Deep Learning in Natural Language Processing中文连载(三)
第二章
对话语言理解中的深度学习
Gokhan Tur, Asli Celikyilmaz, 何晓东,Dilek Hakkani-Tür 以及邓力
摘要 人工智能的最新进展导致对话助手的可用性增加,这些助手可以帮助我们完成一些任务,例如寻找时间安排活动,在当时创建日历记录,找到一家餐厅,并在某个时间在那里预订一张桌子。然而,用人工智能创建自动化代理仍然是人工智能最具挑战性的问题之一,这类系统的一个关键组成部分是会话语言理解,这是几十年来研究的最巅峰领域,因为它不是一个明确定义的任务,但严重依赖于它所使用的人工智能应用程序。不过,本章将试图整理最近基于深度学习,关于面向目标的对话语言理解研究的文献,从历史的角度和前深度学习时代的工作出发,一直到这个领域最近的进展。
2.1 简介
在过去的十年中,已经建立了各种面向目标的对话语言理解(CLU)系统,特别是作为虚拟个人助理的一部分,如谷歌助理、亚马逊Alexa、微软Cortana或苹果Siri。
与目的在于自动转录人所说的话的序列的语音识别相反,CLU的目标是从对话、口语或文本上下文里的自然语言中抽取“含义”。事实上,这意味着任何的实际应用都可以允许它的用户使用自然语言(随意说话)来执行任务。在文献中,CLU通常被用来表示在对话或其他方面以口头形式理解自然语言的任务。因此,本章和本书中讨论的CLU与文献中的口语理解(SLU)密切相关,有时是同义词。
这里,我们进一步地详细阐述语音识别、CLU/SLU、文本形式的自然语言之间的联系。语音识别不涉及理解,只负责将语言从口语形式转换为文本形式。在下游语言处理系统中,语音识别中的错误可视为“噪音”。处理这类有噪声的NLP问题可以联系到有噪声的语音识别问题,只不过语音识别中的“噪声”来自声环境(而不是识别错误)。
对于有语音输入的SLU和CLU,语音识别中不可避免的错误会使理解比输入为文本或没有语音识别错误的情况更困难,在SLU/CLU研究的历史长河中,由于语音识别错误所带来的困难,使得SLU/CLU的领域比文本形式的语言理解要窄得多。然而,由于最近深度学习在语音识别领域的巨大成功,识别错误已经被大大地降低,导致了目前CLU系统应用领域的拓宽。一类会话理解任务源自于以前的人工智能(AI)工作,比如20世纪60年代建立的MIT Eliza系统,其主要用于聊天系统,模仿理解。例如,如果用户说“我很沮丧”,Eliza会说“你经常沮丧吗?”。另一个极端是使用更深层次的语义构建通用的理解能力,并证明在非常有限的领域中是成功的。这些系统通常是基于大量知识的,并且依赖于形式化的语义解释,即将句子映射到它们的逻辑形式中。在最简单的形式中,逻辑形式是一个句子的上下文无关的表示形式,它涵盖了它的谓语和参数。例如,如果句子是 john loves mary,那么逻辑形式就是 love(john,mary)。循着这些想法,一些研究人员致力于构建通用语义语法(或中间语言),假设所有语言都有一组共享的语义特征。直到90年代末,在统计方法开始占据主导地位之前,这种跨语言方法也严重影响了机器翻译研究。关于基于人工智能技术的语言理解的更多信息,可以看这里。
对CLU进行语义表示,使其不仅覆盖范围广,而且足够简单地能够适用于多个不同的任务和领域,是一个挑战。因此,大多数CLU任务和方法取决于它们设计用于的应用程序和环境(如移动与电视)。在这种“针对性理解”设置中,有三个旨在形成一个语义框架,捕获用户话语/查询语义的关键任务:领域分类(用户在说什么,比如:“旅行”)、意图识别(用户要干什么,比如:“预定一个酒店房间”)、槽位填充(这个任务的参数是什么,比如“迪斯尼乐园附近的两居室套房”)。图2.1显示了一个与航班相关的查询示例语义框架:查找明天飞往波士顿的航班。
 图2.1:一个语义解析的例子,S是槽位,D是领域,I是意图,
图2.1:一个语义解析的例子,S是槽位,D是领域,I是意图,
使用IOB标注方法(in-out--begin)来表示槽位
在本章中,我们将详细回顾最先进的基于深度学习的CLU方法,主要集中在这三个任务上。在下一节中,我们将更正式地提供任务定义,然后介绍前深度学习时代的文献。接下来在2.4节中,将会涵盖针对此任务的最新研究。
2.2 一个历史视角
在美国,基于框架的CLU的研究始于20世纪70年代的DARPA语言理解研究(SUR),然后是资源管理(RM)任务。在这一早期阶段,自然语言理解(NLU)技术,如有限状态机(FSMS)和增强转换网络(ATN)被应用于SLU。
随着美国国防部高级研究计划局(DARPA)航空旅行信息系统(ATIS)项目的评估,针对性的基于帧的SLU的研究在20世纪90年代激增。多个来自于学术界和工业界的研究实验室都开发了试图理解用户航空旅行信息(包括航班信息,地面交通信息,机场服务信息等)的自动语音查询的系统,然后从标准的数据库中获取答复信息。ATIS是基于框架的SLU的重要里程碑,在很大程度上得益于其严格的组件形式和端到端的评估,由多个机构参与,并有一个共同的测试集。后来,通过DARPA通信器程序,对ATIS进行了扩展,以涵盖多轮对话。同时,国际社会在建立一个对话式的计划助手方面也有各自的努力,比如贸易分析信息系统(TRAINS)。而在大西洋的另一边,也在做着相同的努力。法国的EVALDA/MEDIA项目旨在设计和测试评估方法,以比较和诊断口语对话中的上下文相关和上下文无关的SLU能力,参与者包括学术组织(IRIT、LIA、Limsi、Loria、Valoria和Clips)和工业机构(法国电信研发部、Telip)。与ATIS一样,此研究的领域仅限于旅游和酒店信息的数据库查询。最近由欧盟发起的LUNA项目重点关注在先进电信服务背景下实时理解自然语音的问题。
在前深度学习时代,研究者们运用已知的序列分类方法,使用提供的训练数据集来完成应用领域框架槽位的填充,并进行了对比实验。这些方法使用生成模型,如隐马尔可夫模型(HMMs)(Pieraccini等人1992年),判别分类方法(Kuhn和Mori 1995年),基于知识的方法,以及基于概率分布的上下文无关语法(CFG)(Seneff 1992;Ward和Isar 1994),最后是条件随机字场(CRF)(Raymond和Riccardi 2007;Turet al.2010年)。
几乎与槽位填充方法同时,出现了一个相关的CLU任务,主要用于呼叫中心IVR(交互式语音应答)系统中的机器定向对话。在IVR系统中,交互完全由机器控制。机器主动系统会询问用户特定的问题并期望用户输入为预先确定的关键字或短语之一。例如,邮递系统可能会提示用户说,安排取货、跟踪包裹、获取价格或订单供应,或者披萨送货系统可能会要求提供可能的配料。这种IVR系统通常被扩展为在呼叫中心中形成一个机器主动导向的对话,现在被广泛地使用诸如VoiceXML(VXML)等已建立和标准化的平台来实现。
IVR系统的成功,激发了更多复杂精巧的版本,即将用户的话语分类为预先定义的类别(称为呼叫类型或意图),并被几乎所有主要参与者所运用,比如AT&T(Gorin等人1997年、2002年;Gupta等人,2006年)、贝尔实验室(Chu Carroll和Carpenter,1999年)、BBN(Natarajan等人,2002年),以及法国电信(Dammati等人,2007年)。
虽说这是CLU任务的一个完全不同的视角,但它实际上是对框架填充的补充。例如,在ATIS语料库中,有关于地面交通或特定航班上飞机的载客能力的语句,因此用户可能有其他的意图而基本上不会是想要寻找航班信息。
关于前深度学习时代的领域检测、意图识别和槽位填充方法的详细调查,可以在(Tur和Mori,2011年)论文中找到。
2.3 主要的语言理解任务
在本节,我们主要描述用于人机会话系统的目标型会话语言理解的关键任务。其中包括目标检测或者意图识别和槽位填充的话语分类任务。
2.3.1 领域检测和意图识别
在领域检测和意图识别中,语义上的话语分类任务着眼于将一段话X划分到语义分类集合M中的某一个分类,![]() (r是这段话的索引)。通过观察Xr,使给定
(r是这段话的索引)。通过观察Xr,使给定![]() 的后验概率最大。通常表示为:
的后验概率最大。通常表示为:
(2.1)
语义分类器要求在一段话的变化中要有显著的自由度。一个用户可能会说“I want to fly from Boston to New York next week”(我下周要从波士顿飞往纽约),另一个会说“I am looking to flights from JFK to Boston in the coming week”(我在看下周从肯尼迪国际机场飞波士顿的航班)来表达相同的意思。尽管表达存在着自由度,对于在该应用程序中的这些话有着有着清晰的结构,就是将特定的信息片段绑定在一起。不仅用户所能说的话没有先验约束,而且系统应该能够很好的从少量的训练数据中进行归纳。举个例子,短语“Show all flights”和“Give me flights”应该被理解为单一语义分类“Flights”的变体。另一方面,命令“Show me fares”应该被理解为另一个语义分类“Fare”的一个实例。传统的文本分类技术是设计出使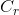 、给定文本
、给定文本![]() 的概率,即后验概率最大化的学习方法。其他语义特征,比如领域索引(实体列表),命名实体(比如组织机构名、时间/日期表示)以及上下文特征(比如上一轮的对话),这些都可以用来丰富特征集。
的概率,即后验概率最大化的学习方法。其他语义特征,比如领域索引(实体列表),命名实体(比如组织机构名、时间/日期表示)以及上下文特征(比如上一轮的对话),这些都可以用来丰富特征集。
2.3.2 槽位填充
一个应用领域的语义结构是根据语义框架定义的,一个语义框架包含多个不同类型的组成部分,称之为“槽位”。比如,在图2.1中,航班这个领域可能包含像出发城市、到达城市、出发日期、航空公司名称等槽位。槽位识别任务就是要在语义框架中实例化这些槽位。
一些SLU系统已经开始采用一种层次表示作为具有更好表示能力和允许子结构共享,这主要受语义成分树所驱动。
在基于统计框架的会话语言理解中,任务通常被形式化为模式识别问题。给定一个单词序列W,槽位填充的目标就是找到一个语义标签序列S,它具有最大的后验概率:
(2.2)
2.4 提升技术水平:从统计建模到深度学习
在这一节中,我们回顾了最近为会话语言理解而进行的基于深度学习的工作,包括一个一个的任务,以及涵盖联合多任务方法。
2.4.1 领域检测和意图识别
第一个话语分类的深度学习应用始于深度置信网络(DBNs)(Hinton 等人,2006年),受到了信息处理应用中多个领域的追捧。深度置信网络是受限玻尔兹曼机(RBMs)的堆栈,然后做了微调(fine-tuning)。RBM是一个两层的网络,可以使用无监督的方式合理有效地训练。沿着RBM这种学习方式,一层层地构建深度模型,DBN在语音和语言处理的很多任务以及最终的呼叫路由设置意图识别(Sarikaya等人, 2011年)中都取得了成功。这项工作已经被扩展到使用额外的无标签数据来进行更好地预训练(Sarikaya等人, 2014年)。随着DBN的成功,邓力和俞栋提出使用深度凸网络(DCN),这直接切中类DBN深度学习技术的可扩展性问题(Deng和Yu,2011年)。DCN显示出优于DBN的表现,不仅是在正确率方面,还在于训练的可扩展性和效率。一个DCN是标准的前馈神经网络,但在每一层隐藏层,输入向量也被考虑了进去。
图2.2给出了一个DCN的概念结构:W表示输入,U表示权重。其中,损失函数使用了均方误差(MSE),给定目标向量T。然而,网络使用了上述的DBN做了预训练。
 图2.2 一个典型DCN结构
图2.2 一个典型DCN结构
在早期工作中,对于输入向量,由于词典太过巨大,作为特征变换的代替,一个基于boosting的特征选择被用于找到分类任务中的关键短语,并将结果和此boosting方法的基线做比较。此后,DBN用于预训练的情况就很少了,现在最先进的做法是使用卷积神经网络(CNNs)以及它的变体(Collobert及Weston,2008年; Kim,2014年; Kalchbrenner等人,2014年,等等)。
图2.3显示了一个典型的CNN句子或话语分类体系。卷积运算涉及一个滤波器U,它应用于输入句中h个单词的窗口,以产生一个新的特征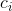 。例如:
。例如:
,
b是偏置,W是单词的输入向量,表示新特征,然后,对 使用最大池化操作,取最大特征值![]() ,这些特征会传递到一个全连接的softmax层,该层的输出是标签上的概率分布:
,这些特征会传递到一个全连接的softmax层,该层的输出是标签上的概率分布:

受循环神经网络(RNNs)的启发,有几项研究试图使用领域检测的方法,再结合CNNs,尝试获得超越两者的最优结果。Lee和Dernoncourt(2016)尝试过建立一个RNN编码器(encoder),此编码器被装进一个前馈神经网络并和常规的CNN进行比较。图2.4显示了使用的基于RNN的编码器的概念模型。
 图2.3 一个典型的CNN架构
图2.3 一个典型的CNN架构
 图2.4 一个用于句子分类的基于RNN-CNN的编码器
图2.4 一个用于句子分类的基于RNN-CNN的编码器
有一个值得注意的工作,Ravuri和Stolcke(2015)没有使用前馈或卷积神经网络来进行话语分类,他们只简单使用RNN编码器来对一段话建模,在这段话中,句子的末尾标记解码了类别,如图2.5所示。虽然他们没有将结果与CNN或简单的DNN进行比较,但这项工作是非常重要的,因为人们可以简单地将这种体系结构扩展到双向RNN。并将句首标记作为类加载,如(Hakkani-Tür等人,2016年)中所述,不仅支持表达意图,还支持向联合语义解析模型填充槽位,这将在下一节中介绍。
 图2.5 一个用于句子分类的基于纯RNN的编码器
图2.5 一个用于句子分类的基于纯RNN的编码器
