interview
- 1.PyTorch
-
- 1.1 Conv2d
- 1.2 dataset,dataloader
- 1.3 训练pipeline
- 1.4 梯度归零
- 1.5 torch保存模型种类及区别
- 2.目标检测
-
- 2.1 yolo3,4,5,7区别
- 2.2 yolo使用的loss(ciou,BCE等等)
-
- ciou
- BCEloss
- L1,L2,CE,BCE
- 2.3 图像增强
- 2.4 IOU计算公式
- 3.机器学习/深度学习基础
-
- 3.1 卷积公式
- 3.2 卷积层,pooling层,全连接层的作用分别是什么?
- 3.3 BN层
- 3.4 过拟合和欠拟合分别是什么,如何改善?
- 3.5 说明监督学习和半监督学习,无监督学习的区别
- 3.6 常用图像预处理
- 3.7 逻辑回归/线性回归
- 4. 数据结构
-
- 4.1 顺序存储与链式存储
- 4.2 数组和链表的区别?
- 4.3 栈和队列的区别
- 4.4 线性存储结构及非线性存储结构
- 4.5 邻接矩阵
- 5. 图像处理
-
- 5.1 图像二值化
- 5.2 简述膨胀和腐蚀操作
- 5.3 常用的插值方法有哪些?
- 5.4 彩色图像、灰度图像、二值图像和索引图像的区别是什么?
- 5.5 常用的边缘提取方法有哪些?
- 5.6 高斯滤波器的原理是什么?
- 5.7 Hough变换
- 5.8 Canny边缘检测的流程
- 5.9 说明LBP特征向量提取的步骤
- 5.10 图像中低频信息和高频信息的定义
- 5.11 图像高/低通滤波的相关概念
- 5.12 色深的概念
- 5.13 常用的色彩空间格式
- 6.TensorRT
- 7. ROS
- 8. python
- 9. c++
1.PyTorch
1.1 Conv2d
实现2d卷积操作

1.2 dataset,dataloader
分别负责可被Pytorhc使用的数据集的创建以及向训练传递数据的任务。如果想个性化自己的数据集或者数据传递方式,也可以自己重写子类。Dataset是DataLoader实例化的一个参数
torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。
可以通过继承后重写Init,getitem等方法自定义
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。
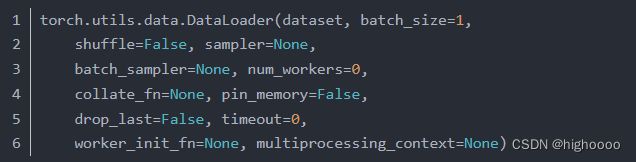
参数:
dataset (Dataset) – 决定数据从哪读取或者从何读取;
batch_size (python:int, optional) – 批尺寸(每次训练样本个数,默认为1)
shuffle (bool, optional) –每一个 epoch是否为乱序 (default: False).
num_workers (python:int, optional) – 是否多进程读取数据(默认为0);
drop_last (bool, optional) – 当样本数不能被batchsize整除时,最后一批数据是否舍弃(default: False)
pin_memory(bool, optional) - 如果为True会将数据放置到GPU上去(默认为false)
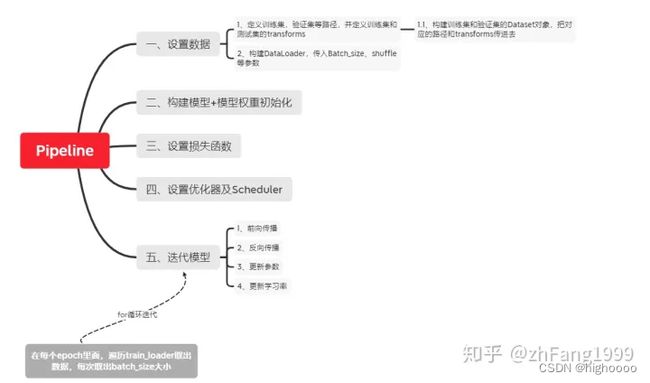
1.3 训练pipeline
1.4 梯度归零
为什么每一轮batch需要设置optimizer.zero_grad:
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉;但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积,因此这里就需要每个batch设置一遍zero_grad 了。

1.5 torch保存模型种类及区别

2.目标检测
