PyTorch深度学习(5)神经网络 nn.Module及Conv2d卷积层
一、神经网络模块
神经网络:Neural Network
1、引入包
import torch.nn
2、继承
需要定义类并继承nn.Module,并重写其中的__init__ 和 forward 方法
3、具体代码
import torch
from torch import nn
# 继承nn.Module后需实现__init__和forward方法
# forward 为前向传播
class NNModule(nn.Module):
def __init__(self):
super(NNModule, self).__init__()
def forward(self, input_data):
output_data = input_data + 1
return output_data
nn_m = NNModule() # 定义
x = torch.tensor(1.0)
result = nn_m(x) # 添加输入
print(result)
二、卷积层
Convolution Layers 卷积层 Conv1d为一维卷积 Conv2d为二维卷积 Conv3d为三维卷积
1、torch.nn.functional.conv2d
(1)引入包 from torch.nn import functional 函数
functional.conv2d 为2维卷积层
(2)参数详情:
- input:输入 (minibatch, in_channels, iH, iW) 输入通道,高,宽
- weight:卷积核(权重)(out_channels, in_channels/group, kH, kW)
- bias:偏置
- stride:filter扫描时需要跳跃的格数,可以是单个数或元组(sH, sW),默认为1
- padding:空白区域填充的大小,可以是单个数元组(dH, dW),默认为0
(3)运算顺序:输入图像(5×5)——> 卷积核(3×3)——> 卷积后的输出
对应位置相乘后相加,求得卷积后输出
(4)torch.nn.functional.conv2d 具体代码
import torch
from torch.nn import functional as F
# 输入图像
inputData = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernelData = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 因为不满足于conv2d的输入格式,故而将输入和卷积核重设尺寸参数
input_data = torch.reshape(inputData, (1, 1, 5, 5)) # batch_size in_channels iH iW
kernel = torch.reshape(kernelData, (1, 1, 3, 3))
print(input_data.shape)
print(kernel.shape)
# stride 内核默认移动1位
# 卷积后输出
output = F.conv2d(input_data, kernel, stride=1)
print(output)
output2 = F.conv2d(input_data, kernel, stride=2)
print(output2)
# padding 周围留有空白大小
output3 = F.conv2d(input_data, kernel, stride=1, padding=1)
print(output3)
2、Conv2d 二维卷积
(1)引入包 from torch.nn import Conv2d
(2)参数详情:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, group=1, bias=True, padding_mode='zeros')
- in_channels(int):输入图片通道数
- out_channels(int):通过卷积后的输出通道数
- kernel_size(int or tuple):卷积核大小,如果定义为3,则为3×3的卷积核大小
optional:可选
- stride(int or tuple, optional):卷积时步进大小,默认为1
- padding(int or tuple, optional):对原图像的空白扩展,默认为0
- padding_mode(string, optional):是按照什么样的模式进行填充,‘zeros’, 'reflect', 'replicate' or 'circular'. 默认:'zeros'
- dilation(string, optional):卷积核对应位的距离,默认为1
- groups(int, optional):输入通道到输出通道的阻塞连接的数量,默认为1
- bias(bool, optional):是否偏置
(3)卷积公式
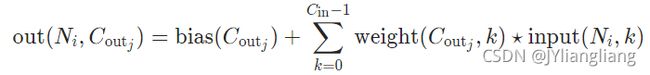
即输入与卷积相同位置相乘后相加

蓝色为输入图像,绿色为输出图像,阴影部分为卷积核
(4)输入图像(5×5) in_channel=1 ——> 卷积核 (3×3)——> 卷积后输出 out_channel=1
输入图像(5×5) in_channel = 1 卷积核1 ——> 卷积后输出 out_channel=2
卷积核2 ——>
输出的通道数 = 卷积核数

N为batch_size 批次数量
C为通道,输入通道和输出通道
H为输入和输出的高
W为输入和输出的宽
(5)具体代码
from torch import nn
from torch.utils.data import DataLoader
import torchvision
from torch.nn import Conv2d
import ssl
from torch.utils.tensorboard import SummaryWriter
import torch
ssl._create_default_https_context = ssl._create_unverified_context
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class TestImage(nn.Module):
def __init__(self):
super(TestImage, self).__init__()
# 定义卷积层 输入通道3,内核数3,输出通道6,步长1
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x) # 将x放入到卷积层conv1中
return x
ti = TestImage()
# 显示图像
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
images, target = data
output = ti(images)
print(images.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32]) 输入大小
writer.add_image("input", images, step, dataformats="NCHW")
# torch.Size([64, 6, 30, 30]) -> [xxx, 3, 30, 30] 输出大小
# 因为输出报错,则将图片更改为指定输出大小
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_image("output", output, step, dataformats="NCHW")
step = step + 1
writer.close()