AlexNet训练分类猫狗数据集
AlexNet训练分类猫狗数据集
视频教程来源
视频程序以及猫狗数据集:
链接:https://pan.baidu.com/s/1Tqs5bFY2wVvtGeuFBWV1Yg
提取码:3zrd
一、数据集与训练集的划分
可以通过该段程序将数据集进行训练集以及测试集按照一定比例的划分
未划分前的数据集目录结构:
--data_name
-Cat
1.png
2.png
3.png
4.png
5.png
-Dog
6.png
7.png
8.png
9.png
10.png
按照split_rate = 0.2,训练集:测试集 = 8:2,划分后的数据目录结构:
--data
-train
-Cat
1.png
2.png
3.png
4.png
-Dog
6.png
7.png
8.png
9.png
-val
-Cat
5.png
-Dog
10.png
split_data.py:
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
# 获取data文件夹下所有文件夹名(即需要分类的类名)
file_path = 'C:/Users/86159/Desktop/AlexNet/data_name'
flower_class = [cla for cla in os.listdir(file_path)]
# 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录
mkfile('data/train')
for cla in flower_class:
mkfile('data/train/' + cla)
# 创建 验证集val 文件夹,并由类名在其目录下创建子目录
mkfile('data/val')
for cla in flower_class:
mkfile('data/val/' + cla)
# 划分比例,训练集 : 验证集 = 8 : 2
split_rate = 0.2
# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
num = len(images)
eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称
for index, image in enumerate(images):
# eval_index 中保存验证集val的图像名称
if image in eval_index:
image_path = cla_path + image
new_path = 'data/val/' + cla
copy(image_path, new_path) # 将选中的图像复制到新路径
# 其余的图像保存在训练集train中
else:
image_path = cla_path + image
new_path = 'data/train/' + cla
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print()
print("processing done!")
二、数据增强:
1.归一化处理
可参考文章
data_normalize.py
"""
修改ROOT为数据集的标签的上层目录则可以得到,数据集的均值以及标准差
其中 dog 与 cat 为数据集的标签
目录结构:
-data
-train
-cat
1.jpg
2.jpg
-dog
3.jpg
4.jpg
"""
from torchvision.transforms import ToTensor#用于把图片转化为张量
import numpy as np#用于将张量转化为数组,进行除法
from torchvision.datasets import ImageFolder#用于导入图片数据集
import tqdm
ROOT = r"/home/zxz/Proj/DP/Do/demo_01/data/person_car_dataset/val"
means = [0,0,0]
std = [0,0,0]#初始化均值和方差
transform=ToTensor()#可将图片类型转化为张量,并把0~255的像素值缩小到0~1之间
dataset=ImageFolder(ROOT,transform=transform)#导入数据集的图片,并且转化为张量
num_imgs=len(dataset)#获取数据集的图片数量
# 对图像进行Totensor的变换后,图片为 CHW 格式
for img,a in tqdm.tqdm(dataset,total=num_imgs,ncols = 100):#遍历数据集的张量和标签
for i in range(3):#遍历图片的RGB三通道
# 计算每一个通道的均值和标准差
means[i] += img[i, :, :].mean()
std[i] += img[i, :, :].std()
mean=np.array(means)/num_imgs
std=np.array(std)/num_imgs#要使数据集归一化,均值和方差需除以总图片数量
print(f"mean: {mean}")#打印出结果
print(f"std: {std}")
三、AlexNet网络搭建
网络图片
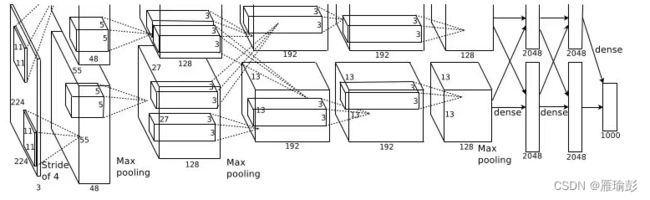
Alexnet.py
from torch import nn
import torch
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)
self.ReLU = nn.ReLU()
self.c2 = nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(2)
self.c3 = nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=1, padding=1)
self.s3 = nn.MaxPool2d(2)
self.c4 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(4608, 2048)
self.f7 = nn.Linear(2048, 2048)
self.f8 = nn.Linear(2048, 1000)
self.f9 = nn.Linear(1000, 2)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s3(x)
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
return x
四、训练步骤
train.py
import torch
from torch import nn
from Alexnet import MyAlexNet
import numpy as np
