pandas
第06章:数据加载、存储与文件格式
6.1 读写文本格式的数据
函数:

参数:


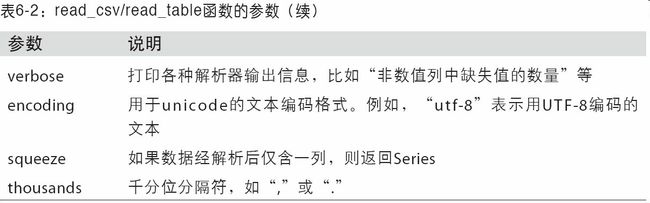
6.1.1 处理分隔符格式
CSV文件的形式有很多。只需定义csv.Dialect的一个子类即可定义出新格式(如专门的分隔符、字符串引用约定、行结束符等):
class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ';'
quotechar = '"'
quoting = csv.QUOTE_MINIMAL
reader = csv.reader(f, dialect=my_dialect)
# 各个CSV语支的参数也可以用关键字的形式提供给csv.reader,而无需定义子类:
reader = csv.reader(f, delimiter='|')

6.1.2. JSON数据:loads,dumps,
换成Python形式,转换成JSON格式,转换为表格,将特别格式的JSON数据集转换为Series或DataFrame,从pandas输出到JSON
6.1.3. 利用lxml.objectify解析XML:
from io import StringIO
书中感觉没有达到自己想到的结果,具体实现请参考文章:解析XML
6.2 二进制数据格式
-
pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法,pickle仅建议用于短期存储格式。
frame.to_pickle('examples/frame_pickle') -
读取Microsoft Excel文件。
frame = pd.read_excel('ex1.xlsx', 'Sheet1')。另外还有Excel实例对象 -
将pandas数据写入为Excel格式
# 首先需要创建Excel实例对象,然后写入表格,再保存 writer = pd.ExcelWriter('examples/ex2.xlsx') frame.to_excel(writer, 'Sheet1') writer.save()
6.3 Web APIs交互:import requests
6.4 数据库交互:connect,execute,commit,fetchall
sqlite3文档
第07章:数据清洗和准备
7.1 处理缺失数据

滤除缺失数据:dropna
填充缺失数据:fillna


7.2 数据转换
1. 移除重复数据:duplicated
2. 利用函数或映射进行数据转换:map
3. 替换值:replace
4. 重命名轴索引:rename
5. 离散化和面元划分:cut,qcut
6. 检测和过滤异常值:numpy.sign()
7. 排列和随机采样:np.random.permutation(),df.take(),df.sample(),
8. 计算指标/哑变量:pd.get_dummies()
7.3 字符串操作
1. 字符串对象方法:split(),split()等;


2. 正则表达式(regex):import re

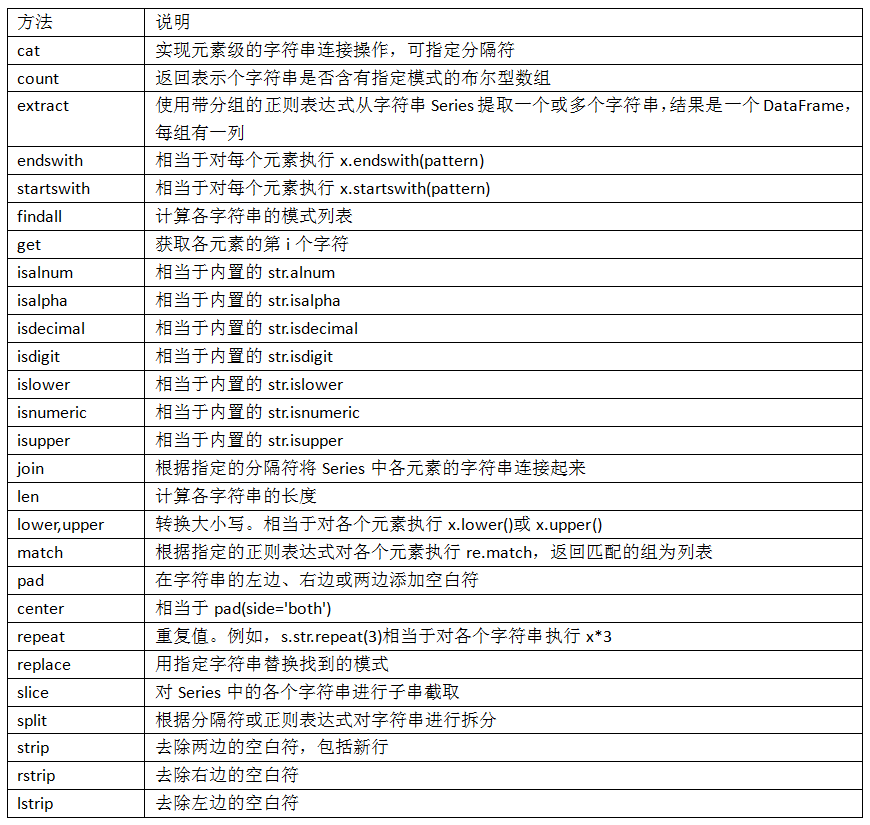
4. pandas的矢量化字符串函数:
部分矢量化字符串方法:
第08章 数据规整:聚合、合并和重塑
8.1 层次化索引
重排与分级排序:swaplevel
根据级别汇总统计:sum
使用DataFrame的列进行索引:set_index
8.2 合并数据集
数据库风格的DataFrame合并:merge
pd.merge(df1, df2, how=‘outer’),how的其他参数

merge函数的参数


索引上的合并:join
轴向连接:concatenate,concat
concat参数:

