Tesseract Ocr文字识别实战(新版本,扩展手写文字识别)
目录
1.Tesseract Ocr文字识别
1.1 运行环境
1.2 python模块
1.3 配置tesseract运行文件
1.4 代码识别
2. 手写汉字识别
2.1 下载库
2.2 代码
1.Tesseract Ocr文字识别
前半部分原github地址:faceai/tesseractOCR.md at master · vipstone/faceai · GitHub
1.1 运行环境
windows10 + python 3.9 + tesseract 5.2.0
https://github.com/UB-Mannheim/tesseract/wiki一、安装tesseract orc
下载地址:https://github.com/UB-Mannheim/tesseract/wiki
点击“tesseract-ocr-w64-setup-v5.2.0.20220712.exe”下载安装。
安装的时候注意选择中文包
本人安装目录:"D:\APP\OCR"
1.2 python模块
matplotlib==3.6.0
numpy==1.23.3
scipy==1.9.1
pywavelets==1.4.1
1.3 配置tesseract运行文件
D:\anaconda\envs\ocr_lhy\Lib\site-packages\pytesseract\pytesseract.py 找到文件:
tesseract_cmd = 'tesseract'
修改为(注意'\\'):
tesseract_cmd = "D:\APP\OCR\\tesseract.exe"
1.4 代码识别
from PIL import Image
import pytesseract
path = "image\\img.png"
text = pytesseract.image_to_string(Image.open(path), lang='eng')
print(text)
lang='eng'表示英文识别,效果如下:
(被识别图源于网络)

中文用 lang= ‘chi_sim’,识别效果如下:


“聒” 识别成了 “联”,识别效果还可以
2. 手写汉字识别
OCR还可以通过MINIST数据库,做手写文字识别
以下部分参考,代码有更改https://blog.csdn.net/qq_43006184/article/details/121604452?spm=1001.2101.3001.6650.6&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-6-121604452-blog-90744871.topnsimilarv1&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-6-121604452-blog-90744871.topnsimilarv1&utm_relevant_index=13
2.1 下载库
(opencv要注意对应numpy的版本,我用的是1.23.3)
tensorflow==2.10.0
第二个代码要用:
opencv==4.5.5.64
opencv-python==4.5.5.64
下载opencv参考https://blog.csdn.net/qq_43605229/article/details/114572661
2.2 代码
代码如下:
import os
import cv2
import numpy as np
import tensorflow as tf2
import matplotlib.pyplot as plt
import tensorflow.compat.v1 as tf
def nextBatch(data,batch_size,n):#小批量梯度下降法获取当前数据集函数
#data为全部数据[X,Y],batch_size为当前子数据集大小,n为第n个子数据集
a=n*batch_size
b=(n+1)*batch_size
limdata=len(data[0])
if b>limdata:
b=limdata
a=b-batch_size
data_x=data[0][a:b]
data_y=data[1][a:b]
return data_x,data_y
def main_train():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()#手写数据库
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
training_epochs=100#训练步数
batch_count=20#小批量训练子集数量
L=32#卷积层1所提取特征个数
M=64#卷积层2所提取特征个数
N=128#卷积层3所提取特征个数
O=625#全连接就层神经元数
with tf.device('/cpu:0'):
# with tf.device('/gpu:0'):
Xin=tf.placeholder(tf.float32,[None,28,28,1],name='Xin')#28×28维输入特征
Yout=tf.placeholder(tf.float32,[None,10],name="Yout")#10类分类结果标签
W1=tf.Variable(tf.random_normal([3,3,1,L],stddev=0.01))#卷积层1的卷积核权值张量,卷积核大小3×3,输入数据为1通道,输出特征为32通道
W2=tf.Variable(tf.random_normal([3,3,L,M],stddev=0.01))#卷积层2的卷积核权值张量,卷积核大小3×3,输入数据为32通道,输出特征为64通道
W3=tf.Variable(tf.random_normal([3,3,M,N],stddev=0.01))#卷积层3的卷积核权值张量,卷积核大小3×3,输入数据为64通道,输出特征为128通道
W4=tf.Variable(tf.random_normal([N*4*4,O],stddev=0.01))#全连接层权值张量,输入数据为128×4×4个,输出为625个,这里需要把上一层的高维张量扁平化
W5=tf.Variable(tf.random_normal([O,10],stddev=0.01))#输出层权值张量,输入数据为625,输出为10类
b1=tf.Variable(tf.random_normal([L],stddev=0.01))#卷积层1的输出特征阈值,输出特征为32通道,每个通道共享一个阈值
b2=tf.Variable(tf.random_normal([M],stddev=0.01))#卷积层2的输出特征阈值,输出特征为64通道,每个通道共享一个阈值
b3=tf.Variable(tf.random_normal([N],stddev=0.01))#卷积层3的输出特征阈值,输出特征为128通道,每个通道共享一个阈值
b4=tf.Variable(tf.random_normal([O],stddev=0.01))#全连接层阈值
b5=tf.Variable(tf.random_normal([10],stddev=0.01))#输出层阈值
'''卷积层一'''
conv1a=tf.nn.conv2d(Xin,W1,strides=[1,1,1,1],padding='SAME')
conv1b=tf.nn.bias_add(conv1a,b1)
conv1c=tf.nn.relu(conv1b)
'''池化层一'''
conv1=tf.nn.max_pool(conv1c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层二'''
conv2a=tf.nn.conv2d(conv1,W2,strides=[1,1,1,1],padding='SAME')
conv2b=tf.nn.bias_add(conv2a,b2)
conv2c=tf.nn.relu(conv2b)
'''池化层二'''
conv2=tf.nn.max_pool(conv2c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
'''卷积层三'''
conv3a=tf.nn.conv2d(conv2,W3,strides=[1,1,1,1],padding='SAME')
conv3b=tf.nn.bias_add(conv3a,b3)
conv3c=tf.nn.relu(conv3b)
'''池化层三'''
conv3d=tf.nn.max_pool(conv3c,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
conv3=tf.reshape(conv3d,[-1,W4.get_shape().as_list()[0]])#扁平化
'''全连接层'''
FCa=tf.matmul(conv3,W4)+b4
FC=tf.nn.relu(FCa)
'''输出层'''
Y_=tf.matmul(FC,W5)+b5
Y=tf.nn.softmax(Y_,name="output")#经历softmax分类激活函数后的数值
'''损失'''
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=Y_, labels=Yout)
loss=tf.reduce_mean(cross_entropy)*100#交叉损失
correct_prediction=tf.equal(tf.argmax(Y,1),tf.argmax(Yout,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name='accuracy')#正确率
'''优化器'''
trainer=tf.train.RMSPropOptimizer(learning_rate=0.001,momentum=0.9).minimize(loss)
init=tf.global_variables_initializer()#变量初始化赋值器
with tf.Session() as sess:
sess.run(init)#变量初始化
out_init=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})#计算初始误差
print("初始准确率为:{:.4f}%".format(out_init*100))#输出初始误差
for epoch in range(training_epochs):#训练步数
print("当前训练步为第{}步".format(epoch+1))
batch_size=int(len(y_tr)/batch_count)#当前子集大小
for i in range(batch_count):#对每个子集遍历训练
batch_x,batch_y=nextBatch([x_tr[0:20000],y_tr[0:20000]],batch_size,i)#当前子集的训练集特征和标签数据
sess.run(trainer,feed_dict={Xin:batch_x,Yout:batch_y})
out=sess.run(accuracy,feed_dict={Xin:x_tr[0:20000],Yout:y_tr[0:20000]})#计算当前误差
print("当前准确率为:{:.4f}%".format(out*100))#当前初始误差
'''当前会话存储'''
if out>out_init:
out_init=out
saver=tf.train.Saver()
saver.save(sess,r".\savefile\CNN\FigureCNN.ckpt")
return
def main_test():
(x_tr0,y_tr0),(x_te0,y_te0)=tf2.keras.datasets.mnist.load_data()#手写数据库
y_tr=np.zeros((len(y_tr0),10))
y_te=np.zeros((len(y_te0),10))
for i in range(len(y_tr0)):
y_tr[i][y_tr0[i]]=1
for i in range(len(y_te0)):
y_te[i][y_te0[i]]=1
x_tr=x_tr0.reshape(-1,28,28,1)
x_te=x_te0.reshape(-1,28,28,1)
road=[r".\savefile\CNN\FigureCNN.ckpt.meta",r".\savefile\CNN\FigureCNN.ckpt"]
sess=tf.InteractiveSession()
new_saver=tf.train.import_meta_graph(road[0])
new_saver.restore(sess,road[1])
tf.get_default_graph().as_graph_def()
Xin=sess.graph.get_tensor_by_name('Xin:0')
Yout=sess.graph.get_tensor_by_name("Yout:0")
accuracy=sess.graph.get_tensor_by_name('accuracy:0')
Y=sess.graph.get_tensor_by_name('output:0')
roadpic='./image/one.jpeg' # './image/eight.jpeg' # 手写数字文件,大小28x28像素
pic=cv2.imread(roadpic,flags=0)
pic1=255-pic # 因为MINIST数据库是黑底白字,我用的是白底黑字
# pic1 = cv2.resize(pic1,(28,28))
pic=pic1.reshape(-1,28,28,1)
Otem=sess.run(Y,feed_dict={Xin:pic})
print('南笙手写的数字为:{}'.format(Otem.argmax()))
return
if __name__=="__main__":
tf.disable_v2_behavior()
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
# 如果已经生成模型,可以注释掉main_train()函数
main_train()
main_test()
其中,main_train()函数用于训练模型,
截取部分运行结果,最高的成功率大概为99.21%(当然每次运行结果会有不一样):
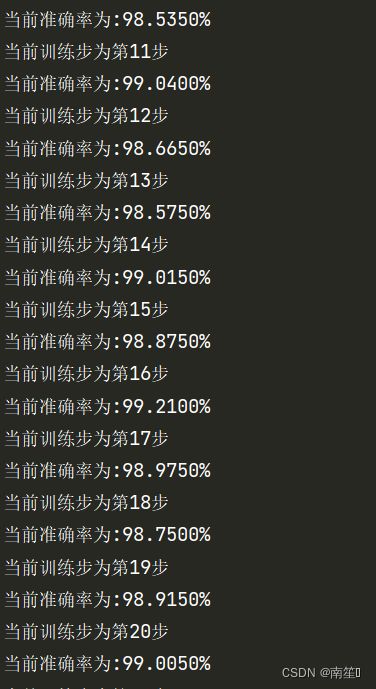
main_test()函数用于识别自己的手写数字,需要注意几点:
① MINIST数据集是黑底白字,我用的是白底黑字,所以要有 pic1=255-pic 的操作。
② 图片是经过我预先处理成28x28像素大小的,不然会报错。(也可以通过代码处理成28x28大小的)
自己的手写字体识别效果(图片预处理成28x28的大小):
![]()
![]()
![]()
![]()