fisher信息矩阵_Fisher线性判别介绍及Python示例

为了处理两个或多个类的分类问题,大多数机器学习(ML)算法的工作方式是相同的。
通常,它们对输入数据应用某种类型的转换,其效果是将原始输入维度减少到更小的数字。目标是将数据投影到一个新的空间中。然后,一旦投影,该算法试图通过寻找线性分离来对这些点进行分类。
对于输入维度较小的问题,任务稍微容易一些。以下面的机器学习数据集为例。
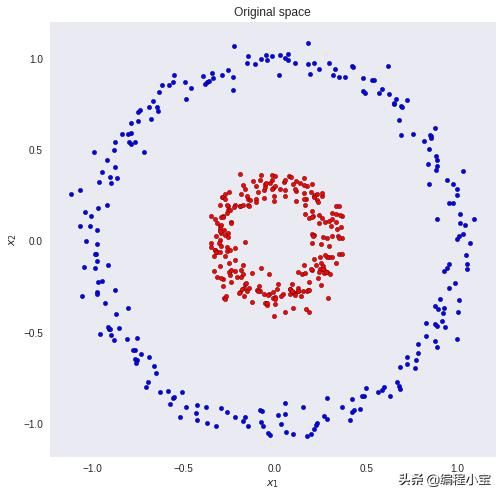
假设我们想要正确地分类红色和蓝色圆圈。
很明显,一个简单的线性模型我们不会得到一个好的结果。没有将输入和权重映射到正确类的线性组合。但是如果我们可以转换数据以便我们可以画一条线将这两个类分开呢?
如果我们对两个输入特征向量进行平方,就会发生这种情况。现在,线性模型可以很容易地对蓝色和红色的点进行分类。

然而,有时我们不知道应该使用哪种转换。实际上,找到最好的表示不是一个简单的问题。我们可以对数据应用许多转换。同样,它们中的每一个都可能导致不同的分类器(就性能而言)。
解决这个问题的一个方法是学习正确的转换。这被称为表示学习(representation learning),它正是深度学习算法所做的。
神奇的是,我们不需要“猜测”哪种转换会导致数据的最佳表示。该算法将弄明白。
但是,请记住,无论表示学习还是手工制作的转换,模式都是相同的。我们需要以某种方式更改数据,以便它可以轻松分离。
让我们回过头来考虑一个更简单的问题。
我们将探讨Fisher线性判别(FLD)如何设法将多维数据分类为多个类。
Fisher线性判别
首先,考虑二元分类问题(K = 2)的情况。R²中的蓝色和红色点。通常,我们可以采用任何D维输入向量并将其投影到D'维。这里,D表示原始输入尺寸,而D'是投影空间尺寸。在本文中,考虑D'小于D。
在投影到一维(数字线)的情况下,即D'= 1,我们可以选择阈值t来分隔新空间中的类。给定输入向量x:
- 如果预测值y> = t那么,x属于C1类(class 1)。
- 否则,它被归类为C2(class 2)。
注意,向量y (predictions) 等于所述线性组合O输入X和weights W → y=Wᵀx。
以下面的数据集作为示例。我们希望将原始数据维度从D = 2减少到D'= 1。换句话说,我们想要一个转换T,它将2D中的向量映射到1D - T(v)=ℝ² →ℝ¹。
首先,让我们计算两个类的平均向量m1和m2。

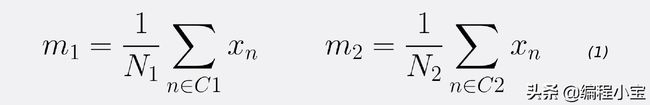
注意N1和N2分别表示类C1和类C2中的点数。现在,考虑使用类means作为分离的度量。换句话说,我们想把数据投影到向量W上加入这两个类的均值。
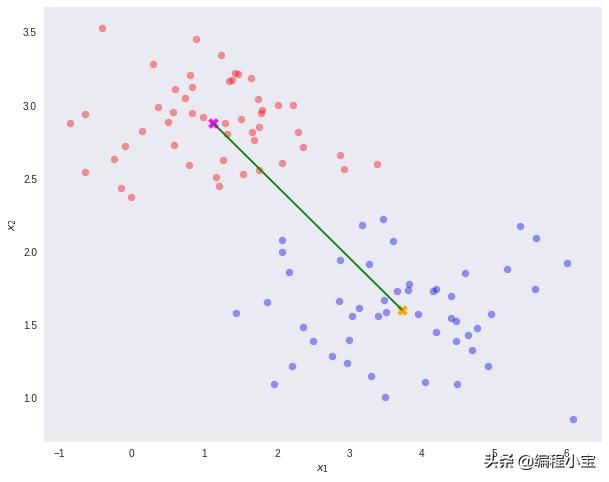
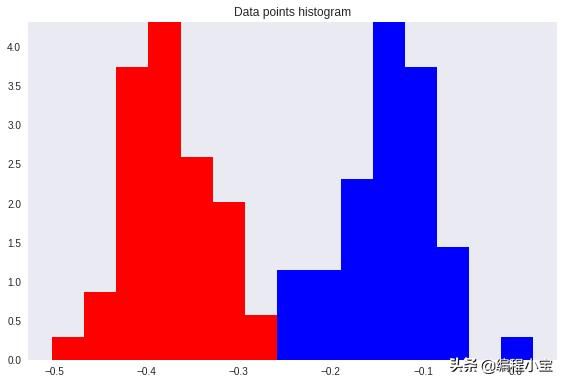
重要的是要注意,任何类型的投影到较小的维度可能涉及一些信息的丢失。在这种情况下,请注意这两个类在其原始空间中可以清楚地分开。
然而,在重新投影之后,数据显示出某种类重叠 - 由图上的黄色椭圆和下面的直方图显示。
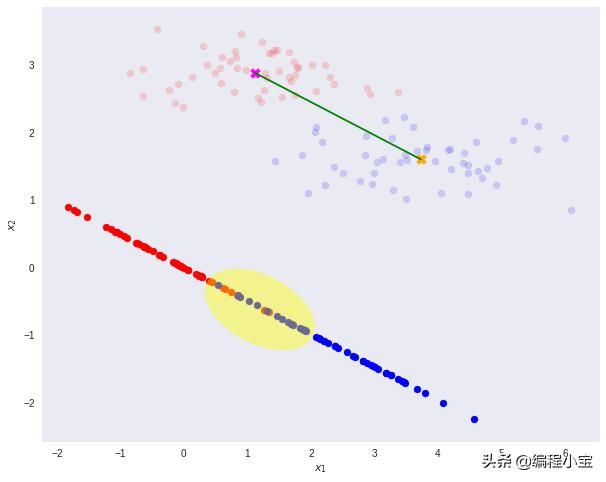
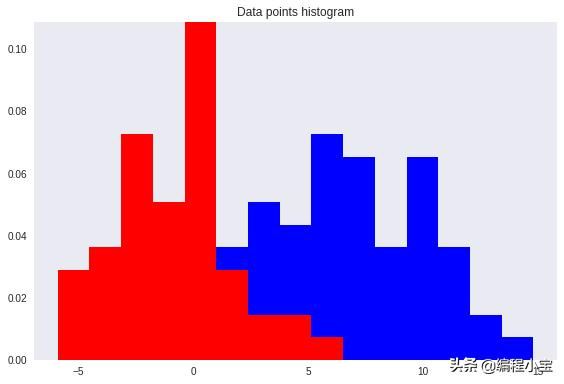
这就是Fisher线性判别法发挥作用的地方。
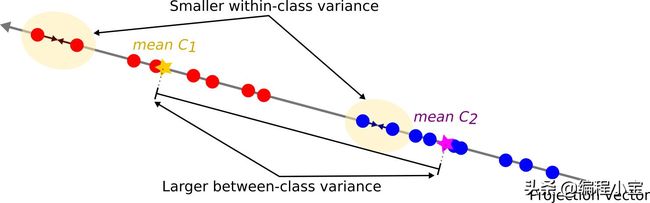
Fisher提出的想法是最大化一个函数,它将在投影类平均值之间产生较大的分离,同时在每个类中给出一个小的方差,从而最小化类重叠。
换句话说,FLD选择最大化类别分离的投影。为此,它最大化了类间方差与类内方差之间的比率。
简而言之,为了将数据投影到更小的维度并避免类重叠,FLD维护了2个属性。
- 机器学习数据集类之间存在较大方差。
- 每个机器学习数据集类中的小方差。
请注意,较大的类间方差意味着预计的类平均值应尽可能远。相反,小的类内方差具有使投影数据点彼此更接近的效果。
为了找到具有以下属性的投影,FLD 使用以下标准学习权重向量W.