2.1 yolo3,4,5,7区别
yolov4/yolov5
2.2 yolo使用的loss(ciou,BCE等等)
ciou
考虑两个框中心点的距离及两个框最小外包对角线距离
相比于IOU的优点:
1.IOU没有考虑到两个框之间的位置信息,如果两个框没有重叠,它的IOU=0,没法进行反向传播。
2.还有一点,就是为什么之前的所有目标检测的网络中没有用iou直接作为损失函数。就是因为对于大小不同的框,iou值相同,但是其重叠程度却不同(说白了,就是对尺度不敏感)。在ciou中,由于有v这个概念,所以就使这种情况不可能再出现(个人理解,不对还请指正)。
BCEloss
BCE/CE
CE用于多分类
BCE用于二分
多分类也可以叠加多个BCE
BCE主要适用于二分类的任务,而且多标签分类任务可以简单地理解为多个二元分类任务叠加。所以BCE经过简单修改也可以适用于多标签分类任务。使用BCE之前,需要将输出变量量化在[0,1]之间(可以使用Sigmoid激活函数)。上边我们也深度刨析了Sigmoid和Softmax两种激活函数,探究其统计学本质,Sigmoid的输出为伯努利分布,也就是我们常说的二项分布;而Softmax的输出表示为多项式分布。所以Sigmoid通常用于二分类,Softmax用于多类别分类。
L1,L2,CE,BCE
L1,L2,CE,BCE loss
2.3 图像增强
(1)几何变换类,主要是对图像进行几何变换操作,包括翻转,旋转,裁剪,变形,缩放等。
(2)颜色变换类,指通过模糊、颜色变换、擦除、填充等方式对图像进行处理。
yolov3:
1.Mosaic(马赛克)
2.随机旋转、平移、缩放、错切、hsv增强
yolov5:
1.Mosaic数据增强
2.Copy paste数据增强
3.Random affine仿射变换
4.MixUp数据增强
5.HSV随机增强图像
6随机水平翻转
2.4 IOU计算公式
# xmin ymin xmax ymax
def iou(box1, box2):
# 1.interarea
# 2.box1 area
# 3.box2 area
# 4.interarea / (box1area + box2area - interarea)
x1 = max(box1[0],box2[0])
y1 = max(box1[1],box2[1])
x2 = min(box1[2],box2[2])
y2 = min(box1[3],box2[3])
interarea = max(0, x2-x1) * max(0, y2-y1)
box1area = (box1[2] - box1[0]) * (box1[3] - box1[1])
box2area = (box2[2] - box2[0]) * (box2[3] - box2[1])
iou = interarea / (box1area + box2area - interarea)
print(iou)
3.机器学习/深度学习基础
3.1 卷积公式

3.2 卷积层,pooling层,全连接层的作用分别是什么?
卷积层的特点是局部感知、参数共享和多核卷积。
pooling:物理下采样
全连接:分类
3.3 BN层
对象:只对每一个batch进行Normalization
原理:
(1).强行将数据拉回到均值为0,方差为1的正态分布上,这样不仅可以让数据保持相近的分布,而且避免发生梯度消失。
(2).加入缩放和平移变量的原因:将数据拉回到均值为0
作用:
(1). 加快网络的训练和收敛的速度
(2). 控制梯度爆炸防止梯度消失
(3). 防止过拟合
BN层位于激活函数之前(非线性单元前)
BN层本质上是一个归一化网络层,可以替代局部响应归一化层(Local Response Normalization,LRN层)。
可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)论文中提到可以提高1%的精度。
3.4 过拟合和欠拟合分别是什么,如何改善?