from torch.optim import lr_scheduler
import os
# 处理数据集的库
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
# web 端显示数据的图像
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
ROOT_TRAIN = r'./data/train'
ROOT_TEST = r'./data/val'
# r'/home/zxz/Proj/DP/Do/demo_01/data/person_car_dataset/train'
# mean: [0.43621388 , 0.41632837 , 0.41138613]
# std: [0.22400378 , 0.21971206 , 0.22065641]
# r'/home/zxz/Proj/DP/Do/demo_01/data/person_car_dataset/val'
# mean: [0.4323618 , 0.41156688 , 0.40333933]
# std: [0.21254596 , 0.20793656 , 0.20750998]
# r'./data/train'
# mean: [0.48817256 , 0.4548179 , 0.41662994]
# std: [0.48817256 , 0.4548179 , 0.41662994]
# r'./data/val'
# mean: [0.488723 , 0.45623815 , 0.4185311]
# std: [0.22901899 , 0.22539699 , 0.22587197]
# 添加 tensorboard
writer = SummaryWriter("web_display")
# 将训练集的图像的像素值归一化至 [-1,1] 之间
train_mean_lsit = [0.43621388 , 0.41632837 , 0.41138613]
train_std_list = [0.22400378 , 0.21971206 , 0.22065641]
# train_mean_lsit = [0.48817256 , 0.4548179 , 0.41662994]
# train_std_list = [0.48817256 , 0.4548179 , 0.41662994]
# train_mean_lsit = [0.5, 0.5, 0.5]
# train_std_list = [0.5, 0.5, 0.5]
train_normalize = transforms.Normalize(train_mean_lsit,train_std_list)
# 将测试集的图像的像素值归一化至 [-1,1] 之间
val_mean_lsit = [0.4323618 , 0.41156688 , 0.40333933]
val_std_list = [0.21254596 , 0.20793656 , 0.20750998]
# val_mean_lsit = [0.488723 , 0.45623815 , 0.4185311]
# val_std_list = [0.22901899 , 0.22539699 , 0.22587197]
# val_mean_lsit = [0.5, 0.5, 0.5]
# val_std_list = [0.5, 0.5, 0.5]
val_normalize = transforms.Normalize(val_mean_lsit,val_std_list)
# AlexNet图像输入的尺寸为 3*224*224
train_transform = transforms.Compose([
transforms.Resize((224,224)),
# 数据增强
transforms.RandomVerticalFlip(), # 默认以50%的概率将图片随机翻转
transforms.ToTensor(),
train_normalize
])
val_transform = transforms.Compose([
transforms.Resize((224,224)),
# transforms.RandomVerticalFlip(),
transforms.ToTensor(),
val_normalize
])
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
# shuffle 为是否将图片顺序进行打乱 训练集无需打乱,测试集可以打乱
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
# 定义程序运行设备,若无法使用GPU则在CPU上进行运算
device_1 = 'cuda:0' if torch.cuda.is_available() else 'cpu'
device = torch.device(device_1)
# 创建网络模型
model = MyAlexNet()
model = model.to(device=device)
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device=device)
# 定义优化器
learn_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),lr=learn_rate,momentum=0.9)
# 学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 定义训练函数 lun 表示目前在第几轮训练
def train(lun,dataloader,model,loss_fn,optimizer):
# 将模型转化为训练模式
model.train()
loss,acc,step = 0.0,0.0,0
for data in dataloader:
imgs,targets = data
# 对数据进行GPU加速
imgs = imgs.to(device)
targets = targets.to(device)
# 将数据传入网路模型
output = model(imgs) # 分别得到每一张图片为那一个target的概率值
# 求解当前损失值(当前批次的损失)
cur_loss = loss_fn(output,targets)
# 求解当前训练批次的正确率
# torch.sum(y==pred) 得到训练预测正确的样本数
# output.shape[0] 得到当前批次的样本数--一个data中的样本数
_, pred = torch.max(output,axis=1)
cur_acc = torch.sum(targets==pred) / output.shape[0]
