TD3——DDPG的优化版本
TD3是Twin Delayed Deep Deterministic policy gradient algorithm的简称,双延迟深度确定性策略梯度。从名字看出,TD3算法是DDPG的改进版本。
优化主要体现在三个方面:
1、Clipped Double_Q Learning:使用两个"Twin" 独立的Critic网络来估算Q值,并且在计算目标Q时选取较小的Q值来计算,有效的缓解值过高估计问题,大大提高算法的性能。
2、“Delayed” Policy Updates:Actor网络使用延迟学习。Critic网络更新的频率要比Actor网络更新的频率要大,以便在引入策略前先将误差最小化(让Critic网络再稳定些再来更新Actor网络)。
3、Target Policy Smoothing Regularization:Actor网络的目标网络中引入了噪声,是为了预估更准确,网络鲁棒性更强些。
TD3算法来自论文 Addressing Function Approximation Error in Actor-Critic Methods。
上述的优化主要解决两个问题:一个是过估计,overestimate,另一个是高方差现象,high variance。
1、overestimation in Actor-Critic
1.1 什么是overestimation?
在强化学习中,对于离散化的动作的学习(如DQN),值函数往往会被过高估计。这是因为,在对Q函数估计的处理中,常常选择最大化的Q值代替V(s')进行评估,这样做通常会使估计值高于真实的最大Q值。累积下来的过高估计可能会使得算法陷入次优策略中,导致发散等行为。同样的,这种值的过高估计也存在处理连续的动作控制的 Actor-Critic 框架中。
1.2 Clipped Double_Q Learning
为了解决值过估问题,文章原来想用Double DQN中的技术,使用target Q network和main Q network分别进行状态价值估计和选取动作(动作的选取与动作的评估分开),使用单独的目标值函数估计当前策略的值函数。然而因为 Actor-Critic中策略变化很慢,当前以及目标值函数估计非常接近,从而无法避免最大化误差。
于是采用了Double Q-learning中的方法,使用一对(2个)独立的神经网络估计Critic。但是这种方法虽然能解决bias问题,但是同时也会带来高方差。为了解决这个问题,文章提出了一个clipped Double Q-learning版本(更新时对梯度进行裁剪即取最小的Q值),来降低方差:

DDPG算法涉及了4个网络,所以TD3需要用到6个网络。两种算法的框图如下:
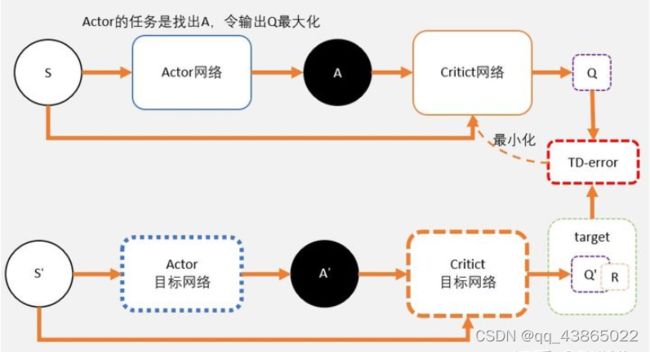
我们通过Critic网络估算动作的A值。一个Critic的评估可能会较高。所以我们再加一个Critic网络

2、 addressing variance
文章还使用三种技能来降低方差:
- 使用target networks,这是从DQN开始就一直使用的技巧,降低critic的更新频率,在学习过程中提供了一个稳定的目标。
- 使用Delaying policy updates来解决值函数和策略耦合问题。论文中推荐更新两次价值网络才更新一次策略网络。这样可以让两者解耦,关联度降低。
- 使用Target policy smoothing regularization正则化方法在更新参数的时候,用于平滑策略期望。
2.1 Delaying policy updates
这里说的Dalayed ,是 Actor 更新的delay。也就是说相对于critic可以更新多次后,actor再进行更新。为什么要这样做呢?
我们在DDPG中说过,DDPG网络图像上就可以想象成一张布,覆盖在Q table上。在网络学习过程中,Q值是在不断变化的,也就是说这块布是不断变形的。所以要寻着最高点的任务有时候就挺难为为的actor了。可以想象,本来是最高点的,当actor好不容易去到最高点,q值更新了,这并不是最高点。这时候actor只能转头再继续寻找新的最高点。更坏的情况可能是actor被困在次高点,没有找到正确的最高点。所以我们可以把Critic的更新频率,调的比Actor要高一点。让critic更加确定,actor再行动。
2.2 Target policy smoothing regularization
确定性策略的一个问题是,它们可能会过度拟合到价值估计中的窄峰值。在更新 Critic 时,使用确定性策略的学习目标很容易受到函数逼近误差引起的误差的影响,从而增加目标的方差(或者不可导)。这种诱导的方差可以通过正则化来减少。
我们引入了一种正则化策略用于深度值学习,target policy smoothing,主要强化这样一个概念:相似的行动应该有相似的价值。虽然函数近似 隐含 地做到了这一点,但可以通过修改训练过程来明确地强制相似动作之间的关系。我们建议拟合目标动作周围的一个小区域的值,可以通过启动类似的状态-动作值估计来平滑值估计。

在实践中,我们可以通过向目标策略中添加少量随机噪声 并在小批量中平均来近似地估计操作的期望。这将使我们修改后的目标更新

即,在TD3中,Actor的目标网络中引入了噪声即每次都在action上加一个小扰动,这个操作就是target policy smoothing regularization。
在DDPG中,计算target的时候,我们输入时s_和a_,获得q,也就是这块布上的一点A(下个状态的Q值)。通过估算target估算另外一点s,a,也就是布上的另外一点B的Q值。在TD3中,计算 target 时候,输入s_到actor输出a后,给a加上噪音,让a在一定范围内随机。这又什么好处呢?
好处就是,当更新多次的时候,就相当于用 A 点附近的一小部分范围(准确来说是在s_这条线上的一定范围)去估算B,(可理解为将A映射到B上,在相邻处使曲线平滑),从而使B点的估计更准确,更健壮。
这注意区分三个地方:
- 在跑游戏的时候,我们在Actor 的当前网络加上了noise。这个时候的noise是为了更充分地开发整个游戏空间(使动作更充分的探索)。
- 计算target的时候,actor加上noise,是为了预估更准确,网络更有健壮性。
- 更新actor的时候,我们不需要加上noise,(直接将状态送进Actor网络中求得动作,并将状态和动作一块送入Critic网络中求得当前状态-动作下的Q值来更新Actor网络) ,这里是希望actor能够寻着最大的Q值。加上noise并没有任何意义。
TD3的伪代码如下所示:

其中在 Actor 网络的更新时,可以看到用的是Q1更新了,为什么呢?
Actor 的任务,就是用梯度上升的方法,寻着这条线的最高点。对于Actor 来说,其实并不在乎Q值是否会被高估,它的任务只是不断做梯度上升,寻找这条最大的Q值。随着更新的进行Q1和Q2两个网络,将会变得越来越像。所以用Q1还是Q2,还是两者都用,对于Actor的问题不大。
等到当前Actor 和 Critic网络参数更新后,目标 Actor 和 Critic网络参数采用软更新的方式进行更新。
这是最近在学习TD3时整理的内容。其中更详细的资料来自于:
1. 什么是TD3算法?(附代码及代码分析) - 知乎
2. 强化学习论文笔记(4)TD3 - 知乎
3. 强化学习经典算法笔记(十四):双延迟深度确定性策略梯度算法TD3的PyTorch实现_hhy_csdn的博客-CSDN博客_td3算法 强化学习经典算法笔记(十四):双延迟深度确定性策略梯度算法TD3的PyTorch实现_hhy_csdn的博客-CSDN博客_td3算法4. 强化学习之TD3(pytorch实现)_微笑小星的博客-CSDN博客_td3强化学习