抑制过拟合的方法:
(1)数据处理:清洗数据、减少特征维度、类别平衡。
(2)辅助分类节点:在Google Inception V1中,采用了辅助分类节点的策略,即将中间某一层的输出用作分类,并按一个较小的权重加到最终的分类结果中,这样相当于做了模型的融合,同时给网络增加了反向传播的梯度信号,提供了额外的正则化的思想。
(3)正则化:获取更多数据:从数据源获得更多数据,或数据增强。
欠拟合:
(1)做特征工程,添加更多的特征项。即提供的特征不能表示出那个需要的函数。
(2)减少正则化参数。即使得模型复杂一些。
(3)使用更深或者更宽的模型。
(4)使用集成方法。融合几个具有差异的弱模型,使其成为一个强模型。
3.5 说明监督学习和半监督学习,无监督学习的区别
监督学习:训练集全标注样本
半监督学习:训练集同时包含有标记样本和未标记样本数据,有特征值,但是一部分数据有目标值,一部分没有。
无监督学习:训练集只包含数据 无标注
3.6 常用图像预处理
一般先对数据进行归一化(Normalization)处理【0,1】,再进行标准化(Standardization)操作,用大数定理将数据转化为一个标准正态分布,最后再进行一些数据增强处理。
归一化后,可以提升模型精度。不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
标准化后,可以加速模型收敛。最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
3.7 逻辑回归/线性回归
逻辑回归/线性回归
4. 数据结构
4.1 顺序存储与链式存储
顺序存储结构是用一段连续的存储空间来存储数据元素,可以进行随机访问,访问效率较高。链式存储结构是用任意的存储空间来存储数据元素,不可以进行随机访问,访问效率较低。
4.2 数组和链表的区别?
从逻辑结构来看:数组的存储长度是固定的,它不能适应数据动态增减的情况。链表能够动态分配存储空间以适应数据动态增减的情况,并且易于进行插入和删除操作。
从访问方式来看:数组在内存中是一片连续的存储空间,可以通过数组下标对数组进行随机访问,访问效率较高。链表是链式存储结构,存储空间不是必须连续的,可以是任意的,访问必须从前往后依次进行,访问效率较数组来说比较低。
如果从第i个位置插入多个元素,对于数组来说每一次插入都需要往后移动元素,每一次的时间复杂度都是O(n),而单链表来说只需要在第一次寻找i的位置时时间复杂度为O(n),其余的插入和删除操作时间复杂度均为O(1),提高了插入和删除的效率。
4.3 栈和队列的区别
队列是允许在一段进行插入另一端进行删除的线性表,对于进入队列的元素按“先进先出”的规则处理,在表头进行删除在表尾进行插入。
栈是只能在表尾进行插入和删除操作的线性表。对于插入到栈的元素按“后进先出”的规则处理,插入和删除操作都在栈顶进行。由于进栈和出栈都是在栈顶进行,所以要有一个size变量来记录当前栈的大小,当进栈时size不能超过数组长度,size+1,出栈时栈不为空,size-1。
4.4 线性存储结构及非线性存储结构
线性存储结构,包括顺序表、链表、栈、队列、数组、广义表。
非线性存储结构,二维数组、多维数组、广义表、树结构、图结构
4.5 邻接矩阵
邻接矩阵是图的一种存储形式,是以二维数组表示有n个顶点的图,而矩阵中表示图中顶点之间弧信息的存储方式。
c++实现
5. 图像处理
5.1 图像二值化
根据阈值将像素设置为0/255
5.2 简述膨胀和腐蚀操作
消除噪声
1.分割独立的图像元素,连接相邻的图像元素;
2.寻找图像中明显的极大值域或极小值域;
膨胀,将图像的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大。
腐蚀,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。
5.3 常用的插值方法有哪些?
1、最近邻插值法:周围4个像素取加权平均 权重根据距这4个像素点到生成点的X,Y距离生成
特点:最近邻插值法虽然计算量较小,但可能会造成插值生成的图像灰度上的不连续,在灰度变化的地方可能出现明显的锯齿状
2、双线性插值:通过周围四个点来算出一个点
3、双三次插值:利用周围16个像素点计算出一个像素点的值。
5.4 彩色图像、灰度图像、二值图像和索引图像的区别是什么?
彩色图像的每个像素通常是由红、绿、蓝三个分量来表示的,分量在[0,255]区间内。
灰度图像是每个像素只有一个采样颜色的图像,这类图像通常显示为从最暗黑色到最亮的白色的灰度,尽管理论上这个采样可以任何颜色的不同深浅,有256个灰度级。
索引图像除了存放图像的二维矩阵外,还包括一个称之为颜色索引矩阵MAP的二维数组。MAP的大小由存放图像的矩阵元素值域决定,如矩阵元素值域为[0,255],则MAP矩阵的大小为256×3,用MAP=[RGB]表示。MAP中每一行的三个元素分别指定该行对应颜色的红、绿、蓝单色值,MAP中每一行对应图像矩阵像素的一个灰度值,如某一像素的灰度值为64,则该像素就与MAP中的第64行建立了映射关系,该像素在屏幕上的实际颜色由64行的[RGB]组合决定。
5.5 常用的边缘提取方法有哪些?