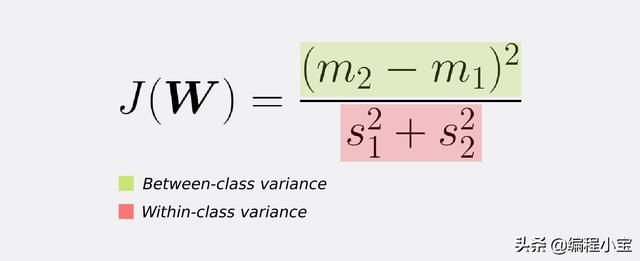
将(1)(2)式中给出的均值m1和m2以及方差s代入(1)(2)式中得到(3)式,(3)对W求导(经过简化)得到W的学习方程(4)。
也就是说,W(我们想要的变换)正比于类内协方差矩阵的逆乘以类均值的差。

正如所料,结果允许通过简单的阈值处理实现完美的类别分离。
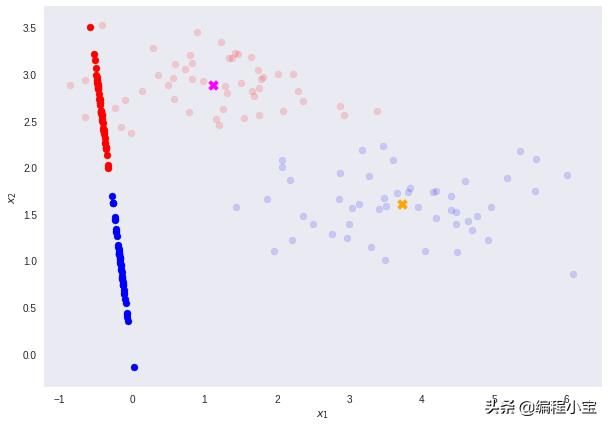
Fisher线性判别(多类)
对于超过K> 2类的情况,我们可以泛化FLD 。
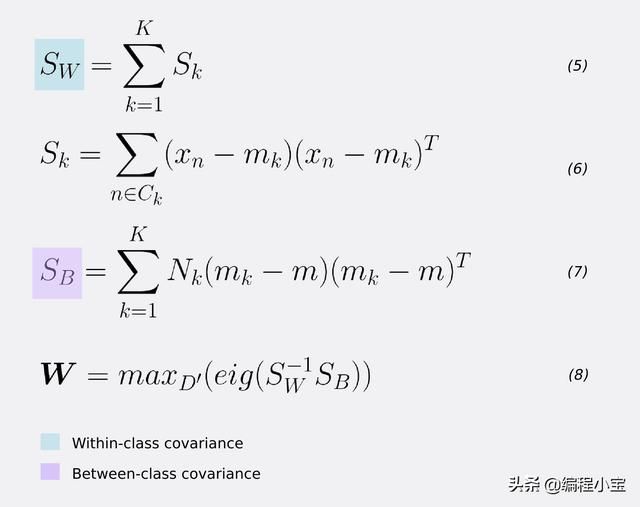
对于类内协方差矩阵SW,对于每个类,取集中输入值与其转置之间的矩阵乘法的总和。等式5和6。
为了估计类间协方差SB,对于每个类k = 1,2,3,...,K,取局部类的平均值mk和全局平均值m的外积。然后,按类k- 等式7中的记录数量进行缩放。
FLD标准的最大化通过SW和SB的逆之间的矩阵乘法的特征分解来解决。因此,为了找到权重向量W,我们采用对应于它们的最大特征值的D'特征向量(等式8)。
换句话说,如果我们想把数据维数从D=784减到D ' =2,变换向量W由两个特征向量组成它们对应于D ' =2个最大的特征值。这给出了W = (N,D ')的最终形状,其中N是输入记录的数量,D '是减少的特征空间维度。
建立线性判别式
到目前为止,我们仅使用Fisher线性判别式作为降维方法。为了真正创建判别式,我们可以在每个类K的D维输入向量x上建模多元高斯分布,如下所示:
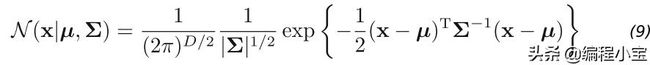
这里μ(均值)是D维向量。Σ(sigma)是DxD矩阵 - 协方差矩阵。并且| Σ | 是协方差的决定因素。行列式是衡量协方差矩阵Σ stretches or shrinks空间的程度。
在Python中,它看起来像这样。

高斯分布的参数:μ和Σ,计算每个类k = 1, 2, 3,…, K预期的输入数据。我们可以使用每个类中训练集数据点的分数来推断先验P(Ck)类的概率(第11行)。
一旦我们得到高斯参数和先验,我们就可以分别计算每个类k = 1,2,3,...,K的类条件密度P(x | Ck)。为此,我们首先将D维输入向量x投影到新的D'空间。请记住D 。然后,我们为每个投影点评估等式9。最后,我们可以使用等式10 得到每个类k = 1,2,3,...,K的后验概率P(Ck | x)。
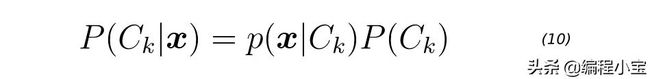
在下面的score函数的第8行上评估等式10。

然后我们可以将输入向量x分配给具有最大后验的类k。
测试MNIST
使用MNIST作为测试数据集。如果我们选择将原始输入尺寸D = 784减小到D'= 2,我们可以在测试数据上获得大约56%的准确度。但是,如果我们将预计的空间维数增加到D'= 3,我们的准确度将达到近74%。这两个投影还可以更容易地显示最终的特征空间。
导入库
from numpy.linalg import inv,pinvimport numpy as npfrom numpy.linalg import eigimport numpy as npimport tensorflow as tffrom sklearn.model_selection import train_test_splitimport matplotlib.cm as cmimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import axes3d
辅助函数
