python特征递归消除

一、基础知识了解
特征递归消除官方给了两者方法
1.RFE
2.RFECV
一.RFE
官方解释
链接:sklearn.feature_selection.RFE — scikit-learn 1.0.2 documentation https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html?highlight=rfe#sklearn.feature_selection.RFE 给定一个为特征分配权重的外部估计器(例如,线性模型的系数),递归特征消除(RFE)的目标是通过递归地考虑越来越小的特征集来选择特征。首先,估计器在初始特征集上进行训练,每个特征的重要性通过任何特定属性或可调用获得。然后,从当前的特征集中剪除最不重要的特征。该过程在修剪后的集合上递归重复,直到最终达到要选择的所需特征数量。
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFE.html?highlight=rfe#sklearn.feature_selection.RFE 给定一个为特征分配权重的外部估计器(例如,线性模型的系数),递归特征消除(RFE)的目标是通过递归地考虑越来越小的特征集来选择特征。首先,估计器在初始特征集上进行训练,每个特征的重要性通过任何特定属性或可调用获得。然后,从当前的特征集中剪除最不重要的特征。该过程在修剪后的集合上递归重复,直到最终达到要选择的所需特征数量。
库
sklearn.feature_selection.RFE
重要参数
| 参数 | 参数说明 |
|---|---|
| estimator | 监督学习估计有 只估计器有具备这两个的其中一个才能进行特征递归消除 例如:随机森林
|
| n_features_to_select | 要选择的特征数。如果None,则选择一半的特征。如果是整数,则参数是要选择的特征的绝对数量。如果在 0 和 1 之间浮动,则它是要选择的特征的一部分。 |
| step | 如果大于或等于 1,则step对应于每次迭代要删除的(整数)个特征。如果在 (0.0, 1.0) 范围内,则step对应于每次迭代中要删除的特征的百分比(向下舍入) |

重要属性
| 属性 | 属性说明 |
|---|---|
| ranking_ | 特征排名,ranking_[i] 对应于第 i 个特征的排名位置。选定(即估计的最佳)特征被分配等级 1。 |
| support_ | 所选特征的掩码。 |
二.RFECV
使用交叉验证进行递归特征消除以选择特征数量
链接
sklearn.feature_selection.RFECV — scikit-learn 1.0.2 documentationhttps://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.RFECV.html?highlight=rfe#sklearn.feature_selection.RFECV库
sklearn.feature_selection.RFECV
重要参数
| 参数 | 参数说明 |
|---|---|
| estimator | 和RFE一样 一种监督学习估计器,其 |
| step | 和RFE一样 如果大于或等于 1,则 |
| cv | 确定交叉验证拆分策略。cv 的可能输入是:
|
重要属性
| 属性 | 属性说明 |
|---|---|
| ranking_ | 特征排名,ranking_[i] 对应于第 i 个特征的排名位置。选定(即估计的最佳)特征被分配等级 1。 |
| support_ | 所选特征的掩码。 |
利用RFE进行
1.利用现有数据,对所选估计器进行参数优化
2.查看估计器的特征重要性
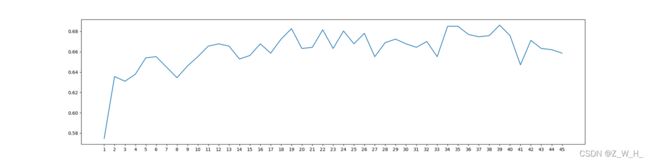
3.根据重要性,自行确定要选择的特征数 或者 利用曲线图选取最优特征数量(以折线图为主重要性为辅助参考)
重要性
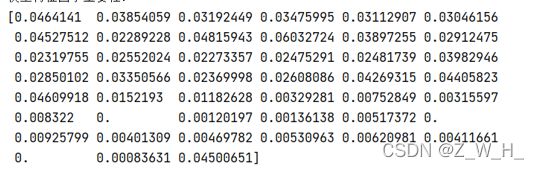
从下面曲线图可以看出39因子的时候分数最高
4.开始进行特征消除
代码如下
import pandas as pd
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import RFECV
from sklearn.feature_selection import RFE
import numpy as np
# 1.读取训练数据集
filepath = r"G:\zwh\付老师\河南\1221\2010和2020建模数据\4.高砷点与筛选后的低砷点合并2010.xls"
#特征因子个数
feature_number = 45
data = pd.read_excel(filepath) # reading file
data = np.array(data)
X=data[:,0:feature_number]
Y=data[:,-1]
# 1.标准化处理
#标准差标准化(standardScale)使得经过处理的数据符合标准正态分布,即均值为0,标准差为1
#概念
#标准化:缩放和每个点都有关系,通过均值μ和标准差σ体现出来;输出范围是负无穷到正无穷
#优点
#提升模型的收敛速度
#提升模型的精度
#使用场景
#如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
scaler = StandardScaler()
X_train = scaler.fit_transform(X)
# 2.构建RF模型
#参数是基于个人数据优化的结果
RFC_model = RFC(n_estimators=41,max_depth=12,max_features=1,min_samples_leaf=1,min_samples_split=14,criterion='gini') # 随机森林
#feature_importances_基于杂质的特征重要性
RFC_feature_importances = RFC_model.fit(X, Y).feature_importances_ # 特征重要性
print("模型特征因子重要性:")
print(RFC_feature_importances)
# 3.递归特征消除法和曲线图选取最优特征数量
# 建立得分列表
score = []
#range创建的结果不包括feature_number+1
for i in range(1, feature_number+1, 1):
#fit_transform适合数据,然后转换它
#为什么y不进行分类,因为数据的类别是事前确定的,如果更改y,那么数据就与现实情况不符
X_transform = RFE(RFC_model, n_features_to_select=i, step=1).fit_transform(X, Y)
# 交叉验证
RFE_score = cross_val_score(RFC_model, X_transform, Y, cv=10).mean()
# 交叉验证结果保存到列表
score.append(RFE_score)
print('输出所有分类结果',score)
print('输出最优分类结果',max(score),'对应的特征数量', (score.index(max(score))*1)+1)# 输出最优分类结果和对应的特征数量
plt.figure(figsize=[20, 5])
plt.plot(range(1, 46, 1), score)
plt.xticks(range(1, 46, 1))
plt.show()
# 4.递归特征消除法
# n_features_to_select表示筛选最终特征数量,step表示每次排除一个特征
selector1 = RFE(RFC_model, n_features_to_select=(score.index(max(score))*1)+1, step=1).fit(X, Y)
#所选特征的掩码和
print('RFE所选特征的掩码',selector1.support_)
print('RFE特征排除排序',selector1.ranking_)
print('RFE选择特征数量',selector1.n_features_)
X_transform1 = selector1.transform(X)
RFE_optimal_score =cross_val_score(RFC_model, X_transform1, Y, cv=10).mean()
print('RFE最优特征交叉验证分数',RFE_optimal_score)
# 5. 交叉验证递归特征消除法
#使用交叉验证进行递归特征消除以选择特征数量。
# 采用交叉验证,每次排除一个特征,筛选出最优特征
selector = RFECV(RFC_model, step=1, cv=10)
selector = selector.fit(X, Y)
RFECV_X_transform = selector.transform(X)
# 最优特征分类结果
RFECV_optimal_score =cross_val_score(RFC_model , RFECV_X_transform, Y, cv=10).mean()
print('RFECV最优特征交叉验证分数',RFECV_optimal_score)
print("最佳数量和排序")
print('RFECV选取结果',selector.support_)
print('RFECV选取特征数量',selector.n_features_)
print('RFECV依次排数特征排序',selector.ranking_)