redis缓存击穿问题解决
网上看了很多解决缓存击穿的方案,
我觉得不够好,自己总结了一番
本文尽量使用大白话,尽量不写代码,请认真读
希望能让你们满意
彻底解决redis缓存击穿问题
- 1. redis的缓存击穿是什么?
- 2. 如何解决缓存击穿
-
- 2.1 普通的redis缓存使用方式
-
- 2.1.1 使用redis缓存
-
- 查询逻辑
- 优点
- 缺点
- 适用情况
- 2.2 解决redis缓存击穿问题
-
- 2.2.1 主动刷新缓存设计
-
- 查询逻辑
- 优点
- 缺点
- 适用情况
- 2.2.2 使用redis的分布式锁
-
- 查询逻辑
- 优点
- 缺点
- 适用情况
- 2.2.3 普通加jvm的锁查询缓存
-
- 查询逻辑
- 优点
- 缺点
- 适用情况
- 2.2.4 多级缓存
-
- 查询逻辑
- 优点
- 缺点
- 适用情况
- 2.2.5 其他注意点
1. redis的缓存击穿是什么?
如果我有一个业务,需要查询数据库,这个查询很耗时,
且业务上来看这个要非常频繁的取查询它
那么通常我可以把查询的结果保存在redis,设置一个符合业务的过期时间
然后以后的查询都直接查redis
redis的高QPS特性,可以很好的解决查数据库很慢的问题
隐患:
如果我们系统的并发很高,
在某个时间节点,突然缓存失效,这时候有大量的请求打过来
那么由于redis没有缓存数据,这时候我们的请求会全部去查一遍数据库
这时候我们的数据库服务会面临非常大的风险,要么连接被占满
要么其他业务不可用
这种情况就是redis的缓存击穿
2. 如何解决缓存击穿
解决缓存击穿换句话说,就是要保证最终落在硬盘上的查询操作要可控
注意这里使用的是可控,而不是少
2.1 普通的redis缓存使用方式
先来看看普通的redis缓存设计
2.1.1 使用redis缓存
- 比较简单的设计,可以在数据需要的时候再加载
查询逻辑
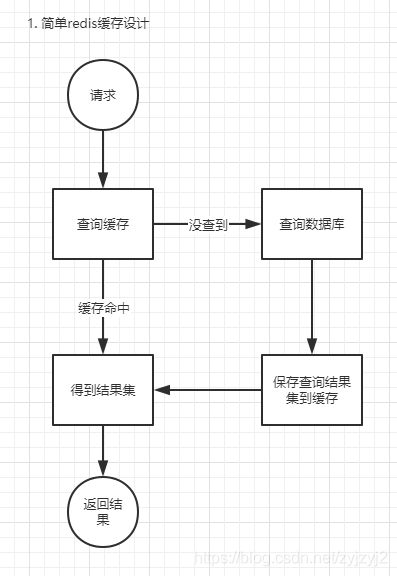
由此图可以看出,查询是只有两种情况的:
- 缓存命中,直接返回缓存结果
- 缓存未命中,查数据库,再返回结果
优点
- 设计简单,开发效率高
- 不会侵入业务代码,spring的aop就能很好的实现
缺点
- 一旦redis的数据失效,那么假如这时候有10w个请求打过来,由于redis没有缓存,那么按照缓存设计的逻辑,就会全部去查数据库
适用情况
- 如果一个系统是内部系统,天生没有太多的用户量,而某个接口需要非常耗时的查询,而数据变化又不会太频繁,就比较适用这种设计, 没有太多用户,就不会造成缓存失效的时候大量请求压到数据库的问题
2.2 解决redis缓存击穿问题
下面我们来看看有哪些设计可以解决缓存击穿的问题
下面的设计都解决了缓存击穿的问题
只是他们的设计各有利弊,我们需要在不同情况下来使用
2.2.1 主动刷新缓存设计
如果我们的数据是保存在redis缓存中,而redis缓存失效之后一定会查数据库
那么我们是否可以主动出击,在redis缓存失效之前,主动查数据库?