除了这些具有代表性的建模研究之外,还有一种值得一提的方法是Dauphin等人(2014)的无监督话语分类。这个方法依赖于和他们点击的URL相关联的搜索查询,假设如果查询导致点击类似的URL,那么它们将具有类似的含义或意图。图2.6显示了一个查询点击图的例子。该数据用于训练具有多个隐藏层的简单深层网络,其中的最后一个层应捕获给定查询的潜在意图。注意,这与其他词嵌入的训练方法不同,它可以直接为给定的查询提供嵌入。
然后,零样本分类器会简单地查找嵌入在语义上最接近查询的类别,假设以有意义的方式给出类名(例如,餐馆或运动)。然后,根据查询嵌入的欧几里得距离和类名,通过在所有分类上使用一个softmax,得出属于某一类的概率。
 图2.6 从查询到点击的URL的双分查询点击图
图2.6 从查询到点击的URL的双分查询点击图
2.4.2 槽位填充
槽位填充目前是依赖基于RNN的方法及其变体。早期于RNN的方法包括神经网络马尔科夫模型(NN-MMs)或者带有条件随机场(CRFs)的DNN。在前RNN时代的众多方法中,Deoras和Sarikaya(2013年)曾做过一项研究:使用深度置信网络来进行槽位填充。他们打算使用判别嵌入技术,它会把一个稀疏且大的输入层映射成一个小的、稠密的实数值特征向量,此向量会紧接着被用于预训练网络以及使用局部分类来进行判别分类。Deoras和Sarikaya把这个方法应用于ATIS的口语理解任务研究并获得了SOTA的表现,超越了最好的基于CRF的系统。
CNN被用来做特征抽取并且在学习句子语义上的变现也还不错。CNN还被用来学习槽位标签的隐藏特征。Xu和Sarikaya (2013年)曾做过一项研究,他们使用CNN作为一个抽取每个词与相邻词之间关系、获得局部语义的较下层![]() ,一个CRF层位于CNN层之上,CNN为其提供隐藏特征。整个网络通过反向传播进行端到端的训练,并且应用于个人助手领域。他们的研究结果表明,相对于标准的CRF模型有显著的改进,同时在领域专家的特征工程中提供了灵活性。
,一个CRF层位于CNN层之上,CNN为其提供隐藏特征。整个网络通过反向传播进行端到端的训练,并且应用于个人助手领域。他们的研究结果表明,相对于标准的CRF模型有显著的改进,同时在领域专家的特征工程中提供了灵活性。
随着基于RNN模型的发展,他们首先被Yao和Mensil等人用于槽位填充。例如,Mesnil等人实现并比较了若干RNN结构,包括Elman型(1990)RNN和Jordan型(1997)RNN以及它们的变体。实验结果表明,总体上二者都具有相似的性能并且超越了广泛使用的CRF的基线。此外,结果也表明双向RNN考虑到了插槽间过去和未来的依赖性,因此性能最好。在这两篇论文中也同时研究了用于槽位填充RNN中的词嵌入的有效性。Mensil等人在2015年的论文中对这项工作进行了进一步的研究,作者对标准RNN结构、混合、双向、CRF拓展的RNN结构进行了全面的评估,并在这方面获得了新的SOTA。
更正式一点地说,如在Raymond和Riccardi(2007)的论文中所提,以IOB的形式对标签序列 ![]() 进行标记(三个输出对应"B","I","O")。如图2.1所示,对应一个输入词序列
进行标记(三个输出对应"B","I","O")。如图2.1所示,对应一个输入词序列 ![]() ,Elman RNN结构包含一个输入层,多个隐层和一个输出层。输入、隐藏、输入层都有一套神经元来分别表示每一个时序t的输入、隐藏状态、输出
,Elman RNN结构包含一个输入层,多个隐层和一个输出层。输入、隐藏、输入层都有一套神经元来分别表示每一个时序t的输入、隐藏状态、输出 ![]() ,输入用典型的one-hot向量或者词级别的嵌入来表示,给定输入层
,输入用典型的one-hot向量或者词级别的嵌入来表示,给定输入层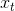 ,时刻t,以及前一时序的隐藏状态
,时刻t,以及前一时序的隐藏状态  ,当前时刻的隐层和输出层计算方式如下:
,当前时刻的隐层和输出层计算方式如下:
![]()
![]()
![]()
其中,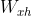 和
和![]() 分别表示输入和隐层、隐层和输出层之间的权重,φ表示激活函数,比如tanh或者sigmoid。
分别表示输入和隐层、隐层和输出层之间的权重,φ表示激活函数,比如tanh或者sigmoid。
与之相反,Joadan RNN从上一时序的输出层加上当前时序的输入层计算当前时序的递归隐藏层:
![]()
前馈神经网络结构、ElmanRNN、JordanRNN在图2.7中做了解释:
 图2.7 a. 前馈神经网络 b. Elman RNN c. Jordan RNN
图2.7 a. 前馈神经网络 b. Elman RNN c. Jordan RNN
另一种方法是用显式的序列级优化来增强这些功能, 这很重要,举个例子,一个模型可以建模为:一个"I"标签后面不能跟一个"O"标签。Liu和Lane(2015) 提出一种隐藏状态也利用之前预测结果的结构,如图2.8所示:
 图2.8 基于RNN的序列级优化
图2.8 基于RNN的序列级优化
![]() ,
,
其中,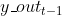 为在t-1时刻,表示输出标签的向量,Q是连接输出标签和隐层的权重矩阵。
为在t-1时刻,表示输出标签的向量,Q是连接输出标签和隐层的权重矩阵。
这里也应该提一下,最近Dupont等人(2017)的一篇论文,里面提出了一个新的RNN结构变体,其输出标签也被接入下一个输入。
尤其随着RNN的LSTM单元的再次发现,这种结构开始出现了(Yao等人,2014)。LSTM单元结构显示出了优越的性能,例如:更快得收敛以及用自正则化方法消除序列中梯度的消失或爆炸问题。
在Mesnil等人(2015)论文中已经做了关于基于RNN的槽位填充方法的全面回顾,虽然前期LSTM/GRU-RNN的研究主要集中在前瞻性和回顾性特征上(例如 Mesnil et al. 2013; Vu et al. 2016),但目前最先进的槽位填充方法通常依赖于双向LSTM/GRU模型等(Hakkani-Tür et al. 2016; Mesnil et al. 2015; Kurata et al. 2016a; Vu et al. 2016;Vukotic et al. 2016)。
扩展研究包括encoder-decoder模型(其中包括Liu and Lane 2016; Zhu and Yu2016a)或者记忆(Chen et al. 2016),我们将在下面进行描述。在这方面,常用的句子编码包括:基于序列的递归神经网络,它具有lstms或gru单元,它们按顺序在句子上积累信息;卷积神经网络,在短的单词或字符的局部序列上使用滤波器积累信息;树结构递归神经网络(RecNNs),将信息传播到二进制解析树上(Socher et al. 2011; Bowman et al. 2016)。
有两篇和RecNNs有关的论文在这值得一提,第一篇来自Guo等人(2014)的论文,它标记的是输入句子的句法分析结构而不是词。概念图如图2.9所示。每个词都与一个词向量相关联,这些向量作为输入传进网络的底部。然后,网络通过在每个节点上重复使用一个神经网络,向上传播信息,直到根节点输出单个向量。然后将该向量用作语义分类器的输入,并且通过反向传播来训练网络以最大化该分类器的性能,非结束符对应于要填充的槽位,并且在整个句子的顶部可以根据意图或领域进行分类。
 图2.9 句法解析树之上的递归神经网络
图2.9 句法解析树之上的递归神经网络
虽然这种体系结构非常优雅且昂贵,但由于以下各种原因,它并没有获得优异的性能:(i)底层的解析树可能会有噪声,并且模型不能联合训练语法和语义解析器;(ii)短语不一定与槽位一一对应,以及(iii)不考虑高级标记序列,因此需要最终的viterbi层。因此,理想的架构应该是一个混合的RNN/RecNN模型。
Andreas等人(2016)提出了一种关于问答更有前途的方法,如图2.10所示,语义分析是利用任务中的六个关键逻辑函数的对应于神经模块的组合来建立的,即查找、查找、关联、存在和描述。一个相较RecNNs的优点是,模型在使用这些原始语料的训练中,从现有句法分析器开始,共同学习解析的结构或设计。
Vu等人(2016)曾提出使用一个排序损失函数,而不是传统的交叉熵损失。 这样做的一个好处是不会强迫模型学习人工制造的类别"O"(可能都不存在),模型学习到如何在给定一个数据点x,使得真实标签y和最有可能的标签c之间的距离最大化,目标函数为:
![]() ,
,
其中![]() 和
和![]() 分别是标签类别y和c的得分,参数γ控制着预测错误的惩罚,
分别是标签类别y和c的得分,参数γ控制着预测错误的惩罚,![]() 和
和![]() 是正确标签与错误标签之间的差。γ、
是正确标签与错误标签之间的差。γ、![]() 和
和![]() 都是在开发集上可以调整的超参数。对于标签类别"O",只有第二项会被进行求和计算,这样一来,模型就不会学到"O"类别,但会增加和最有竞争力的标签之间的差距。在测试中,如果其他所有类别的得分都小于0,那么模型就会预测为"O"类别。
都是在开发集上可以调整的超参数。对于标签类别"O",只有第二项会被进行求和计算,这样一来,模型就不会学到"O"类别,但会增加和最有竞争力的标签之间的差距。在测试中,如果其他所有类别的得分都小于0,那么模型就会预测为"O"类别。
除了标签LSTM模型,有几项侧重于编/解码RNN结构的研究,这些研究基于以下相似研究的改进:(Sutskever et al. 2014; Vinyals and Le 2015). Kurata et al. (2016b) 提出了如图2.11所示的结构,其中输入句子被编码器LSTM编码为一个固定长度的向量。然后标记LSTM会预测出槽位标签序列,标记LSTM的隐状态被编码LSTM初始化为编码向量。通过这种编码-标记LSTM,就可以使用整句嵌入来明确地预测出标签序列。
 图2.11 同时用于词和标签的编/解码RNN
图2.11 同时用于词和标签的编/解码RNN
注意,在该模型中,由于输出是通常的标记序列,除了先前的预测之外,单词还被输入到标记器(与其他编码器/解码器研究通常所做的相反)。
这种方法的另一个好处来自(Simonnet et al. 2015),其中解码器可以在标记时处理较长距离的依赖关系。注意力是另一个向量c,它可以为处于编码端的所有隐藏状态嵌入分配权重。决定这些权重的方式有多种:
考虑一个例句:flights departing from london no later than next Saturday afternoon ,词 afternoon的标签是departure_time 并且已经在第一个动词后八个词开外了,在这种情况下,注意力机制就很有用了。
Zhu and Yu (2016b) 使用“focus”(或称“直接注意力”)机制进一步拓展了编码器/解码器,“focus”机制强调对齐的编码器隐藏状态,换句话说,注意力不再是学习到的,而是分配给了相关的隐藏状态:
![]() .
.
Zhai et al. (2017) 后来对使用了指针网络(Vinyals et al. 2015)的编码器/解码器结构在输入句子的分语块输出上进行了拓展。其主要动机在于RNN模型仍需要用IOB体系独立处理每一个标记,而不是一个完整的单元。如果我们能消除这个缺点,就可以得到更精确的标记,特别是对于多字词语块。序列分块是解决这个问题的常规方法。在序列分块中,最初的序列标记任务分为两个子任务:(1)分割,以明确标识块的范围。(2)标记,根据分割结果将每个块标记为单个单元。因此,作者提出了一种联合模型,该模型在编码阶段对输入语句进行分块,解码器只需标记这些语块,如图2.12所示。
 图2.12 使用分块输入的指针编码器/解码器RNN
图2.12 使用分块输入的指针编码器/解码器RNN
关于槽位填充模型的无监督训练,来自Bapna et al. (2017) 的一篇论文值得一提。他提出了一个方法,这个方法可以只利用上下文的槽位描述,不需要任何已标记或未标记的领域内样本,即可快速引导新领域。这项工作的主要思想是利用多任务深度学习的槽位填充模型中槽位名称和描述的编码,在假设已经训练好的背景模型的情况下,隐式地跨域对齐槽位。
若一个以覆盖的领域含有一个相似的槽位,从共享预训练嵌入获得的槽位的连续表示,可用于领域不可知模型。一个简单的例子就是当一个已经解析关于美国航空和土耳其航空的询问时可以再加入美国联合航空进去。虽然槽位名称可能有所不同,但始发城市或到达城市的概念应保持不变,并可使用其自然语言描述迁移到美国联合航空的新任务中。这种方法有希望解决领域缩放问题,并消除任何手动注释数据或显式模式对齐的需要。
2.4.3 联合任务多领域模型
历史上,意图识别被视为样本分类问题,槽位填充被视为序列分类问题![]() 。在前深度学习时代,这两个任务的解决方案通常不一样,采用分别建模。举个例子,SVM用于意图识别而CRF用于槽位填充。随着深度学习的发展,现在可以以多任务的方式使用单个模型获得整个语义解析。这允许槽位决策帮助确定意图,反之亦然。
。在前深度学习时代,这两个任务的解决方案通常不一样,采用分别建模。举个例子,SVM用于意图识别而CRF用于槽位填充。随着深度学习的发展,现在可以以多任务的方式使用单个模型获得整个语义解析。这允许槽位决策帮助确定意图,反之亦然。
此外,领域分类通常率先完成,作为后续处理的顶级分类。然后对每一个领域进行意图识别和槽位填充,以填充特定领域的语义模板。这种模块化的设计方法(如将语义分析建模为三个独立的任务)具有灵活性的优点,对特定领域的修改(如插入、删除)也无需更改其他领域。另一个好处是,在这个方法中可以使用特定任务或领域的特征,这些特征可以显著提高这些特定任务或领域模型的精度。同样,这个方法常常会把更多的理解集中在每一个领域上,因为意图识别只需相对较小的意图集和单个(或有限)领域上的槽位类别并且模型参数可以针对特定的意图集和槽位集进行优化。
