机器学习分类模型中的评价指标介绍:准确率、精确率、召回率、ROC曲线
文章来源:https://blog.csdn.net/wf592523813/article/details/95202448
1 二分类评价指标
准确率,精确率,召回率,F1-Score, AUC, ROC, P-R曲线
1.1 准确率(Accuracy)
评价分类问题的性能指标一般是分类准确率,即对于给定的数据,分类正确的样本数占总样本数的比例。
注意:准确率这一指标在Unbalanced数据集上的表现很差,因为如果我们的正负样本数目差别很大,比如正样本100个,负样本9900个,那么直接把所有的样本都预测为负, 准确率为99%,但是此分类模型实际性能是非常差的,因为它把所有正样本都分错了。
1.2 精确率(Precision)
对于二分类问题常用的评价指标是精确率和召回率。通常以关注的类为正类,其他类为负类,分类器在数据集上的预测或者正确或者不正确,我们有4中情况:
- TP:True Positive, 把正类预测为正类;
- FP:False Positive,把负类预测为正类;
- TN:True Negative, 把负类预测为负类;
- FN:False Negative,把正类预测为负类
在混淆矩阵中表示如下: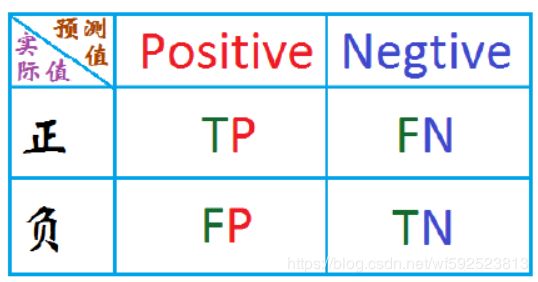
精确率是指在预测为正类的样本中真正类所占的比例,直观上来解释精确率就是说
我现在有了这么的预测为正的样本,那么这些样本中有多少是真的为正呢?
P = TP/(TP+FP)
1.3 查全率(召回率 Recall)
召回率是指在所有的正类中被预测为正类的比例,直观上来说召回率表示我现在预测为正的这些值中,占了所有的为正的样本的多大比例呢?
R = TP/(TP+FN)
不同的分类问题,对精确率和召回率的要求也不同。
例如:假币预测,就需要很高的精确率,我需要你给我的预测数据具有很高的准确性。
肿瘤预测就需要很高的召回率。“宁可错杀三千,不可放过一个”。
1.4 F1-Score
F1-Score: 精确率和召回率的调和平均。 即:
2/F1 = 1/P + 1/R
F1=2P*R/(P+R)
因为Precision和Recall是一对相互矛盾的量,当P高时,R往往相对较低,当R高时, P往往相对较低,所以为了更好的评价分类器的性能,一般使用F1-Score作为评价标准来衡量分类器的综合性能。
1.5 ROC曲线和AUC
TPR:True Positive Rate,真正率, TPR代表能将正例分对的概率
TPR=TP/TP+FN
FPR: False Positive Rate, 假正率, FPR代表将负例错分为正例的概率
FPR=FP/FP+TN
使用FPR作为横坐标,TPR作为纵坐标得到ROC曲线如下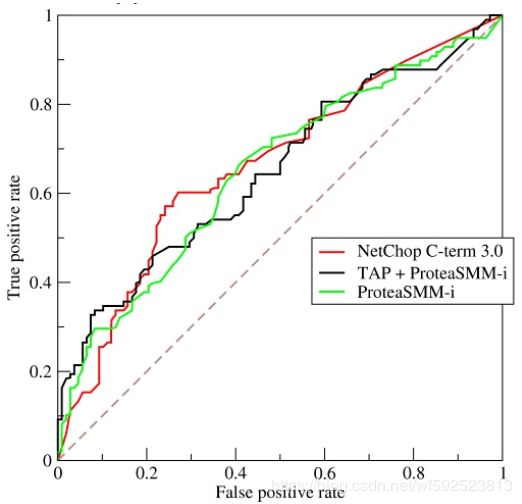
ROC曲线中的四个点和一条线
-
(0,1): FN = 0, FP = 0, 表示所有样本都正确分类,这是一个完美的分类器;
-
(1,0):TN = 0, TP = 0, 表示所有样本都分类错误,这是一个最糟糕的分类器;
-
(0, 0): FP = 0, TP = 0, 表示所有样本都分类为负
-
(1,1): TN = 0, FN = 0, 表示左右样本都分类为正
经过以上分析,ROC曲线越靠近左上角,该分类器的性能越好。
上图虚线与 y = x,该对角线实际上表示一个随机猜测的分类器的结果。
ROC曲线画法:在二分类问题中,我们最终得到的数据是对每一个样本估计其为正的概率值(Score),我们根据每个样本为正的概率大小从大到小排序,然后按照概率从高到低,一次将“Score”值作为阈值threshold,当测试样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。每次选取一个不同的threshold,就可以得到一组FPR和TPR,即ROC曲线上的一点。
AUC:(Area Under roc CurveROC)曲线下的面积,引入AUC的原因是量化评价指标。
AUC的面积越大,分类效果越好。AUC小于1,另一方面,正常的分类器你应该比随机猜测效果要好吧?所以 0.5 <= AUC <= 1
AUC表征了分类器把正样本排在负样本前边的能力。这里的意思其实是指数据按照其为正的概率从大到小排序之后,正样本排在负样本前边的能力。AUC越大,就有越多的正样本排在负样本前边。极端来看,如果ROC的(0, 1)点,所有的正样本都排在负样本的前边。
1.6 ROC 与 P, R对比
**ROC曲线特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。**在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。)
下图是ROC曲线和Precision-Recall曲线的对比: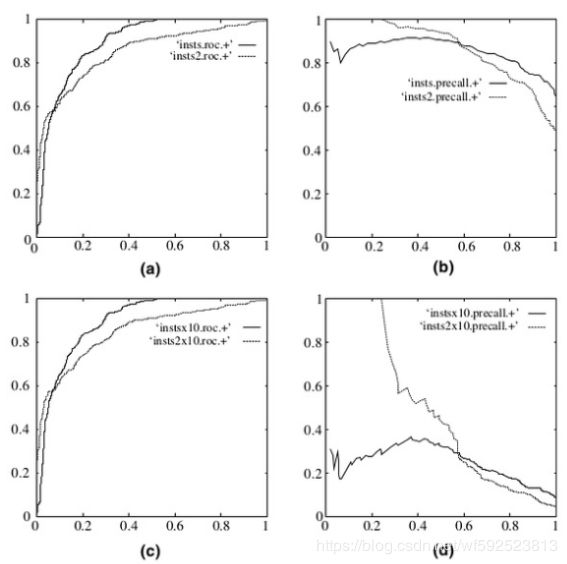
a,c为ROC曲线,b,d为P-R曲线;
a,b 为在原始测试集(balanced)上的结果,c,d为把原始数据集的负样本增加10倍后的结果。很明显,ROC曲线基本保持不变,P-R曲线变化较大。
为什么取AUC较好?因为一个二分类问题,如果你取P或R的话,那么你的评价结果和你阈值的选取关系很大,但是我这个一个分类器定了,我希望评价指标是和你取得阈值无关的,也就是需要做与阈值无关的处理。所以AUC较P-R好
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
acc = accuracy_score(y_true, y_pred)
2 多分类评价指标
对于二分类问题,我们有很多评价指标,因为只有正类和负类两种,往往我们只关心正类的准确率和召回率。但是对于多分类问题,有些二分类的评价标准就不怎么适用了。最近实习涉及到多分类,在模型评价指标选取费了不少时间,对于常用的多分类评价指标进行整理以便日后使用。一种方法是将多分类问题转化为多个2vs2问题进行讨论,步骤比较复杂。还有一种是直接定义的多分类指标。
2.1 多分类转化为2vs2问题来评价
准确率:与二分类相同,预测正确的样本占总样本的比例。
精确率: ‘macro’, 对于每个标签,分别计算Precision,然后取不加权平均
查全率: ‘macro’,对于每个标签,分别计算Recall,然后取不加权平均
F1-Score:‘macro’, 对于每个标签,分别计算发,然后取不加权平均
‘micro’, 将n个二分类评价的TP,FP,FN对应相加,计算P和R,然后求得F1
一般macro-f1和micro-f1都高的分类器性能好
2.2 直接定义的多分类指标
2.2.1Kappa系数
kappa系数是用在统计学中评估一致性的一种方法,取值范围是[-1,1],实际应用中,一般是[0,1],与ROC曲线中一般不会出现下凸形曲线的原理类似。这个系数的值越高,则代表模型实现的分类准确度越高。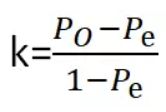
- 0表示总体分类精度
- Pe表示SUM(第i类真实样本数*第i类预测出来的样本数)/样本总数平方

from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y_true,y_pred,label=None) #(label除非是你想计算其中的分类子集的kappa系数,否则不需要设置)
2.2.2. 海明距离
海明距离也适用于多分类的问题,简单来说就是衡量预测标签与真实标签之间的距离,取值在0~1之间。距离为0说明预测结果与真实结果完全相同,距离为1就说明模型与我们想要的结果完全就是背道而驰。
from sklearn.metrics import hamming_loss
ham_distance = hamming_loss(y_true,y_pred)
2.2.3.杰卡德相似系数
它与海明距离的不同之处在于分母。当预测结果与实际情况完全相符时,系数为1;当预测结果与实际情况完全不符时,系数为0;当预测结果是实际情况的真子集或真超集时,距离介于0到1之间。
我们可以通过对所有样本的预测情况求平均得到算法在测试集上的总体表现情况。
from sklearn.metrics import jaccard_similarity_score
jaccrd_score = jaccrd_similarity_score(y_true,y_pred,normalize = default)
#normalize默认为true,这是计算的是多个类别的相似系数的平均值,normalize = false时分别计算各个类别的相似系数
2.2.4.铰链损失
铰链损失(Hinge loss)一般用来使“边缘最大化”(maximal margin)。损失取值在0~1之间,当取值为0,表示多分类模型分类完全准确,取值为1表明完全不起作用。
from sklearn.metrics import hinge_loss
hinger = hinger_loss(y_true,y_pred)
参考文档:https://www.cnblogs.com/futurehau/p/6109772.html
https://www.jianshu.com/p/573ba75aec94