查询逻辑
- 先将所有可能查询到的数据存入redis
- 对redis中的数据库定时更新,保证redis永远都会有数据存在
- 来请求只查redis
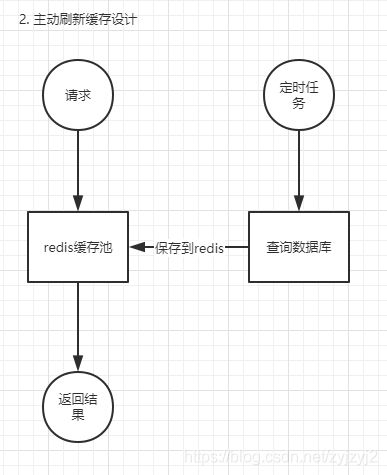
优点
- 用户的请求压力永远不会直接打到数据库上
- 查询效率很高
缺点
- 可能对redis内存消耗非常大,因为要提前将数据加载到缓存
- 增加了系统的复杂度,必须要有个非常可靠的定时任务操作,不然一旦定时任务失效,那么redis中的数据失效,对于用户来说就是服务不可用
- 数据的实时性非常依赖定时任务的执行频率,定时任务执行的频率高,实时性就强
- 如果刷新缓存的间隔设置很长,那么数据实时性就不够好,
- 如果刷新缓存的间隔很短,那么频繁的全量刷数据库到缓存对系统和数据库都是压力,也会让数据库和应用服务器的负载变得不够平稳
- 由于是只查询缓存,所以会对业务代码进行较大程度的改动,后期业务变化,可能会非常难以维护
适用情况
符合以下条件,那么我们可以使用这种设计
- 已有一套现成的高可靠分布式定时任务系统
- 查询的数据变化不大
- 用户的请求量非常大的情况下
2.2.2 使用redis的分布式锁
对 2.1.1 使用redis缓存 的设计进行一些改动
让我们对数据库的重复查询操作变为1次
既然我们使用了redis,那么可以利用redis实现的分布式锁setnx 来实现互斥的数据库操作
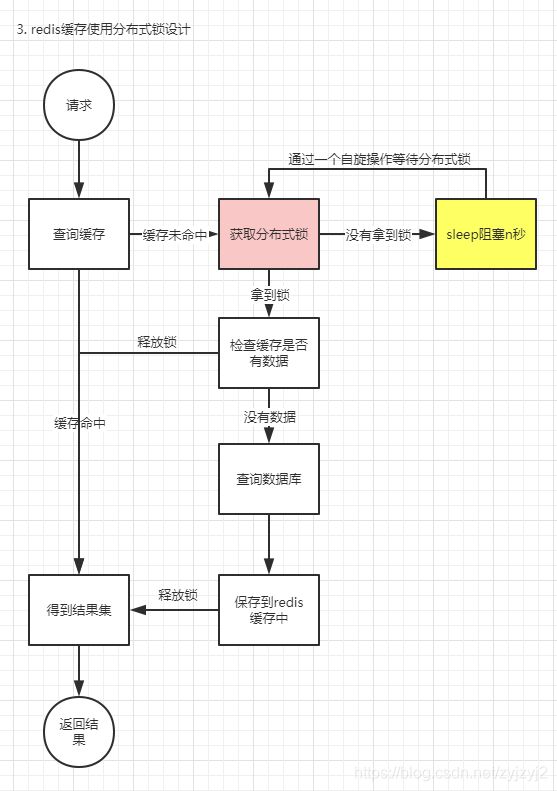
查询逻辑
- 如果缓存命中直接返回数据集
- 如果缓存没有,则尝试获取分布式锁(有超时设置)
- 如果没有拿到锁,则阻塞当前线程,n秒,之后再次尝试获取分布式锁(自旋,轮询,浪费CPU)
- 拿到锁之后检查数据是否已经被其他线程放到redis缓存中,如果redis缓存已有,直接返回redis中的数据,释放分布式锁
- 如果缓存没有被刷新,则查数据库
- 将数据库查询的结果保存到redis缓存中
- 返回查询结果
优点
- 数据的实时性较高
- 不需要其他外部系统依赖,利用了redis自己的特性,实现分布式锁
- 保证了同样的数据库查询同时只会查询1次,对数据库的压力较小
- 不会侵入业务代码,spring的aop就能很好的实现
缺点
- 由于阻塞等待分布式锁是个自旋阻塞操作,所以其实对应用服务器来说非常浪费cpu的分片时间
- 如果这时候大量请求打过来, 应用服务器反而会先扛不住,因为这里会有大量的线程在自旋占用CPU
- 如果用户的查询是由多个系统的结果构成,每个系统的查询依赖上一个系统查询的结果,各个查询是串行的,那么自旋的睡眠时间可能会成为拖慢请求的罪魁祸首,多个系统都这么设计都在自旋睡眠,明显效率很低
适用情况
这种方法也是网上给的最多的方法
如果要求保证数据库的压力特别小,同样的请求只能查询一次数据库,
而且服务器较多,足以将多个请求分散到不同服务器,不至于造成太多线程自旋,
那么可以使用这样的设计,但不推荐,因为这种自旋操作真的不是个好设计
2.2.3 普通加jvm的锁查询缓存
上面分布式锁自旋的方法,真的不优雅
这时候我们需要反问一下自己,每个请求,真的只能查询一次数据库吗?数据库的压力已经大到如此地步了吗?
如果不是
那么下面还有更加合适的设计
不再强求相同的查询只能查一次数据库
查询逻辑
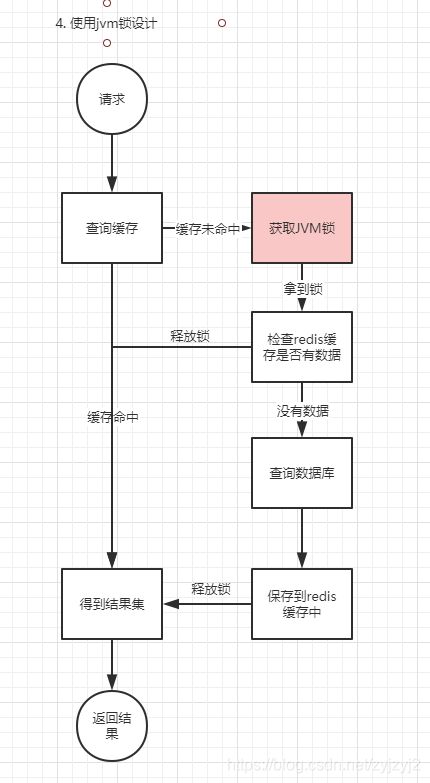
- 如果缓存命中直接返回数据集
- 如果缓存没有,则尝试JVM锁,其他线程阻塞
- 拿到锁之后,检查redis是否有数据,以免其他线程已经刷过缓存
- 如果redis已经有数据,直接返回,并释放锁,返回数据库结束
- 如果redis没有数据,则查询数据库,并保存到redis缓存中
- 返回数据,释放锁
设有s台服务器,用户请求数为n
那么同一时间参数相同的请求最多只会有s次查询打到数据库上,这里s这个常量
相当于原来对于数据库来说一个O(n)的操作时间下降到了O(s)
这里可以看出,查询数据库操作的耗时与n的增长无关,只与s有关
想象一下,我们有4台服务器,本来打到数据库上可能有10w个查询,但是因为我们使用了jvm的锁,每台服务器只会查询一次,总的数据库查询次数下降到了4次,是不是很高效?而且jvm提供的锁一定比redis分布式锁自旋轮询高效太多!
优点
- 数据的实时性较高
- 相对于使用redis分布式锁,大幅降低服务器资源的消耗,jvm的锁效率要高很多
- 对于数据库的消耗较小,是一个和服务器数量
s相关的耗时操作,与请求数量n无关(n可能会很大,十万,百万级别,而s可能最多两位数) - 如果mysql数据库版本较低,说不定还能利用上mysql数据库的缓存,如果是个不频繁更新的表,运气好的情况下
s-1次的查询可能都会命中mysql的缓存 - 实现的复杂度低
- 不会侵入业务代码,spring的aop就能很好的实现
缺点
- 对数据库查询虽然减小到了一个只与服务器数量相关的函数,但依然有冗余(其实也还好了)
适用情况
- 真的需要强求,所有服务器只查一次缓存吗?
- 如果能容忍较少次数的数据库重复查询
- 这种设计就用这种就已经能很好的解决缓存穿透的问题了,而且设计简单复杂度低
- 复杂度低意味着系统的稳定
2.2.4 多级缓存
如果宁非要强求,数据库同一时间不能收到重复的查询,那么也不是没有办法,往下看
查询逻辑
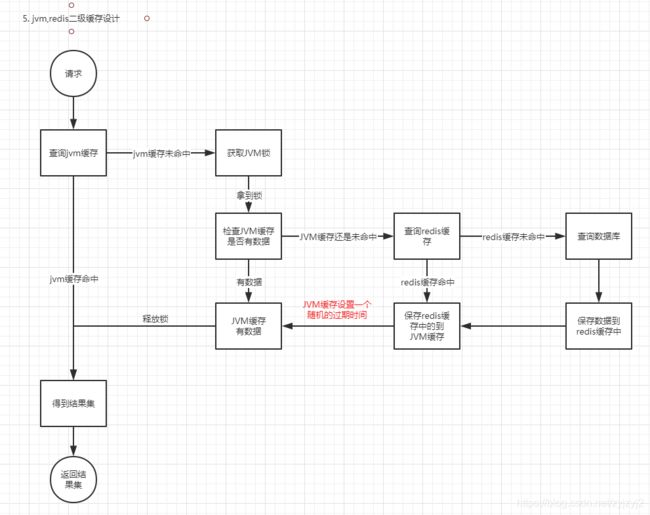
查询的逻辑看图吧,我懒得一步一步说了,一图胜钱言
二级缓存的关键在于:
- jvm的缓存时间是个随机值,比如 10秒~30秒
- 这种设计,服务器只会在jvm缓存失效,且redis缓存也失效的情况下才会查询数据库
- 而多个服务器的jvm缓存失效时间是随机值,所以很大程度上避免的同时失效去查库的情况
- 由于所有服务器jvm缓存同时失效redis缓存也失效的可能性极低,所以数据库上重复的查询会很少
- (不一定是jvm缓存和jvm的锁啊,python,go同理)
设服务器的台数为s
- 如何让O(s)的问题其变为O(1)呢?其实也是有办法的,就是多级缓存
- 就是让每台服务器上加一个jvm的缓存在redis之前
- 这个jvm的缓存时间需要设置一个随机值,比如 缓存时间为 5s-10s,这样可以很大程度避免在redis失效的时候,每台服务器都需要去做更新redis缓存的操作,因为每个服务器的jvm缓存失效时间是不一样的
优点
- 数据的实时性较高 (设置合适的jvm缓存过期时间和redis缓存过期时间)
- 几乎没有冗余的数据库查询
- 绝大多数查询是使用的jvm缓存,效率极高
- 对cpu的占用很低
- 不会侵入业务代码,spring的aop就能很好的实现
缺点
- 如果查询的参数离散度较高,其实会很浪费业务服务器的内存空间(但是可以通过减少jvm缓存的时间来优化一点)
- 设计稍微有点复杂,需要有经验的码畜来实现
适用情况
几乎所有情况,强力推荐,我也是这么做的
2.2.5 其他注意点
以上的这些设计,只是在正常的高并发情况下
如果你的服务器遭遇到了DOS攻击,那什么缓存策略都没用,因为迟早会把你线程吃满,然后服务器不可用
这时候你只能在网关或者nginx做一些对ip限流的措施,设置阈值,防止恶意调用接口