然而,这个方法也有缺点:首先,需要为每一个领域训练一个模型,这是一个容易出错的过程,需要仔细设计以确保跨领域处理的一致性。另外,在运行时,这样的任务流水线导致错误从一个任务传递到下一个任务,此外,各个领域模型之间没有数据或特征共享,导致数据碎片化,而一些语义意图,此外,各个领域模型之间没有数据或特征共享,导致数据碎片化,而一些语义意图(例如,找到或购买特定于领域的实体)和槽位(例如日期、时间和地点)实际上可能对许多领域是通用的 (Kim et al. 2015; Chen et al. 2015a)。最后,用户可能不知道系统覆盖了哪些域以及覆盖的范围,因此这个问题会导致用户不知道期望什么的交互,从而导致用户不满意(Chen et al. 2013, 2015b)。
为此,Hakkani-Tür 等人(2016)提出了一种单一RNN结构,将领域检测、意图识别和多个领域的槽位填充这三个任务集成到一个RNN模型中。该模型使用来自所有领域的所有可用话语和它们的语义框架进行训练。这个RNN的输入是单词的输入序列(例如,用户查询),输出是完整的语义框架,包括领域、意图和槽位,如图2.13所示,这类似于Tafforeau等人(2016)的多任务解析和实体提取工作。
对于领域、意图和槽位的联合建模,在每个输入语句k的开头和结尾插入一个额外的标记: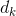 和意图标签
和意图标签  的组合,与该语句的初始及最终标记(
的组合,与该语句的初始及最终标记(
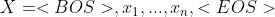
![]() ,
,
其中,X是输入,Y是输出(图2.13)。
 图2.13 用于领域检测、意图识别、槽位填充联合模型的双向RNN
图2.13 用于领域检测、意图识别、槽位填充联合模型的双向RNN
这种思想的主要原理与机器翻译(Sutskever et al. 2014)或者聊天系统(Vinyalsand Le 2015)方法中使用的序列到序列的建模方法相似:query的最后一层隐层(在每一个方向)包含整个输入语句的隐含语义表示,所以可以用于领域和意图预测。(,)
Zhang和Wang(2016)扩展了该体系结构,以便添加一个最大池化层,用于捕获句子的全局特征以进行意图分类(图2.14)。训练时使用联合损失函数,它是用于槽位填充和意图确定的交叉熵的加权和。
Liu和Lane(2016)提出了基于编码器/解码器架构的联合槽位填充和意图确定模型,如图2.15所示。它基本上是一个多头模型,用任务特定的注意力共享句子编码器.
注意,这种联合建模方法对于扩展到新的领域非常有用,从从多个领域训练的更大的背景模型开始,类似于语言模型适应(Bellegarda 2004)。Jaech等人(2016年)提出了这样一项研究,即利用多任务方法,通过转移学习进行可扩展的CLU模型训练。可扩展性的关键是减少学习新任务模型所需的训练数据量。提出的多任务模型通过利用从其他任务中学习到的模式,以较少的数据提供更好的性能。该方法支持一个开放的词汇表,它允许模型将未看到的单词泛化,这在使用很少的训练数据时尤为重要。
 图2.15 基于编解码模型的联合槽位填充与意图确定模型
图2.15 基于编解码模型的联合槽位填充与意图确定模型
2.4.4 在语境中理解
自然语言理解包括理解语言使用的语境,但是理解语境包括多重挑战。首先,在许多语言中,某些词可以用在多种意义上。这就使得消除所有这些词的歧义非常重要,这样它们在特定文档中的用法就可以被准确地检测出来。词义消歧是自然语言处理中一个正在进行的研究领域,在构建自然语言理解系统时尤为重要。其次,理解任务涉及来自不同领域的文件,如旅行预订、理解法律文件、新闻文章、arxiv文章等。这些领域中的每一个都具有特定的属性,因此自然语言理解模型应该学习捕捉领域特定的上下文。第三,在口语和书面语中,许多词被用作其他概念的替代。例如,最常用的,“Xerox”(施乐复印机)之于“copy”(复印件)或者“fedex”(联邦快递)之于“overnight courier”(通宵快递员)等等。最后,文档包含的单词或短语涉及到文本中未明确包含的知识,只有用智能的方法,我们才能学会使用“先验”知识来理解文本中存在的信息。
最近,深度学习架构已经被应用到各种自然语言处理任务中,并显示出在上下文中捕获单元的相关语义和句法方面的优势。因此其目标是将分布的短语级表示扩展到单句和多句(语篇)的层次,并生成整个文本的层次结构。
为了在自然语言文本中学习语境,Hori等人(2014)提出了一种基于角色的LSTM层的高效的、上下文敏感的口语理解方法。具体地说,为了在对话中准确地理解说话人的意图,重要的是要考虑到在对话中上下文句子的前后顺序。在他们的工作中,LSTM递归神经网络被用来训练一个上下文敏感的模型,从口语序列中预测对话概念序列。因此,为了捕获整个对话中的长期特性,他们使用每个概念标签的后续词序列实现了表示意图的LSTM。为了训练该模型,他们从人与人对话语料中建立了LSTM,这些语料中带有表示客户和中介预定酒店意图的概念标签。这些表达是通过中介和客户的每一个角色所描述的。
如图2.16所示,有两个LSTM层具有不同的参数,这取决于说话人角色。因此,输入向量就被表示客户说的话的左侧层和中介说的话的右侧层进行不同地处理,以表示这些不同的角色。因此,循环LSTM的输入接收从在前一步激活了的角色相关层的输出,且允许角色间转换。这种方法可以通过描述不同角色之间不同的话语表达,从智能语言理解系统中学习模型上下文。
 图2.16 具有角色相关层的LSTM。层(A)对应于客户话语状态,
图2.16 具有角色相关层的LSTM。层(A)对应于客户话语状态,
层(B)对应于中介话语状态。角色门控制哪个角色处于活动状态
在(Chen et al. 2016)中,提出了最早的基于端到端神经网络的会话理解模型,该模型利用记忆网络提取先验信息作为上下文知识,用于编码器理解会话对话中的自然语言话语。如图2.17所示,它们的方法与基于RNN的编码器相结合,后者在分析来自对话的话语之前,学习从可能很大的外部存储器中编码先前的信息。只要有输入语句及其对应的语义标记,就可以直接从输入-输出对端到端地训练它们的模型,采用端到端的神经网络模型对多轮口语理解的长期知识转移进行建模。
 图2.17 用于多轮口语理解的端到端存储网络模型
图2.17 用于多轮口语理解的端到端存储网络模型
CITEANKUR:ARXIV17已经使用分层对话编码器扩展了该方法,这种递阶递归编码器-解码器(HRID)的扩展是由Sordoni等人(2015)提出的,其中查询级编码与当前话语的表示相结合,然后将其输入会话级编码器。在所提出的体系结构中,编码器采用了一个前馈网络,其输入是上下文中的当前和先前的语句,而不是简单的基于余弦的记忆网络,该前馈网络随后被馈入RNN,如图2.18所示。更正式地说,当前语句编码c与每一个记忆向量 做了合并,对于1,...,
做了合并,对于1,..., ,通过拼接并将它们传入前向(FF)层来生成上下文编码,用
,通过拼接并将它们传入前向(FF)层来生成上下文编码,用![]() 表示:
表示:
![]()
对于0,...,t-1,这些上下文编码作为token![]() 级输入,被输入进双向GRU RNN会话编码器。最终的会话编码器状态代表了对话上下文编码