class DataSet: def __init__(self, data, targets, valid_classes=None): if valid_classes is None: self.valid_classes = np.unique(targets) else: self.valid_classes = valid_classes #print(self.valid_classes) self.number_of_classes = len(self.valid_classes) self.data = self.to_dict(data, targets) def to_dict(self, data, targets): data_dict = {} for x, y in zip(data, targets): if y in self.valid_classes: if y not in data_dict: data_dict[y] = [x.flatten()] else: data_dict[y].append(x.flatten()) for i in self.valid_classes: data_dict[i] = np.asarray(data_dict[i]) return data_dict def get_data_by_class(self, class_id): if class_id in self.valid_classes: return self.data[class_id] else: raise ("Class not found.") def get_data_as_dict(self): return self.data def get_all_data(self): data = [] labels = [] for label, class_i_data in self.data.items(): data.extend(class_i_data) labels.extend(class_i_data.shape[0] * [label]) data = np.asarray(data) labels = np.asarray(labels) return data, labels
LDAClassifier类
class LDAClassifier: def __init__(self, projection_dim): self.projection_dim = projection_dim self.W = None # weights self.g_means, self.g_covariance, self.priors = None, None, None def fit(self,X): means_k = self.__compute_means(X) Sks = [] for class_i, m in means_k.items(): sub = np.subtract(X[class_i], m) Sks.append(np.dot(np.transpose(sub), sub)) Sks = np.asarray(Sks) Sw = np.sum(Sks, axis=0) # shape = (D,D) Nk = {} sum_ = 0 for class_id, data in X.items(): Nk[class_id] = data.shape[0] sum_ += np.sum(data, axis=0) self.N = sum(list(Nk.values())) # m is the mean of the total data set m = sum_ / self.N SB = [] for class_id, mean_class_i in means_k.items(): sub_ = mean_class_i - m SB.append(np.multiply(Nk[class_id], np.outer(sub_, sub_.T))) # between class covariance matrix shape = (D,D). D = input vector dimensions SB = np.sum(SB, axis=0) # sum of K (# of classes) matrices matrix = np.dot(pinv(Sw), SB) # find eigen values and eigen-vectors pairs for np.dot(pinv(SW),SB) eigen_values, eigen_vectors = eig(matrix) print("eigen_values: