计算机视觉(四)
计算机视觉(四)图像到图像的映射下半部分
- 1.RANSAC
- 2. 图像配准
- 3.图割方法
- 4.图像融合
- 5. APAP算法
- 6.multi-band bleing算法
在这章节的开始,首先我们得知道什么是全景图像,全景图像就是同一位置(即图像的照相机位置相同)拍摄的两幅或者多幅图像是单应性相关的。
我们经常使用该约束将很多图像缝补起来,拼成一个大的图像

1.RANSAC
RANSAC 是“RANdom SAmple Consensus”(随机一致性采样)的缩写。该方法是用来找到正确模型来拟合带有噪声数据的迭代方法。给定一个模型,例如点集之间的单应性矩阵,RANSAC 基本的思想是,数据中包含正确的点和噪声点,合理的模型应该能够在描述正确数据点的同时摒弃噪声点。

2. 图像配准
图像配准是对图像进行变换,使变换后的图像能够在常见的坐标系中对齐。为了能够进行图像对比和更精细的图像分析,图像配准是一步非常重要的操作。图像配准的方法有很多,这里以APAP算法为例:
1.提取两张图片的sift特征点
2.对两张图片的特征点进行匹配
3.匹配后,仍有很多错误点,此时用RANSAC进行特征点对的筛选。筛选后的特征点基本能够一一对应。
4.使用DLT算法,将剩下的特征点对进行透视变换矩阵的估计。
5.因为得到的透视变换矩阵是基于全局特征点对进行的,即一个刚性的单应性矩阵完成配准。为提高配准的精度,Apap将图像切割成无数多个小方块,对每个小方块的变换矩阵逐一估计。
3.图割方法
最大流最小割算法原理,
1.最小割问题
一个有向图,并有一个源顶点(source vertex)和目标顶点(target vertex).边的权值为正,又称之为容量(capacity)。如下图

一个st-cut(简称割cut)会把有向图的顶点分成两个不相交的集合,其中s在一个集合中,t在另外一个集合中。
这个割的容量(capacity of the cut)就是A到B所有边的容量和。注意这里不包含B到A的。最小割问题就是要找到割容量最小的情况。
2.最大流问题
跟mincut问题类似,maxflow要处理的情况也是一个有向图,并有一个原顶点(source vertex)和目标(target vertex),边的权值为正,又称之为容量(capacity)。
(1)初始化,所有边的flow都初始化为0。
(2)沿着增广路径增加flow。增广路径是一条从s到t的无向路径,但也有些条件,可以经过没有满容量的前向路径(s到t)或者是不为空的反向路径(t->s)。
4.图像融合
图像拼接之后可以发现,在拼接的交界处有明显的衔接痕迹,存在边缘效应,因为光照色泽的原因使得图片交界处的过渡很糟糕,所以需要特定的处理解决这种不自然。那么这时候可以采用blending方法。multi-band blending是目前图像融和方面比较好的方法。
原理:
1.建立两幅图像的拉普拉斯金字塔
2.求高斯金字塔(掩模金字塔-为了拼接左右两幅图像)因为其具有尺度不变性
3. 进行拼接blendLapPyrs() ; 在每一层上将左右laplacian图像直接拼起来得结果金字塔resultLapPyr
4.重建图像: 从最高层结果图
将左右laplacian图像拼成的resultLapPyr金字塔中每一层,从上到下插值放大并和下一层相加,即得blend图像结果(reconstructImgFromLapPyramid)
且我们可以将拉普拉斯金字塔理解为高斯金字塔的逆形式。
5. APAP算法
在图像拼接融合的过程中,受客观因素的影响,拼接融合后的图像可能会存在“鬼影现象”以及图像间过度不连续等问题。下图就是图像拼接的一种“鬼影现象”。
解决鬼影现象可以采用APAP算法。

算法流程:
1.SIFT得到两幅图像的匹配点对
2.通过RANSAC剔除外点,得到N对内点
3.利用DLT和SVD计算全局单应性
4.将源图划分网格,取网格中心点,计算每个中心点和源图上内点之间的欧式距离和权重
5.将权重放到DLT算法的A矩阵中,构建成新的W*A矩阵,重新SVD分解,自然就得到了当前网格的局部单应性矩阵
6.遍历每个网格,利用局部单应性矩阵映射到全景画布上,就得到了APAP变换后的源图
7.最后就是进行拼接线的加权融合


6.multi-band bleing算法
在找完拼接缝后,由于图像噪声、光照、曝光度、模型匹配误差等因素,直接进行图像合成会在图像重叠区域的拼接处出现比较明显的边痕迹。

这些边痕迹需要使用图像融合算法来消除。这里介绍一种方法—multi-band bleing
思想:
采用的方法是直接对带拼接的两个图片进行拉普拉斯金字塔分解,后一半对前一半进行融合
步骤:
首先计算当前待拼接图像和已合成图像的重叠部分。并对图像A、B 重叠部分进行高斯金字塔和拉普拉斯金字塔分解

G0为原始图像,G1表示对G0做reduce操作。Reduce操作定义如下:

对G1进行扩展后与G0相减,可以得到拉普拉斯金字塔的第一层L0。同理,拉普拉斯金字塔的L2、L3等层也可以按照这种方法来计算。
两幅图像的融合过程:分别构建图像A、B的高斯金字塔和拉普拉斯金字塔,然后进行加权融合。
对加权后的拉普拉斯金字塔进行重构

代码:
from PIL import Image
from numpy import *
from pylab import *
import os
def process_image(imagename,resultname,params="--edge-thresh 10 --peak-thresh 5"):
""" Process an image and save the results in a file. """
if imagename[-3:] != 'pgm':
# create a pgm file
im = Image.open(imagename).convert('L')
im.save('tmp.pgm')
imagename = 'tmp.pgm'
cmmd = str(r"D:/计算机视觉/sift.exe "+imagename+" --output="+resultname+
" "+params)
os.system(cmmd)
print('processed', imagename, 'to', resultname)
def read_features_from_file(filename):
""" Read feature properties and return in matrix form. """
f = loadtxt(filename)
return f[:,:4],f[:,4:] # feature locations, descriptors
def write_features_to_file(filename,locs,desc):
""" Save feature location and descriptor to file. """
savetxt(filename,hstack((locs,desc)))
def plot_features(im,locs,circle=False):
""" Show image with features. input: im (image as array),
locs (row, col, scale, orientation of each feature). """
def draw_circle(c,r):
t = arange(0,1.01,.01)*2*pi
x = r*cos(t) + c[0]
y = r*sin(t) + c[1]
plot(x,y,'b',linewidth=2)
imshow(im)
if circle:
for p in locs:
draw_circle(p[:2],p[2])
else:
plot(locs[:,0],locs[:,1],'ob')
axis('off')
def match(desc1,desc2):
""" For each descriptor in the first image,
select its match in the second image.
input: desc1 (descriptors for the first image),
desc2 (same for second image). """
desc1 = array([d/linalg.norm(d) for d in desc1])
desc2 = array([d/linalg.norm(d) for d in desc2])
dist_ratio = 0.6
desc1_size = desc1.shape
matchscores = zeros((desc1_size[0]),'int')
desc2t = desc2.T # precompute matrix transpose
for i in range(desc1_size[0]):
dotprods = dot(desc1[i,:],desc2t) # vector of dot products
dotprods = 0.9999*dotprods
# inverse cosine and sort, return index for features in second image
indx = argsort(arccos(dotprods))
# check if nearest neighbor has angle less than dist_ratio times 2nd
if arccos(dotprods)[indx[0]] < dist_ratio * arccos(dotprods)[indx[1]]:
matchscores[i] = int(indx[0])
return matchscores
def appendimages(im1,im2):
""" Return a new image that appends the two images side-by-side. """
# select the image with the fewest rows and fill in enough empty rows
rows1 = im1.shape[0]
rows2 = im2.shape[0]
if rows1 < rows2:
im1 = concatenate((im1,zeros((rows2-rows1,im1.shape[1]))), axis=0)
elif rows1 > rows2:
im2 = concatenate((im2,zeros((rows1-rows2,im2.shape[1]))), axis=0)
# if none of these cases they are equal, no filling needed.
return concatenate((im1,im2), axis=1)
def plot_matches(im1,im2,locs1,locs2,matchscores,show_below=True):
""" Show a figure with lines joining the accepted matches
input: im1,im2 (images as arrays), locs1,locs2 (location of features),
matchscores (as output from 'match'), show_below (if images should be shown below). """
im3 = appendimages(im1,im2)
if show_below:
im3 = vstack((im3,im3))
# show image
imshow(im3)
# draw lines for matches
cols1 = im1.shape[1]
for i,m in enumerate(matchscores):
if m>0:
plot([locs1[i][0],locs2[m][0]+cols1],[locs1[i][1],locs2[m][1]],'c')
axis('off')
def match_twosided(desc1,desc2):
""" Two-sided symmetric version of match(). """
matches_12 = match(desc1,desc2)
matches_21 = match(desc2,desc1)
ndx_12 = matches_12.nonzero()[0]
# remove matches that are not symmetric
for n in ndx_12:
if matches_21[int(matches_12[n])] != n:
matches_12[n] = 0
return matches_12
结果:



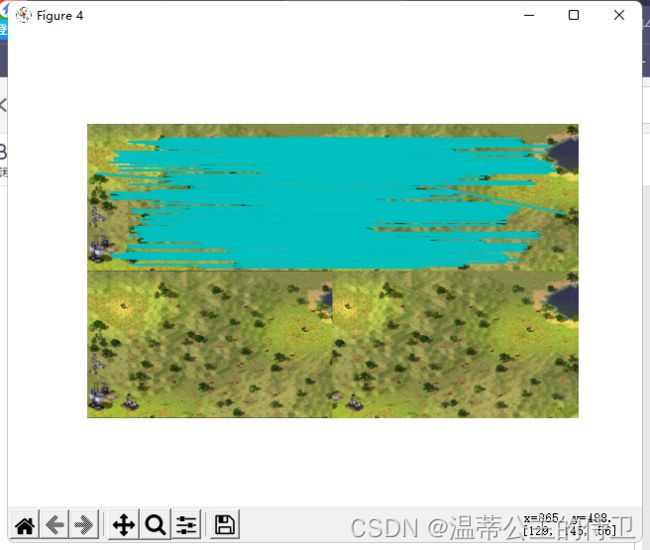

因该是因为图片分辨率的问题,感觉拼接完的图片很小。但是从拼接结果来看算是不错的!