级输入,被输入进双向GRU RNN会话编码器。最终的会话编码器状态代表了对话上下文编码 。
。
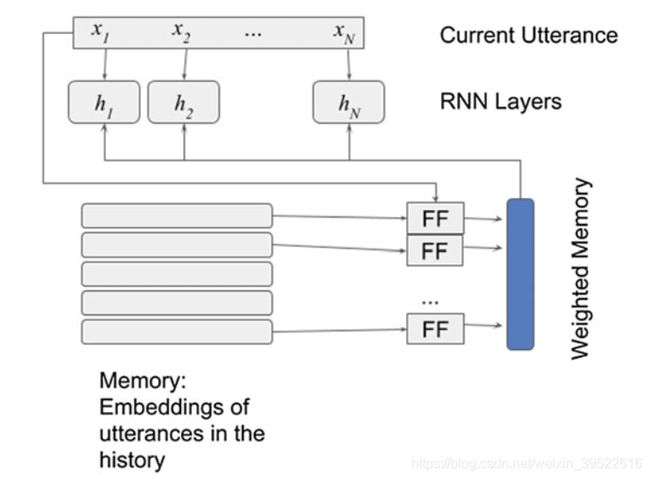 图2.18 分层对话编码网络的体系结构
图2.18 分层对话编码网络的体系结构
正如本章前面提到的,CNNs主要用于自然语言理解任务中,以学习在其他方面不可能学习的潜在特征。Celikyilmaz等人(2016)介绍了一种用于深度神经网络模型的预训练方法,该方法特别使用了CNNs从大量未标记的数据中联合学习作为网络结构的上下文,同时学习从标记序列中预测特定任务的上下文信息。他们拓展了(Xu and Sarikaya 2013)的带有CRF的有监督CNN结构,使用CNN作为最下层来从标记或未标记的序列中,通过半监督学习的方式学习特征表示。在最上层,他们使用两个CRF结构将输出序列解码为语义槽位标签,并将每个单词的潜在分类标签解码为输出序列。这使得网络能够同时学习单个模型中槽位标签的过渡和辐射权重和词的类别标签。
2.5 总结
基于深度学习的方法在两个维度上引领了CLU领域的发展。第一个维度是端到端学习。会话理解是整个会话系统的众多子系统中的其中之一,比如它拿语音识别结果作为输入,其输出会被传入会话管理器用于状态追踪和回应生成。因此,一个在整个对话系统上的端到端的优化设计往往会带来更好的用户体验。He和Deng(2013)讨论过一个用于整体系统设计的面向优化的统计框架,该设计利用了每一个子系统输出的不确定性和子系统之间的交互性。在这个框架中,将各个子系统的参数视为相互关联,并进行端到端的训练,以优化整个会话系统的最终性能指标。此外,最近,基于强化学习的方法结合用户模拟器也开始进入CLU任务,提供无缝的端到端自然语言对话(见下一章)。
第二个维度是通过深度学习实现的高效编码器,无需RNN展开。RNNs是一种强大的模型,能够处理自然语言、语音、视频等序列数据。有了RNN,我们现在可以理解序列数据并做出决策。传统的神经网络是无状态的,它使用一个固定的向量作为输入并产生一个向量作为输出。因RNN具有独一无二的状态属性,得以使其在今天成为语言理解系统最有用的工具。
没有隐藏层的网络在它们可以建模的输入-输出的映射中非常有局限性。添加一层手工编码的特征(如在感知器中)会使它们更加强大,但最困难的是设计这些特征。我们希望在不需要深入了解任务或反复试错的情况下找到好的特征。我们需要自动化试错特征设计闭环。强化学习可以通过扰动权值来学习这种结构,强化学习对深度学习的帮助其实并不复杂,他们随机扰动一个权重,看看它是否提高了性能如果是,保存更改。这可能是低效的,因此机器学习社区,特别是在深度强化学习中,近年来一直关注这一点。
由于已知自然语言句子中的意义是根据树结构递归构造的,因此更有效的编码器在于研究树结构神经网络编码器,特别是TreeLSTMs(Socher et al. 2011; Bowman et al. 2016)。其思想是能够在保持效率的同时,更快、更有效地编码。另一方面,可以结合模块参数本身学习网络结构预测器的模型表明,在减少较长文本序列带来的问题的同时,提高了自然语言理解能力,从而减少了RNNs中的反向传播。Andreas等人(2016) 提出了一种使用自然语言字符串从一组可组合模块中自动组装神经网络的模型。这些模块的参数通过强化学习与网络装配参数一起学习,只用(世界,问题,答案)三元组作为监督。
总之,我们相信深度学习的进步为人类/机器对话系统,特别是CLU带来了令人兴奋的新研究领域。这里提到的研究将被认为是在接下来的十年里,用手工标注的数据来处理小型任务。对于任何高质量的可扩展CLU解决方案,未来的研究将包括迁移学习、无监督学习和强化学习。
References
Allen, J. (1995). Natural language understanding, chapter 8. Benjamin/Cummings.
Allen, J. F., Miller, B. W., Ringger, E. K., & Sikorski, T. (1996). A robust system for natural spoken
dialogue. In Proceedings of the Annual Meeting of the Association for Computational Linguistics,pp. 62–70.
Andreas, J., Rohrbach, M., Darrell, T., & Klein, D. (2016). Learning to compose neural networks for question answering. In Proceedings of NAACL.
Bapna, A., Tur, G., Hakkani-Tur, D., & Heck, L. (2017). Towards zero-shot frame semantic parsing for domain scaling. In Proceedings of the Interspeech.
Bellegarda, J. R. (2004). Statistical language model adaptation: Review and perspectives. Speech Communication Special Issue on Adaptation Methods for Speech Recognition, 42, 93–108.
Bonneau-Maynard, H., Rosset, S., Ayache, C., Kuhn, A., & Mostefa, D. (2005). Semantic annotation of the French MEDIA dialog corpus. In Proceedings of the Interspeech, Lisbon, Portugal.
Bowman, S. R., Gauthier, J., Rastogi, A., Gupta, R., & Manning, C. D. (2016). A fast unified model for parsing and sentence understanding. In Proceedings of ACL.
Celikyilmaz, A., Sarikaya, R., Hakkani, D., Liu, X., Ramesh, N., & Tur, G. (2016). A new pretraining method for training deep learning models with application to spoken language understanding. In Proceedings of The 17th Annual Meeting of the International Speech Communication Association (INTERSPEECH 2016).
Chen, Y.-N., Hakkani-Tur, D., & He, X. (2015a). Zero-shot learning of intent embeddings for expansion by convolutional deep structured semanticmodels.In Proceedings of theIEEEICASSP.
Chen, Y.-N., Hakkani-Tür, D., Tur, G., Gao, J., & Deng, L. (2016). End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding. In Proceedings of the Interspeech, San Francisco, CA.
Chen, Y.-N., Wang, W. Y., Gershman, A., & Rudnicky, A. I. (2015b). Matrix factorization with knowledge graph propagation for unsupervised spoken language understanding. In Proceedings of the ACLIJCNLP.
Chen, Y.-N., Wang, W. Y., & Rudnicky, A. I. (2013). Unsupervised induction and filling of semantic slots for spoken dialogue systems using frame-semantic parsing. In Proceedings of the IEEE ASRU.
Chomsky, N. (1965). Aspects of the theory of syntax. Cambridge, MA: MIT Press.
Chu-Carroll, J., & Carpenter, B. (1999). Vector-based natural language call routing. Computational Linguistics, 25(3), 361–388.
Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the ICML, Helsinki, Finland.
Dahl, D. A., Bates, M., Brown, M., Fisher, W., Hunicke-Smith, K., Pallett, D., et al. (1994). Expanding the scope of the ATIS task: the ATIS-3 corpus. In Proceedings of the Human Language Technology Workshop. Morgan Kaufmann.
Damnati, G., Bechet, F., & de Mori, R. (2007). Spoken language understanding strategies on the france telecom 3000 voice agency corpus. In Proceedings of the ICASSP, Honolulu, HI.
Dauphin, Y., Tur, G., Hakkani-Tür, D., & Heck, L. (2014). Zero-shot learning and clustering for semantic utterance classification. In Proceedings of the ICLR.
Deng, L., & Li, X. (2013). Machine learning paradigms for speech recognition: An overview. IEEE Transactions on Audio, Speech, and Language Processing, 21(5), 1060–1089.
Deng, L., & O’Shaughnessy, D. (2003). Speech processing: A dynamic and optimization-oriented approach. Marcel Dekker, New York: Publisher.
Deng, L., & Yu, D. (2011). Deep convex nets: A scalable architecture for speech pattern classification. In Proceedings of the Interspeech, Florence, Italy.
Deoras, A., & Sarikaya, R. (2013). Deep belief network based semantic taggers for spoken language understanding. In Proceedings of the IEEE Interspeech, Lyon, France.
Dupont, Y., Dinarelli, M., & Tellier, I. (2017). Label-dependencies aware recurrent neural networks. arXiv preprint arXiv:1706.01740.
Elman, J. L. (1990). Finding structure in time. Cognitive science, 14(2), 179–211.
Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139.
Gorin, A. L., Abella, A., Alonso, T., Riccardi, G., & Wright, J. H. (2002). Automated natural spoken dialog. IEEE Computer Magazine, 35(4), 51–56.
Gorin, A. L., Riccardi, G., & Wright, J. H. (1997). How may I help you? Speech Communication, 23, 113–127.
Guo, D., Tur, G., Yih, W.-t., & Zweig, G. (2014). Joint semantic utterance classification and slot filling with recursive neural networks. In In Proceedings of the IEEE SLT Workshop.
Gupta, N., Tur, G., Hakkani-Tür, D., Bangalore, S., Riccardi, G., & Rahim, M. (2006). The AT&T spoken language understanding system. IEEE Transactions on Audio, Speech, and Language Processing, 14(1), 213–222.
Hahn, S., Dinarelli, M., Raymond, C., Lefevre, F., Lehnen, P., Mori, R. D., et al. (2011). Comparing stochastic approaches to spoken language understanding in multiple languages. IEEE Transactions on Audio, Speech, and Language Processing, 19(6), 1569–1583.
Hakkani-Tür, D., Tur, G., Celikyilmaz, A., Chen, Y.-N., Gao, J., Deng, L., & Wang, Y.-Y. (2016). Multi-domain joint semantic frame parsing using bi-directional RNN-LSTM. In Proceedings of the Interspeech, San Francisco, CA.
He, X., & Deng, L. (2011). Speech recognition, machine translation, and speech translation a unified discriminative learning paradigm. In IEEE Signal Processing Magazine, 28(5), 126–133.
He, X. & Deng, L. (2013). Speech-centric information processing: An optimization-oriented approach. In Proceedings of the IEEE, 101(5), 1116–1135.
Hemphill, C. T., Godfrey, J. J., & Doddington, G. R. (1990). The ATIS spoken language systems pilot corpus. In Proceedings of the Workshop on Speech and Natural Language, HLT’90, pp. 96–101, Morristown, NJ, USA. Association for Computational Linguistics.
Hinton, G., Deng, L., Yu, D., Dahl, G., Rahman Mohamed, A., Jaitly, N., et al. (2012). Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29(6), 82–97.
Hinton, G. E., Osindero, S., & Teh, Y. W. (2006). A fast learning algorithm for deep belief nets. Advances in Neural Computation, 18(7), 1527–1554.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8),1735–1780.
Hori, C., Hori, T., Watanabe, S., & Hershey, J. R. (2014). Context sensitive spoken language understanding using role dependent lstm layers. In Proceedings of the Machine Learning for SLU Interaction NIPS 2015 Workshop.
Huang, X., & Deng, L. (2010). An overview of modern speech recognition. In Handbook of Natural Language Processing, Second Edition, Chapter 15.
Jaech, A., Heck, L., & Ostendorf, M. (2016). Domain adaptation of recurrent neural networks for natural language understanding. In Proceedings of the Interspeech, San Francisco, CA.
Jordan, M. (1997). Serial order: A parallel distributed processing approach. Technical Report 8604, University of California San Diego, Institute of Computer Science.
Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A convolutional neural network for modelling sentences. In Proceedings of the ACL, Baltimore, MD.
Kim, Y. (2014). Convolutional neural networks for sentence classification. In Proceedings of the EMNLP, Doha, Qatar.
Kim, Y.-B., Stratos, K., Sarikaya, R., & Jeong, M. (2015). New transfer learning techniques for disparate label sets. In Proceedings of the ACL-IJCNLP.
Kuhn, R., & Mori, R. D. (1995). The application of semantic classification trees to natural language understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 17, 449–460.
Kurata, G., Xiang, B., Zhou, B., & Yu, M. (2016a). Leveraging sentence-level information with encoder LSTM for semantic slot filling. In Proceedings of the EMNLP, Austin, TX.
Kurata, G., Xiang, B., Zhou, B., & Yu, M. (2016b). Leveraging sentence-level information with encoder lstm for semantic slot filling. arXiv preprint arXiv:1601.01530.
Lee, J. Y., & Dernoncourt, F. (2016). Sequential short-text classification with recurrent and convolutional neural networks. In Proceedings of the NAACL.
Li, J., Deng, L., Gong, Y., & Haeb-Umbach, R. (2014). An overview of noise-robust automatic speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(4), 745–777.
Liu, B., & Lane, I. (2015). Recurrent neural network structured output prediction for spoken language understanding. In Proc: NIPS Workshop on Machine Learning for Spoken Language Understanding and Interactions.