合并重叠数据:np.where,pd.combine_first
8.3 重塑和轴向旋转
重塑层次化索引:stack,unstack
- stack:将数据的列“旋转”为行。
- unstack:将数据的行“旋转”为列。
将“长格式”旋转为“宽格式”:pivot
将“宽格式”旋转为“长格式”:melt
第09章 绘图和可视化
在Jupyter notebook中执行下面的语句:%matplotlib notebook
引入:import matplotlib.pyplot as plt
9.1 matplotlib API入门
Figure和Subplot:
matplotlib的图像都位于Figure对象中。你可以用plt.figure创建一个新的Figure:fig = plt.figure(),
图形必须用add_subplot创建一个或多个subplot:ax1 = fig.add_subplot(2, 2, 1)
线型图:plt.plot(np.random.randn(50).cumsum(), 'k--')
直方图:ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3)
点图:ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
返回一个含有已创建的subplot对象的NumPy数组:fig, axes = plt.subplots(2, 3)
调整subplot周围的间距:
wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距。hist()函数参数:
| x | 作直方图所要用的数据,必须是一维数组。多维数组可以先进行扁平化再作图 |
|---|---|
| bins | 直方图的柱数,可选项,默认为10 |
| normed | 是否将得到的直方图向量归一化。默认为0 |
| facecolor | 直方图颜色 |
| edgecolor | 直方图边框颜色 |
| alpha | 透明度 |
| histtype | 直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’ |
颜色、标记和线型:
需要配合plt.legend(loc='best')才能显示。
| x | 线图x轴数据 |
|---|---|
| y | 线图y轴数据 |
| linestype | 线条类型 |
| linewidth | 线条宽度 |
| color | 颜色 |
| marker | 可以为线图添加散点,该参数指定点的形状 |
| markersize | 指定点的大小 |
| markeredgecolor0 | 指定点的边框色 |
| label | 图例标签 |
| alpha | 不透明度(值为“0”时为透明状态,默认为“1”) |
设置标题、轴标签、刻度以及刻度标签:
set_xticks:ticks = ax.set_xticks([0, 250, 500, 750, 1000])
set_xticklabels:labels = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five'], rotation=30, fontsize='small')
set_title(string),set_xlabel(string)
添加图例:legend
注解以及在Subplot上绘图:annotate,patch
- ax.annotate方法可以在指定的x和y坐标轴绘制标签。
- plt.Rectangle(),plt.Circle(),plt.Polygon()
将图表保存到文件:plt.savefig

matplotlib配置:plt.rc()
通过一个实现所有配置:
font_options = {'family' : 'monospace',
'weight' : 'bold',
'size' : 'small'}
plt.rc('font', **font_options)
9.2 使用pandas和seaborn绘图
线型图:plot
# Series和DataFrame都能用plot画图
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10))
s.plot()
专用于Series的plot完整列表请参见表:


专用于DataFrame的plot参数:

柱状图:plot.bar(),plot.barh()
seaborn绘图:import seaborn as sns
直方图和密度图:tips[‘tip_pct’].plot.density(),sns.distplot()
散布图或点图:sns.regplot(),sns.pairplot()
第10章数据聚合与分组运算
10.1 GroupBy机制:groupby()
groupby()详解
# 分组计算平均值
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
grouped = df['data1'].groupby(df['key1'])
grouped.mean()
# 二次分组,means得出的是一个分组后的数据表格
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means
对分组进行迭代:for … group …
选取一列或列的子集:
df.groupby(['key1', 'key2'])[['data2']].mean()
通过字典或Series进行分组:
函数参数mapping是一个dict:by_column = people.groupby(mapping, axis=1)
通过函数进行分组:
people.groupby(len).sum()
根据索引级别分组:参数 level
参数详解:
groupby函数参数:垃圾博客都是些什么J8呀,还得是官网啊~~~
10.2 数据聚合

使用自己的聚合函数,需将其传入aggregate或agg方法:
def peak_to_peak(arr):
return arr.max() - arr.min()
grouped.agg(peak_to_peak)
10.3 apply:一般性的“拆分-应用-合并”
说过了,还得是官网
最近在看《利用pandas进行数据分析》,将其中一些函数极其参数摘抄下来便于查阅,图片代码基本都是书中含有的。
另外,本文仅供学习参考!!!