# 上述代码等价于 accuracy = (outputs.argmax(1) == targets).sum() / output.shape[0]
# 反向传播
optimizer.zero_grad() # 优化前将梯度清0
cur_loss.backward() # 反向传播,求得每一个节点的梯度
optimizer.step() # 对模型的每一个参数进行优化
# 将训练集中的每一个批次上的损失与正确率进行求和累加
loss += cur_loss.item()
acc += cur_acc.item()
# step 该训练集目前训练到多少批次
step = step +1 # 本轮样本的训练次数
if step % 100 == 0:
print("step: {}, cur_loss: {}".format(step,cur_loss))
writer.add_scalar("train_cur_loss",cur_loss.item(),step)
# 本轮训练的每一批次的平均损失、每一个批次的平均正确率
train_loss = loss / step # 本轮训练的平均损失
train_acc = acc / step # 本轮训练的平均正确率
print("train_loss: {}".format(train_loss))
print("train_acc : {}".format(train_acc))
# 在web端显示训练每一轮的平均损失\平均正确率
writer.add_scalar("train_loss",train_loss,lun)
writer.add_scalar("train_acc",train_acc,lun)
# print("本轮训练的总损失为loss为 : {}".format(loss))
# print("本轮训练的总正确率为acc为 : {}".format(acc))
return train_loss,train_acc
# 定义验证(测试)函数
def val(lun,dataloader, model, loss_fn):
# 将模型转化为验证模式
model.eval()
loss,acc,step = 0.0,0.0,0
with torch.no_grad(): # 该部分代码,无梯度,就不会对其进行调优
for data in dataloader:
imgs,targets = data
# 对数据进行GPU加速
imgs = imgs.to(device)
targets = targets.to(device)
# 将图像数据传入模型
output = model(imgs)
cur_loss = loss_fn(output,targets)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(targets==pred) / output.shape[0]
loss += cur_loss.item()
acc += cur_acc.item()
step = step + 1
val_loss = loss / step # 整体数据集上测试的平均损失
val_acc = acc / step # 整体数据集上测试的平均正确率
print("val_loss: {}".format(val_loss))
print("val_acc : {}".format(val_acc))
# 在web端显示测试每一轮的平均损失\平均正确率
writer.add_scalar("val_loss",val_loss,lun)
writer.add_scalar("val_acc",val_acc,lun)
# print("整体数据集上测试的总损失为 loss : {}".format(loss))
# print("整体数据集上测试的总正确率为 acc : {}".format(acc))
return val_loss,val_acc
# 定义画图函数
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, label='train_loss') # 画一个折线名字named = train_loss
plt.plot(val_loss, label='val_loss') # 画一个折线名字named = val_loss
plt.legend(loc='best') # (说明那条曲线是什么的标签)指定图例的位置。默认为loc=best 左上方
plt.ylabel('loss') # 二维图形的y轴名称
plt.xlabel('epoch') # 二维图形的X轴名称
plt.title("train_loss vs val_loss") # 图的标题
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label='train_acc')
plt.plot(val_acc, label='val_acc')
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.title("train_acc vs val_acc")
plt.show()
# 创建列表用于存储数据画图
loss_train = []
acc_train = []
loss_val = []
acc_val = []
# 训练轮数
epoch = 40
min_acc = 0
for i in range(epoch):
print("\n")
print("-------第 {} 轮训练开始------".format(i+1))
# 训练步骤开始
train_loss,train_acc = train(i+1,train_dataloader,model,loss_fn,optimizer)
lr_scheduler.step()
# 验证步骤开始
val_loss,val_acc = val(i+1,val_dataloader,model,loss_fn)
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)
# 保存最好的模型
if val_acc > min_acc:
folder = 'save_model'
if not os.path.exists(folder): # 当前目录不存在则进行创建
os.mkdir(folder)
min_acc = val_acc
print("save best model : 第{}轮".format(i+1))
# 保存权重文件
torch.save(model.state_dict(),'./save_model/best_model.pth')
# 保存最后一轮的权重文件
if i == epoch-1:
torch.save(model.state_dict(),'./save_model/last_model.pth')
matplot_loss(loss_train, loss_val)
matplot_acc(acc_train, acc_val)
print('模型已保存!')
运行结果:
-------第 1 轮训练开始------
step: 100, cur_loss: 0.5969491004943848
step: 200, cur_loss: 0.3097004294395447
step: 300, cur_loss: 0.5576096773147583
step: 400, cur_loss: 0.18371078372001648
step: 500, cur_loss: 0.1883893758058548
step: 600, cur_loss: 0.3744060695171356
train_loss: 0.3623135683263832
train_acc : 0.8414580172580725
val_loss: 0.22669972972901462
val_acc : 0.9112356983571558
save best model : 第1轮
-------第 2 轮训练开始------
step: 100, cur_loss: 0.22954432666301727
step: 200, cur_loss: 0.0689043253660202
step: 300, cur_loss: 0.02064901776611805
step: 400, cur_loss: 0.0788905993103981
step: 500, cur_loss: 0.017716335132718086
step: 600, cur_loss: 0.11165080964565277
train_loss: 0.1265862479151265
train_acc : 0.9532277441169495
val_loss: 0.10920033956586045
val_acc : 0.9619778424226744
save best model : 第2轮
-------第 3 轮训练开始------
step: 100, cur_loss: 0.06773112714290619
step: 200, cur_loss: 0.06686131656169891
step: 300, cur_loss: 0.11350109428167343
step: 400, cur_loss: 0.03183133155107498
step: 500, cur_loss: 0.009865822270512581
step: 600, cur_loss: 0.001601432915776968
train_loss: 0.05197624358038652
train_acc : 0.9814428427512439
val_loss: 0.06913670020673933
val_acc : 0.9774265552995391
save best model : 第3轮
-------第 4 轮训练开始------
step: 100, cur_loss: 0.0025062565691769123
step: 200, cur_loss: 0.042538996785879135
step: 300, cur_loss: 0.0003716982901096344
step: 400, cur_loss: 0.03155139088630676
step: 500, cur_loss: 0.001737942104227841
step: 600, cur_loss: 0.0010269207414239645
train_loss: 0.012883775226271413
train_acc : 0.9956373292867982
val_loss: 0.009434975245828191
val_acc : 0.9967200659249785
save best model : 第4轮
模型已保存!
训练结束之后,会出现两副图片,分别表示 训练损失与测试损失对比 以及 训练正确率与测试正确率对比
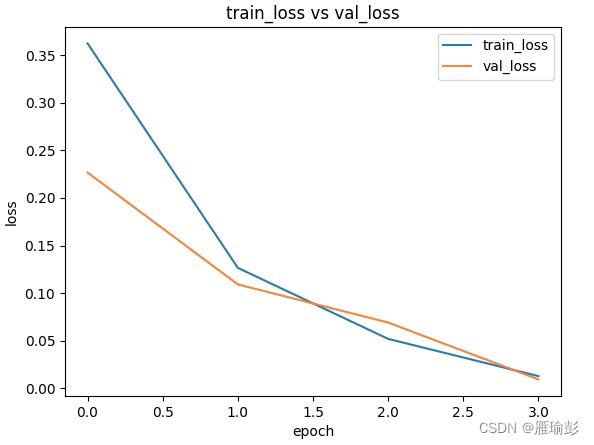
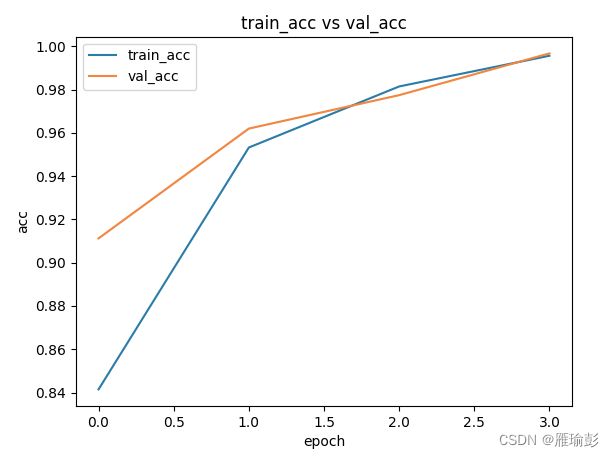
终端输入 : tensorboard --logdir=web_display 得到训练每一轮的平均损失\平均正确率 以及 测试每一轮的平均损失\平均正确率
最好的模型会被保存在 save_model/best_model.pth
五、测试步骤:
test.py: