DF-GAN: A Simple and Effective Baseline for Text-to-Image Synthesis论文解读
题目:DF-GAN:一种简单有效的文本-图像合成基线
时间:2022
CVPR
Abstract
从文字描述中合成高质量的逼真图像是一项具有挑战性的任务。现有的文本-图像生成对抗网络通常采用堆叠架构作为主干,但仍存在三个缺陷。首先,分层结构引入了不同图像尺度的生成器之间的纠缠。其次,现有的研究倾向于在对抗学习中应用和固定额外的网络来实现文本图像语义一致性,这限制了这些网络的监督能力。第三,以往广泛采用的基于注意的跨模态文本图像融合算法由于计算成本的原因,在一些特殊的图像尺度上受到限制。为此,我们提出了一种更简单但更有效的深度融合生成对抗网络(DF-GAN)。具体而言,我们提出:(i)一种新颖的单阶段文本-图像骨干,可以直接合成高分辨率图像,而不存在不同生成器之间的纠缠;(ii)一种新颖的由匹配感知梯度惩罚和单向输出组成的目标感知鉴别器,可以在不引入额外网络的情况下增强文本-图像语义一致性;(iii)一种新颖的深度文本-图像融合块,深化融合过程,使文本和视觉特征完全融合。与目前最先进的方法相比,我们提出的DFGAN更简单,更有效地合成真实和文本匹配的图像,并在广泛使用的数据集上获得更好的性能。DFGAN代码
Introduction
- 在过去几年中,生成对抗网络(GANs)在各种应用中取得了巨大的成功。其中,文本-图像合成是GANs最重要的应用之一。它旨在从给定的自然语言描述中生成真实和文本一致的图像。由于其实用价值,文本-图像合成近年来成为一个活跃的研究领域。
- 文本到图像合成的两个主要挑战是生成图像的真实性,以及给定文本和生成图像之间的语义一致性。由于GAN模型的不稳定性,最近的模型大多采用堆叠架构作为骨干来生成高分辨率图像。他们利用跨模态注意融合文本和图像特征,然后引入DAMSM网络、循环一致性或暹罗网,通过额外的网络来保证文本图像语义一致性。
- 虽然前人的研究成果令人印象深刻,但仍存在三个问题:首先,堆叠架构引入了不同生成器之间的纠缠,这使得最终细化的图像看起来像模糊形状和一些细节的简单组合。如图1(a)所示,最终的细化图像有着由G0合成的模糊形状,由G1合成的粗属性(如eye和beak) 以及由G2添加的细粒度细节(例如,眼睛反射)。最终合成的图像看起来像是不同图像尺度的视觉特征的简单组合。其次,现有研究通常在对抗性训练中固定额外的网络[33,50],使得这些网络很容易被生成器愚弄而合成对抗性特征[30,52],从而削弱了它们对语义一致性的监督能力。第三,跨模态注意[50]不能充分利用文本信息。由于计算成本高,它们只能在64×64和128×128图像特征上应用两次。它限制了文本图像融合过程的有效性,使模型难以扩展到更高分辨率的图像合成。

- 为了解决上述问题,我们提出了一种新的文本-图像生成方法,称为深度融合生成对抗网络(DF-GAN)。对于第一个问题,我们将堆叠的主干替换为一级主干。它由铰链损失和残差网络组成,可以稳定GAN训练过程,直接合成高分辨率图像。由于一级主干网中只有一个生成器,避免了不同生成器之间的纠缠。第二,设计了一个由匹配感知梯度惩罚(match - aware Gradient Penalty, MA-GP)和单向输出(One-Way Output)组成的目标感知鉴别器,以提高文本图像的语义一致性。MA-GP是鉴别器上的一种正则化策略。它追求目标数据(真实和文本匹配图像)上鉴别器的梯度为零。因此,MA-GP在真实和匹配的数据点处构建平滑的损失面,从而进一步促进生成器合成与文本匹配的图像。此外,考虑到之前的双向输出减慢了MA-GP下生成器的收敛过程,我们将其替换为更有效的单向输出。在第三个问题中,我们提出了深度文本-图像融合块(Deep text-image Fusion Block, DFBlock),以更有效地将文本信息融合到图像特征中。DFBlock由几个仿射变换组成。仿射变换是一个轻量级模块,它通过通道缩放和移动操作来操作可视特征图。在所有图像尺度上叠加多个DFBlock加深了文本-图像融合过程,使文本和视觉特征完全融合。
- 总体而言,我们的贡献可以总结如下:我们提出了一种新颖的单阶段文本到图像主干,可以直接合成高分辨率图像,而不会在不同生成器之间产生纠缠。我们提出了一种新的目标感知鉴别器,由匹配感知梯度惩罚(MA-GP)和单向输出组成。在不引入额外网络的情况下,显著提高了文本图像语义一致性。本文提出了一种新颖的**深度文本图像融合块 **(DFBlock),能够更有效、更深入地融合文本和视觉特征。在两个具有挑战性的数据集上进行的大量定性和定量实验表明,所提出的DF-GAN优于现有的最先进的文本到图像模型。
Related Work
- 生成对抗网络(GANs)是一个有吸引力的框架,可以通过解决生成器和鉴别器之间的最小-最大优化问题来模拟复杂的现实世界分布。例如,Reed等人首先应用条件GAN从文本描述中生成貌似真实的图像。StackGAN通过堆叠多个生成器和鉴别器生成高分辨率图像,并通过连接文本向量和输入噪声向生成器提供文本信息。接下来,AttnGAN引入了跨模态注意机制,帮助生成器合成更多细节的图像。MirrorGAN从生成的图像中重新生成文本描述,以实现文本图像语义一致性。SD-GAN采用暹罗结构从文本中提取语义共性以保证图像生成的一致性。DM-GAN引入了内存网络,用于在堆叠架构下初始图像不能很好地生成时细化模糊图像内容。近年来,一些基于大型变压器的文本到图像方法在复杂图像合成方面表现出优异的性能。他们对图像进行标记,并将图像标记和单词标记通过单向变压器进行自回归训练。
- 我们的DF-GAN与以前的方法有很大不同。首先,它通过一级主干网直接生成高分辨率图像。其次,采用目标感知鉴别器,在不引入额外网络的情况下提高文本-图像语义一致性;第三,它通过一系列的dfblock更深入有效地融合文本和图像特征。与以前的模型相比,我们的DF-GAN在合成真实和文本匹配图像方面简单得多,但更有效。
The Proposed DF-GAN
- 在本文中,我们提出了一个简单的文本到图像合成模型,称为深度融合GAN (DF-GAN)。为了合成更真实和文本匹配的图像,我们提出:(i)一种新型的单阶段文本-图像骨干,可以直接合成高分辨率图像,而不存在视觉特征纠缠。(ii)一种由匹配感知梯度惩罚(MA-GP)和单项输出组成的新型目标感知鉴别器,在不引入额外网络的情况下提高了文本图像语义一致性。(iii)新颖的深度文本图像融合块(DFBlock),更充分地融合文本和视觉特征。
Model Overview
- DF-GAN由一个生成器、一个鉴别器和一个预先训练好的文本编码器组成,如图2所示。生成器有两个输入,一个是由文本编码器编码的句子向量,另一个是从高斯分布采样的噪声向量,以保证生成图像的多样性。首先将噪声矢量送入全连通层并对其进行重塑。然后我们应用一系列upblock对图像特征进行上采样。UPBlock由上采样层、残差块和DFBlocks组成,用于在图像生成过程中融合文本和图像特征。最后,卷积层将图像特征转换为图像。鉴别器通过一系列downblock将图像转换为图像特征。然后将句子向量复制并与图像特征拼接。通过预测对抗性损失来评估输入的视觉真实感和语义一致性。

- 鉴别器通过将生成的图像与真实样本进行区分,使生成器能够合成质量更高、文本图像语义一致性更好的图像。文本编码器是一个双向长短期记忆(LSTM)[41],它从文本描述中提取语义向量。我们直接使用AttnGAN[50]提供的预训练模型。
一级文本到图像主干
- 由于GAN模型的不稳定性,以往的文本到图像GAN通常采用堆叠架构,从低分辨率图像生成高分辨率图像。然而,堆叠架构引入了不同生成器之间的纠缠,它使最终的细化图像看起来像模糊形状和一些细节的简单组合。受最近关于无条件图像生成的研究的启发,我们提出了一种单阶段文本到图像的主干,可以通过一对生成器和判别器直接合成高分辨率图像。**我们使用铰链损失来稳定对抗训练过程。由于一级主干网中只有一个生成器,避免了不同生成器间的纠缠。由于我们的单阶段框架中的单个生成器需要直接从噪声向量合成高分辨率图像,因此它必须包含比以前的堆叠架构中的生成器更多的层。**为了有效地训练这些层,我们引入残差网络来稳定更深层网络的训练。我们带有铰链损失的单层方法公式如下:

其中z为高斯分布采样的噪声向量;e是句子向量;Pg Pr Pmis分别表示合成数据分布、真实数据分布和不匹配数据分布。
Target-Aware Discriminator
在本节中,我们详细介绍了所提出的目标感知鉴别器,它由匹配感知梯度惩罚(MA-GP)和单向输出组成。目标感知鉴别器促进生成器合成更真实和文本图像语义一致的图像。
Matching-Aware Gradient Penalty
- 匹配感知零中心梯度惩罚(MA-GP)是我们新设计的增强文本-图像语义一致性的策略。在本小节中,我们首先从一个新颖而清晰的角度展示无条件梯度惩罚,然后将其扩展到我们的MA-GP用于文本到图像生成任务。
- 如图3(a)所示,在无条件图像生成中,目标数据(真实图像)对应一个较低的鉴别器损失。相应的,合成图像对应一个高鉴别器损失。铰链损失限制鉴别器损失范围在-1和1之间。对真实数据的梯度惩罚将降低真实数据点及其附近的梯度。然后对真实数据点周围的损失函数曲面进行平滑处理,有利于合成数据点收敛到真实数据点。

- 基于上述分析,我们发现目标数据上的梯度惩罚构造了一个更好的损失景观,以帮助生成器收敛。通过将视图转化为文本到图像的生成。如图3(b)所示,在文本到图像的生成中,判别器观察到四种输入:具有匹配文本的合成图像(fake, match),具有不匹配文本的合成图像(fake, mismatch),具有匹配文本的真实图像(real, match),具有不匹配文本的真实图像(real, mismatch)。为了保证文本-视觉语义一致性,我们倾向于对文本匹配的真实数据(文本-图像合成的目标)施加梯度惩罚,有利于合成数据点收敛到真实数据点(生成器收敛)。因此,在MA-GP中,梯度惩罚应应用于具有匹配文本的真实图像。我们用MA-GP建立的模型的整体公式如下:
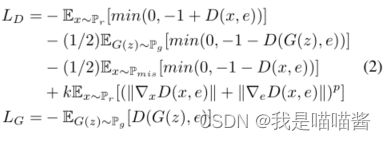
其中k和p是两个超参数,用来平衡梯度惩罚的有效性。 - 通过使用MA-GP损失作为鉴别器上的正则化,我们的模型可以更好地收敛到文本匹配的真实数据,从而合成更多的文本匹配图像。此外,由于鉴别器是在我们的网络中联合训练的,它阻止了生成器合成固定额外网络的对抗特征。此外,由于MA-GP没有加入任何额外的网络来保证文本图像的一致性,并且梯度已经通过反向传播过程计算出来,因此我们提出的MA-GP引入的唯一计算方法是梯度和,它比额外的网络更易于计算。
One-Way Output
- 在以往的文本到图像的GANs中,判别器提取的图像特征通常有两种使用方式(图4(a)):一种是判断图像是真还是假,另一种是将图像特征与句子向量进行拼接,以评估文本-图像语义一致性。相应的,在这些模型中计算了无条件损失和条件损失。

- 然而,研究表明,双向输出削弱了MA-GP的有效性,并降低了生成器的收敛速度。具体如图3(b)所示,条件损失给出一个梯度α,指向反向传播后的真实和匹配输入,而无条件损失给出一个梯度β,只指向真实图像。然而,最终梯度的方向只是简单地将γ和β相加,并不像我们预期的那样指向真实和匹配的数据点。由于生成器的目标是合成真实图像和文本匹配图像,最终的梯度偏差不能很好地实现文本图像语义一致性,降低了生成器的收敛速度。因此,我们提出了文本到图像合成的单向输出。如图4(b)所示,我们的鉴别器将图像特征和句子向量连接起来,然后通过两个卷积层只输出一个对抗损失。通过单向输出,我们能够使单梯度γ直接指向目标数据点(真实和匹配),优化和加速生成器的收敛。通过结合MA-GP和单向输出,我们的目标感知鉴别器可以指导生成器合成更真实和文本匹配的图像。
Efficient Text-Image Fusion
- 为了有效地融合文本和图像特征,我们提出了一种新颖的深度文本-图像融合块(DFBlock)。与以往的文本图像融合模块相比,我们的DFBlock深化了文本图像融合过程,实现了完整的文本图像融合。

- 如图2所示,我们的DF-GAN生成器由7个upblock组成。一个UPBlock包含两个文本图像融合块。为了充分利用融合中的文本信息,我们提出了深度文本-图像融合块(DFBlock),它将多个仿射变换和ReLU层堆叠在融合块中。对于仿射变换,如图5©所示,我们采用两个mlp(多层感知器)分别从句子向量e中预测语言条件下的通道尺度参数γ和移动参数θ:
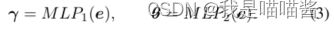
对于给定的输入特征映射X∈RB×C×H×W,我们首先以缩放参数γ对X进行通道级缩放操作,然后以移动参数θ对X进行通道级移动操作。这个过程可以表示为:

其中AFF为仿射变换;e是句子向量;γi和θi是可视特征图第i通道的缩放参数和移动参数。仿射层扩展了生成器的条件表示空间。然而,仿射变换是每个通道的线性变换。这限制了文本图像融合过程的有效性。因此,我们在两个仿射层之间添加了一个ReLU层,将非线性引入融合过程。与只有一个仿射层相比,它扩大了条件表示空间。较大的表示空间有助于生成器根据文本描述将不同的图像映射到不同的表示。 - 我们的DFBlock部分是受到条件批处理归一化(CBN)和自适应实例归一化(AdaIN)的启发,它们包含仿射转换。然而,CBN和AdaIN都采用了归一化层,将特征映射转换为正态分布。它产生了与仿射变换相反的效果,预计会增加不同样本之间的距离。因此,它对条件生成过程没有帮助。为此,我们去掉了归一化过程。此外,我们的DFBlock加深了文本图像融合过程。我们堆叠多个仿射层,并在其中添加一个ReLU层。它促进了视觉特征的多样性,扩大了表现空间根据不同的文字描述来表示不同的视觉特征。
- 随着融合过程的深入,DFBlock为文本到图像的生成带来了两个主要的好处:第一,它使生成器在融合文本和图像特征时更充分地利用文本信息。第二,深化融合过程,扩大融合模块的表示空间,有利于从不同的文本描述中生成语义一致的图像。
- 此外,与之前的文本到图像GANs相比,本文提出的DFBlock使我们的模型在融合文本和图像特征时不再考虑图像尺度的限制。这是因为现有的文本到图像GANs普遍采用跨模态注意机制,随着图像大小的增加,计算成本快速增长。
Experiments
- 在本节中,我们首先介绍了我们实验中使用的数据集、训练细节和评估指标,然后定量和定性地评估DF-GAN及其变体。
- 数据集。我们遵循之前的工作[,并在两个具有挑战性的数据集上评估所提出的模型,即CUB bird和COCO。CUB数据集包含200种鸟类的11788张图像。每个鸟的图像有十个语言描述。COCO数据集包含80k用于训练的图像和40k用于测试的图像。这个数据集中的每张图像都有五个语言描述。
- 训练细节。我们使用Adam优化我们的网络,β1=0.0, β2=0.9。根据双时间尺度更新规则,生成器的学习率设置为0.0001,鉴别器的学习率设置为0.0004。
- 评估的细节。根据之前的工作,我们选择Inception Score (IS)和Fréchet Inception Distance (FID)来评估我们网络的性能。具体来说,IS计算条件分布和边际分布之间的Kullback-Leibler (KL)散度。IS越高,生成的图像质量越高,每张图像都明确属于特定的类别。FID在预训练的Inception v3网络的特征空间中计算合成图像分布与真实图像之间的Fréchet距离。与IS相反,更真实的图像具有较低的FID。为了计算IS和FID,每个模型从测试数据集中随机选择的文本描述中生成30,000张图像(256×256分辨率)。
- 如近期文献所述,IS不能很好地评价COCO数据集上的图像质量,这在我们提出的方法中也存在。此外,我们发现一些基于gan的模型在COCO数据集上的IS显著高于基于transformer的大型文本到图像模型,但合成图像的视觉质量明显低于基于transformer的模型。因此,我们没有在COCO数据集上比较IS。相比之下,FID更健壮,并将人类定性评估对准COCO数据集。此外,我们评估了参数的数量(NoP),以比较模型的大小与现有的方法。
Quantitative Evaluation
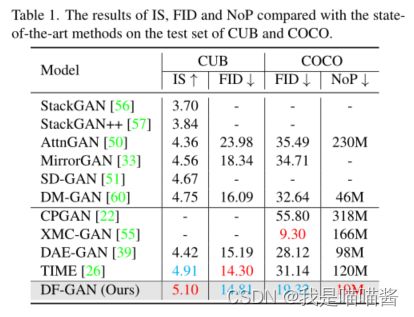
- 我们将所提出的方法与几种先进的方法进行了比较,包括StackGAN, StackGAN++, AttnGAN, MirrorGAN, SD-GAN和DM-GAN,它们通过使用堆叠结构在文本到图像合成方面取得了显著的成功。我们还比较了最近的模型。应该指出的是,最近的模型总是使用额外的知识或监督。例如CPGAN使用额外预训练的YOLO-V3, XMC-GAN使用额外预训练的VGG-19和Bert, DAEGAN使用额外的NLTK POS标记并为不同的数据集手动设计规则,TIME使用额外的二维位置编码。
- 如表1所示,与其他领先模型相比,我们的DF-GAN的参数数量(Number of Parameters, NoP)显著减少,但仍具有竞争力。与使用跨模态注意来融合文本和图像特征的AttnGAN相比,我们的DF-GAN在CUB数据集上将IS度量从4.36提高到5.10,并将FID度量从23.98降低到14.81。在COCO数据集上,我们的DF-GAN将FID从35.49降低到19.32。与MirrorGAN和采用循环一致性和暹罗网络来保证文本图像语义的一致性的SD-GAN相比,在CUB数据集上,我们的DF-GAN分别将IS从4.56和4.67提高到5.10。与引入记忆网络对模糊图像内容进行细化的DM-GAN模型相比,我们的模型在CUB上的IS从4.75提高到5.10,FID从16.09降低到14.81,在COCO上的FID从32.64降低到19.32。此外,与引入额外知识的最新模型相比,我们的DF-GAN仍然具有竞争力的性能。定量比较证明,我们的模型更简单,更有效。
定性评价
- 我们还比较了AttnGAN, DM-GAN和提出的DF-GAN合成的可视化结果。
- 可以看到,在图6中,AttnGAN和DM-GAN合成的图像看起来像是模糊形状和一些视觉细节(第1、3、5、7、8列)的简单组合。如第5、7、8列所示,AttnGAN和DM-GAN合成的鸟类形状错误。此外,DF-GAN合成的图像具有更好的物体形状和逼真的细粒度细节(例如,第1、3、7和8列)。此外,在我们的DF-GAN结果中,鸟的姿态也更加自然(例如,第7列和第8列)。将文本图像语义一致性与其他模型进行比较,发现DF-GAN还可以捕获文本描述中更细粒度的细节。例如,如图6中第1、2、6列所示,其他模型不能很好地合成文中描述的“手持滑雪杆”、“火车轨道”和“眼睛边的黑色条带”,而本文提出的DF-GAN可以更正确地合成它们。

消融实验
在本节中,我们对CUB数据集的测试集进行了消融研究,以验证所提议的DF-GAN中每个组件的有效性。包括单级文本-图像骨干(OSB)、匹配感知梯度惩罚(MA-GP)、单向输出(OW-O)、深度文本-图像融合块(DFBlock)。我们还将我们的目标感知鉴别器与深度注意多模态相似模型(DAMSM)进行了比较,DAMSM是目前模型中广泛使用的额外网络。我们首先评估OS-B, MA-GP和OW-O的有效性。我们进行了一项用户研究来评估文本-图像语义一致性(SC),我们要求10名用户对100张随机合成的带有文本描述的图像进行评分。分数从1(最差)到5(最好)。在CUB数据集上的结果如表2所示。

- 基线。我们的基线采用堆叠框架和双向输出,与StackGAN具有相同的对抗损失。在基线中,句子向量被天真地连接到输入噪声和中间特征图。
- 一级主干网的效果。我们提出的OS-B将IS从3.96提高到4.11,并将FID从43.45降低到43.45。结果表明,我们的一级骨干比堆叠架构更有效。
- MA-GP的作用。加入MA-GP后,模型的IS进一步提高到4.46,SC提高到3.55,FID显著降低到32.52。实验结果表明,本文提出的MA-GP算法能够提高生成图像的真实感和语义一致性。
- 单向输出的效果。拟议的OW-O还将IS从4.46提高到4.57,SC从3.55提高到4.61,FID从32.52降低到23.16。它也证明了在文本到图像生成任务中,单向输出比双向输出更有效。
- 目标感知鉴别器的效果。与DAMSM相比,我们提出的由MA-GP和OW-O组成的目标感知鉴别器将IS从4.28提高到4.57,SC从1.79提高到4.61,FID从36.72降低到23.16。实验结果表明,我们的目标感知鉴别器优于现有的网络。
- DFBlock的效果。我们将我们的DFBlock与CBN, AdaIN和AFFBlock进行比较。AFFBlock使用一个仿射转换层来融合文本和图像特征。MA-GP GAN模型采用了单级文本到图像主干,匹配感知梯度惩罚和单向输出。从表3的结果中,我们发现,与其他融合方法相比,拼接不能有效地融合文本和图像特征。对比CBN、AdaIN和AFFBlock,可以证明在Fusion Block中,归一化并不是必须的,去除归一化可以稍微提高结果。通过对DFBlock和AFFBlock的比较,验证了深化文本图像融合过程的有效性。总之,对比结果证明了我们提出的DFBlock的有效性。

Limitations
尽管DF-GAN在文本-图像合成方面表现出优势,但在未来的研究中必须考虑到一些局限性。首先,我们的模型只引入了句子级的文本信息,这限制了细粒度视觉特征合成的能力。其次,引入预训练的大型语言模型[6,34]来提供额外的知识,可以进一步提高性能。我们将在今后的工作中努力解决这些限制。
Conclusion and Future Work
在本文中,我们提出了一种新的用于文本-图像生成任务的DF-GAN。我们提出了一种单阶段文本到图像骨干,可以直接合成高分辨率图像,而不需要在不同的生成器之间产生纠缠。我们还提出了一种新的由匹配感知梯度惩罚(MAGP)和单向输出组成的目标感知鉴别器。它可以在不引入额外网络的情况下进一步增强文本图像的语义一致性。此外,我们还介绍了一种新颖的深度文本-图像融合块(Deep text-image Fusion Block, DFBlock),能够更有效、更深入地充分融合文本和图像特征。大量的实验结果表明,我们提出的DF-GAN在CUB数据集和更具挑战性的COCO数据集上显著优于当前最先进的模型。