一阶导数:sobel、Roberts、prewitt等算子
二阶导数:Laplacian、Canny算子
5.6 高斯滤波器的原理是什么?
通俗的讲,高斯滤波就是对整幅图像进行加权平均的过程,每一个像素点的值,都由其本身和邻域内的其他像素值经过加权平均后得到。
5.7 Hough变换
像素点坐标到霍夫空间,若多条直线在霍夫空间中相交于同一个点,那么认为在原坐标系中是同一条直线
5.8 Canny边缘检测的流程
1.高斯滤波
2.计算像素点的梯度
3.NMS
4.双阈值检测确定真实和潜在边缘
5.抑制孤立的弱边缘完成检测
5.9 说明LBP特征向量提取的步骤
(1)首先将检测窗口划分为16×16的小区域(cell);
(2)对于每个cell中的一个像素,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数,即得到该窗口中心像素点的LBP值;
(3)然后计算每个cell的直方图,即每个数字(假定是十进制数LBP值)出现的频率;然后对该直方图进行归一化处理。
(4)最后将得到的每个cell的统计直方图进行连接成为一个特征向量,也就是整幅图的LBP纹理特征向量;
5.10 图像中低频信息和高频信息的定义
低频信息(低频分量):表示图像中灰度值变化缓慢的区域,对应着图像中大块平坦的区域。
高频信息(高频分量):表示图像中灰度值变化剧烈的区域,对应着图像的边缘(轮廓)、噪声(之所以说噪声也是高频分量,是因为图像噪声在大部分情况下都是高频的)以及细节部分。
5.11 图像高/低通滤波的相关概念
图像本身也可以看成是一个二维的信号,其中像素点数值的高低代表信号的强弱:
高频:图像中灰度变化剧烈的点,一般是图像轮廓或者是噪声。
低频:图像中平坦的、变化不大的点,也就是图像中的大部分区域。
常见的低通滤波器有:线性的均值滤波器、高斯滤波器、非线性的双边滤波器、中值滤波器。
常见的高通滤波器有:Canny算子、Sobel算子、拉普拉斯算子等边缘滤波算子。
5.12 色深的概念
色深(Color Depth)指的是色彩的深度,即精细度。在数字图像中,最小的单元是像素,在RGB三通道图像中,每个像素都由R,G,B三个通道组成,通常是24位的二进制位格式来表示。这表示颜色的2进制位数,就代表了色深。
5.13 常用的色彩空间格式
深度学习中常用的色彩空间格式:RGB,RGBA,HSV,HLS,Lab,YCbCr,YUV等。
RGB色彩空间以Red(红)、Green(绿)、Blue(蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色,所以俗称三基色模式。
RGBA是代表Red(红)、Green(绿)、Blue(蓝)和Alpha(透明度)的色彩空间。
HSV色彩空间(Hue-色调、Saturation-饱和度、Value-亮度)将亮度从色彩中分解出来,在图像增强算法中用途很广。
HLS色彩空间,三个分量分别是色相(H)、亮度(L)、饱和度(S)。
Lab色彩空间是由CIE(国际照明委员会)制定的一种色彩模式。自然界中任何一点色都可以在Lab空间中表达出来,它的色彩空间比RGB空间还要大。
YCbCr进行了图像子采样,是视频图像和数字图像中常用的色彩空间。在通用的图像压缩算法中(如JPEG算法),首要的步骤就是将图像的颜色空间转换为YCbCr空间。
YUV色彩空间与RGB编码方式(色域)不同。RGB使用红、绿、蓝三原色来表示颜色。而YUV使用亮度、色度来表示颜色。
6.TensorRT
TensorRT全方位笔记
7. ROS
ROS是一个依赖于linux的机器人操作系统
ROS依赖于各种功能包来供node应用使用
元功能包是多个功能包的集合
主节点master负责node和node之间的连接和通信 通过roscore运行 后可注册各个node
普通节点node是ROS最小处理器单元/可执行程序/进程
每个node注册时,要注册node名称,发布者(publisher)、订阅者(subscriber)、服务服务器(service server)、服务客户端(service client)的名称等等
roslaunch每次只能启动一个node
可通过launch文件来启动多个node
ros的通信主要需要了解以下四个概念:节点(node)、消息(messages)、话题(topic)、服务(service)、动作(action)
ROS基础概念