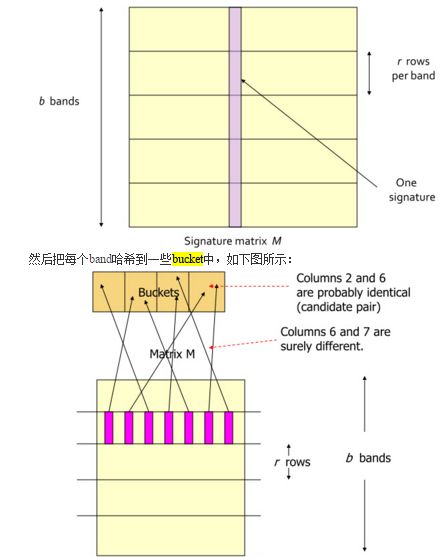
LSH的具体流程:
1、将Signature Matrix分成一些bands,每个bands包含一些rows(就像把每一个文档ID变成4个(band)部分,4个(band)颜色)。
2、然后把每个band哈希到一些bucket中,注意bucket的数量要足够多(筛选:设定bucket个篮子,然后比对,相同的颜色部分扔到相应的篮子里面)。
3、计算相似性。使得两个不一样的bands被哈希到不同的bucket中,这样一来就有:如果两个document的bands中,至少有一个share了同一个bucket,那这两个document就是candidate pair,也就是很有可能是相似的。(找相似:同一个篮子里面的就是有可能相似的样本框;如果两个篮子都有同样的颜色和同样的ID,说明这几个同样的ID相似性较高)
4、相似性分析案例
这里涉及到的参数有点多:
第一个参数:buckets,LSH会预先设定一些篮子,作为相似性匹对的粒度,Buckets越多越好,粒度越细,当然越吃计算量;
第二个参数:维度h,就是第一步hash成多长的维度,simhash可以指定划分的维度;
第三个参数:bands(b),签名矩阵分块,分为不同的部分;
第四个参数:行数row(r),r=h/b,签名矩阵每一块有r行(r个文本);
第五个参数:相似性S,代表两个文档的相似性。
第六个参数:相似性J,代表buckets共现相似性(J)。
从操作的流程可以得到,LSH第二步是先根据 buckets共现相似性(J) 找出潜在的候选匹配对,然后在这些匹配对之上计算文档相似性(S)。两者相互关系为:
J=1-(1-S^r)^b (1)
文本的相似性才是我们最后要求得的。
更为神奇的是,LSH这些概率是可以通过选取不同的band数量以及每个band中的row的数量来控制的:
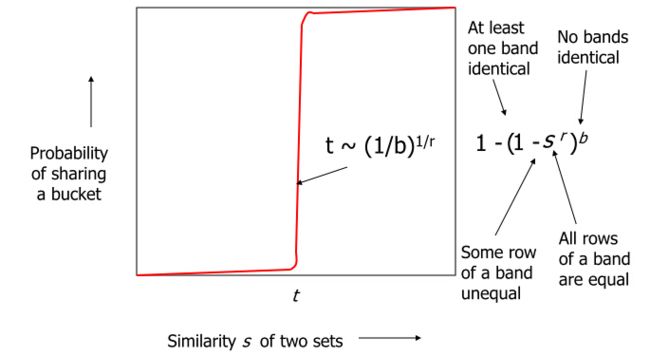
纵轴代表buckets共现相似性(J),横轴代表文档相似性(S)。看懂这个图就可以大致了解实战过程中,如何设置参数啦。
看图可知在文本相似性S达到某一个临界值的时候,临界值之下LSH会智能得判定 buckets共现相似性(J)极小,而大于某一个临界值的时候,LSH会判定buckets相似性J极高。
LSH会将相似性高的认为是候选匹配对留下,而相似性低的则不考虑。所以大大简化了计算量。这个阀值的公式为:
S(t)=(1/b)^1/r (2)
当然笔者在这从案例从发设想如何构造该阈值:
如果设定h=200维度的hash值,bands设定为b=50,那么r=4,则根据公式(2)可得S(t)=0.376,S(t)>0.376则会判定为匹配对,低精度,若有一个文本相似性为S=0.5,则根据公式(1)在已经S情况下:J(buckets)=0.96;
如果设定h=200维度的hash值,bands设定为b=4,那么r=50,则根据公式(2)可得S(t)=0.972,S(t)>0.972则会判定为匹配对,高精度,若有一个文本相似性为S=0.5,则根据公式(1)在已经S情况下:J(buckets)=3.55E-15。
上述结果比较符合预期的就是,在低精度的情况下超过阈值的,相似性J立刻变得极高,判定为匹配对。
从严格性来看,可以通过调整h维度、bands的b来调整阈值,达到调节精度的目的;当然啦,肯定是高精度比较好。
本篇很多都是笔者自己瞎想的,若有错请大家一定要给我说呀!!!!!
————————————————————————————————————————————
拓展一:应用场景
LSH的应用场景很多,凡是需要进行大量数据之间的相似度(或距离)计算的地方都可以使用LSH来加快查找匹配速度,下面列举一些应用:
(1)查找网络上的重复网页
互联网上由于各式各样的原因(例如转载、抄袭等)会存在很多重复的网页,因此为了提高搜索引擎的检索质量或避免重复建立索引,需要查找出重复的网页,以便进行一些处理。其大致的过程如下:将互联网的文档用一个集合或词袋向量来表征,然后通过一些hash运算来判断两篇文档之间的相似度,常用的有minhash+LSH、simhash。
(2)查找相似新闻网页或文章
与查找重复网页类似,可以通过hash的方法来判断两篇新闻网页或文章是否相似,只不过在表达新闻网页或文章时利用了它们的特点来建立表征该文档的集合。
(3)图像检索
在图像检索领域,每张图片可以由一个或多个特征向量来表达,为了检索出与查询图片相似的图片集合,我们可以对图片数据库中的所有特征向量建立LSH索引,然后通过查找LSH索引来加快检索速度。目前图像检索技术在最近几年得到了较大的发展,有兴趣的读者可以查看基于内容的图像检索引擎的相关介绍。
(4)音乐检索
对于一段音乐或音频信息,我们提取其音频指纹(Audio Fingerprint)来表征该音频片段,采用音频指纹的好处在于其能够保持对音频发生的一些改变的鲁棒性,例如压缩,不同的歌手录制的同一条歌曲等。为了快速检索到与查询音频或歌曲相似的歌曲,我们可以对数据库中的所有歌曲的音频指纹建立LSH索引,然后通过该索引来加快检索速度。
(5)指纹匹配
一个手指指纹通常由一些细节来表征,通过对比较两个手指指纹的细节的相似度就可以确定两个指纹是否相同或相似。类似于图片和音乐检索,我们可以对这些细节特征建立LSH索引,加快指纹的匹配速度。
来源:局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍
每每以为攀得众山小,可、每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~
———————————————————————————