Liu, B., & Lane, I. (2016). Attention-based recurrent neural network models for joint intent detection and slot filling. In Proceedings of the Interspeech, San Francisco, CA.
Mesnil, G., Dauphin, Y., Yao, K., Bengio, Y., Deng, L., Hakkani-Tür, D., et al. (2015). Using recurrent neural networks for slot filling in spoken language understanding. IEEE Transactions on Audio, Speech, and Language Processing, 23(3), 530–539.
Mesnil, G., He, X., Deng, L., & Bengio, Y. (2013). Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding. In Proceedings of the Interspeech, Lyon, France.
Natarajan, P., Prasad, R., Suhm, B., & McCarthy, D. (2002). Speech enabled natural language call routing: BBN call director. In Proceedings of the ICSLP, Denver, CO.
Pieraccini, R., Tzoukermann, E., Gorelov, Z., Gauvain, J.-L., Levin, E., Lee, C.-H., et al. (1992). A speech understanding system based on statistical representation of semantics. In Proceedings of the ICASSP, San Francisco, CA.
Price, P. J. (1990). Evaluation of spoken language systems: The ATIS domain. In Proceedings of the DARPA Workshop on Speech and Natural Language, Hidden Valley, PA.
Ravuri, S., & Stolcke, A. (2015). Recurrent neural network and lstm models for lexical utterance classification. In Proceedings of the Interspeech.
Raymond, C., & Riccardi, G. (2007). Generative and discriminative algorithms for spoken language understanding. In Proceedings of the Interspeech, Antwerp, Belgium.
Sarikaya, R., Hinton, G. E., & Deoras, A. (2014). Application of deep belief networks for natural language understanding. IEEE Transactions on Audio, Speech, and Language Processing, 22(4).
Sarikaya, R., Hinton, G. E., & Ramabhadran, B. (2011). Deep belief nets for natural language call-routing. In Proceedings of the ICASSP, Prague, Czech Republic.
Seneff, S. (1992). TINA: A natural language system for spoken language applications. Computational Linguistics, 18(1), 61–86.
Simonnet, E., Camelin, N., Deleglise, P., & Esteve, Y. (2015). Exploring the use of attentionbased recurrent neural networks for spoken language understanding. In Proceedings of the NIPS Workshop on Machine Learning for Spoken Language Understanding and Interaction.
Socher, R., Lin, C. C., Ng, A. Y., & Manning, C. D. (2011). Parsing natural scenes and natural language with recursive neural networks. In Proceedings of ICML.
Sordoni, A., Bengio, Y., Vahabi, H., Lioma, C., Simonsen, J. G., & Nie, J.-Y. (2015). A hierarchical recurrent encoder-decoder for generative context-aware query suggestion. In Proceedings of the ACM CIKM.
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Advances in neural information processing systems 27, chapter Sequence to sequence learning with neural networks.
Tafforeau, J., Bechet, F., Artiere1, T., & Favre, B. (2016). Joint syntactic and semantic analysis with a multitask deep learning framework for spoken language understanding. In Proceedings of the Interspeech, San Francisco, CA.
Tur, G., & Deng, L. (2011). Intent determination and spoken utterance classification, Chapter 4 in book: Spoken language understanding. New York, NY: Wiley.
Tur, G., Hakkani-Tür, D., & Heck, L. (2010). What is left to be understood in ATIS? In Proceedings of the IEEE SLT Workshop, Berkeley, CA.
Tur, G., & Mori, R. D. (Eds.). (2011). Spoken language understanding: Systems for extracting semantic information from speech. New York, NY: Wiley.
Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer networks. In Proceedings of the NIPS.
Vinyals, O., & Le, Q. V. (2015). A neural conversational model. In Proceedings of the ICML.
Vu, N. T., Gupta, P., Adel, H., & Schütze, H. (2016). Bi-directional recurrent neural network with ranking loss for spoken language understanding. In Proceedings of the IEEE ICASSP, Shanghai,China.
Vukotic, V., Raymond, C., & Gravier, G. (2016). A step beyond local observations with a dialog aware bidirectional gru network for spoken language understanding. In Proceedings of the Interspeech, San Francisco, CA.
Walker, M., Aberdeen, J., Boland, J., Bratt, E., Garofolo, J., Hirschman, L., et al. (2001). DARPA communicator dialog travel planning systems: The June 2000 data collection. In Proceedings of the Eurospeech Conference.
Wang, Y., Deng, L., & Acero, A. (2011). Semantic frame based spoken language understanding, Chapter 3. New York, NY: Wiley.
Ward, W., & Issar, S. (1994). Recent improvements in the CMU spoken language understanding system. In Proceedings of the ARPA HLT Workshop, pages 213–216.
Weizenbaum, J. (1966). Eliza—A computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1), 36–45.
Woods, W. A. (1983). Language processing for speech understanding. Prentice-Hall International, Englewood Cliffs, NJ: In Computer Speech Processing.
Xu, P., & Sarikaya, R. (2013). Convolutional neural network based triangular crf for joint intent detection and slot filling. In Proceedings of the IEEE ASRU.
Yao, K., Peng, B., Zhang, Y., Yu, D., Zweig, G., & Shi, Y. (2014). Spoken language understanding using long short-term memory neural networks. In Proceedings of the IEEE SLT Workshop, South Lake Tahoe, CA. IEEE.
Yao, K., Zweig, G., Hwang, M.-Y., Shi, Y., & Yu, D. (2013). Recurrent neural networks for language understanding. In Proceedings of the Interspeech, Lyon, France.
Zhai, F., Potdar, S., Xiang, B., & Zhou, B. (2017). Neural models for sequence chunking. In Proceedings of the AAAI.
Zhang, X., & Wang, H. (2016). A joint model of intent determination and slot filling for spoken language understanding. In Proceedings of the IJCAI.
Zhu, S., & Yu, K. (2016a). Encoder-decoder with focus-mechanism for sequence labelling based spoken language understanding. In submission.
Zhu, S., & Yu, K. (2016b). Encoder-decoder with focus-mechanism for sequence labelling based spoken language understanding. arXiv preprint arXiv:1608.02097.
译者注:
⑴ 在深度网络中,我们通常将靠近输入端的层称为靠“前”或者靠“下”的层,远离输入端靠近输出端的层称为靠“后”或者靠“上”的层。
(2) 样本分类和序列分类是完全不一样的两类任务。文本分类、情感识别等任务都属于样本分类,比如我要将一篇微博进行分类,以确定这篇微博应该属于哪个频道——情感、校园、体育、军事等,通常类别是有限且较少的。而命名实体识别、槽位识别等任务则属于序列分类,其目标是确定一个序列(比如一句话)中的某个词到底应该是什么,那么其可能类别就是词库中的所有词,那么类别通常就会很庞大。
(3) token,在NLP中通常被翻译成“标记”,但与标签标记概念不同,token表示的是被分割的最基本单位。如我们会根据实际需求,将语料做字/词/句/语篇级别的分割并向量化,作为字向量/词向量/句向量/语篇向量等传入后续的神经网络或其他模型中,那么一个字/词/句/语篇就是一个token。