自定义卷积实现卷积的重参数【手撕代码】
在我的上篇文章中主要对RepVGG进行了解析【RepVGG网络中重参化网络结构解读】,里面详细的对论文中的代码进行了解析,展示了RepVGG在重参数时是如何将训练分支进行合并的,总的一句话就是在推理阶段,会将1x1以及identity分支以padding的方法变成3x3的卷积后再与主干中的3x3卷积进行合并。
而这篇文章的目的仿照RepVGG如何自定义一个含有分支的卷积,并采用重参数技术进行合并推理。
目录
卷积块的定义
重参数化
BN、identity以及卷积的融合
1x1变成3x3
完整代码:
卷积块的定义
下面的代码是先定义一个基础的卷积块CB(一个conv和一个BN层的结合)
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0):
resluts = nn.Sequential()
resluts.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
resluts.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return resluts下面的代码就是我们的定义的含有分支的卷积块。
参数说明:
in_channels:输入通道数
out_channels:输出通道数
stride:卷积步长
groups:分组卷积组数
padding_mode:padding模式,以0补pad
deploy:在重参数的时候将会设置为True将网络分支合并
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, groups=1, padding_mode='zeros', deploy=False):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.deploy = deploy
self.identity = nn.Identity()
self.relu = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2d(self.in_channels, self.out_channels, 3, stride=1, padding=1, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=self.in_channels) if self.in_channels == self.out_channels and stride == 1 else None
self.conv3_3 = conv_bn(self.in_channels, self.out_channels, 3, stride, padding=1)
self.conv1_1 = conv_bn(self.in_channels, self.out_channels, 1, 1)
print('RepConv Block, identity = ', self.rbr_identity)
def forward(self, x):
if hasattr(self, 'rbr_reparam'):
return self.relu(self.identity(self.rbr_reparam(x)))
out1 = self.conv3_3(x)
out2 = self.conv1_1(x)
out3 = self.identity(x)
return self.relu(out1 + out2 + out3)然后我们可以直接看forward函数,【这里先暂时不看if hasattr(self,'rbr_reparam')这一段】,可以看到产生三个out,进行相加后再经过relu激活函数,打印的网络以及网络结构如下,能很清楚的看到卷积块的分支,分别是identity、3x3和1x1卷积。

ConvBlock(
(identity): Identity()
(relu): ReLU()
(rbr_identity): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3_3): Sequential(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(conv1_1): Sequential(
(conv): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
按照RepVGG的思想,在训练过程中网络基本单元如上,推理阶段将会合并分支,下面就看看怎么实现的。
重参数化
下面这些代码是定义在上面的类ConvBlock中的。
get_equivalent_kernel_bias这个函数获取3x3,1x1以及identity中的权值和bias,这个内部实现的核心是fuse_bn_tensor这个函数。
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv3_3)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv1_1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasidBN、identity以及卷积的融合
fuse_bn_tensor是获取权值、方差、均值等,将卷积和BN层进行融合。
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight # 卷积的权值
running_mean = branch.bn.running_mean # bn的均值
running_var = branch.bn.running_var # bn的方差
gamma = branch.bn.weight # bn的权值
beta = branch.bn.bias # bn的bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) # 创建一个全零32*32*3*3的矩阵用来记录权值
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 获得一个中间值为1,周边值为0的新卷积核
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std =(running_var + eps).sqrt()
t = (gamma/std).reshape(-1, 1, 1, 1)
return kernel * t, beta -running_mean * gamma / std当第一次遍历的时候branch为Sequential时,获取Conv层,以及BN层的参数(如果你这里没有BN层可以考虑把这部分代码删去,只获取Conv)
Sequential(
(conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
其中在fuse_bn_tensor这里面有个核心的代码是下面这一行,这个是在identity这个分支中,会创建一个全0的矩阵,矩阵大小为in_channels*input_dim*3*3。
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) 然后在上面的kernel_value中每个通道的中间那个元素位置为1。
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 获得一个中间值为1,周边值为0的新卷积核
1x1变成3x3
下面的代码是将1x1的卷积补成3x3卷积
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return F.pad(kernel1x1, [1, 1, 1, 1]) # 在1x1四周补padding最后是看switch_to_deploy函数,我们前面通过get_equivalent_kernel_bias获得kernel和bias,创建重参数化卷积rbr_reparam,大小为3x3.
然后把之前融合的卷积权值和bias传入给新键的rbr_reparam中,在将deploy设置为True就得到了我们想要的卷积了。
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(self.conv3_3.conv.in_channels, self.conv3_3.conv.out_channels,
kernel_size=self.conv3_3.conv.kernel_size,
stride=self.conv3_3.conv.stride,
padding=self.conv3_3.conv.padding,
dilation=self.conv3_3.conv.dilation,
groups=self.conv3_3.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for param in self.parameters():
param.detach_()
self.__delattr__('conv3_3')
self.__delattr__('conv1_1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True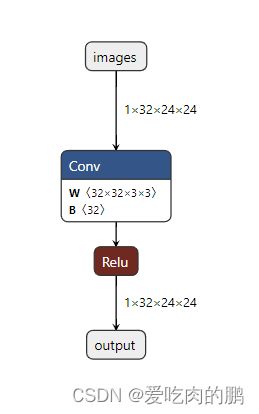
完整代码:
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0):
resluts = nn.Sequential()
resluts.add_module('conv', nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
resluts.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return resluts
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, groups=1, padding_mode='zeros', deploy=False):
super(ConvBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.deploy = deploy
self.identity = nn.Identity()
self.relu = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2d(self.in_channels, self.out_channels, 3, stride=1, padding=1, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=self.in_channels) if self.in_channels == self.out_channels and stride == 1 else None
self.conv3_3 = conv_bn(self.in_channels, self.out_channels, 3, stride, padding=1)
self.conv1_1 = conv_bn(self.in_channels, self.out_channels, 1, 1)
print('RepConv Block, identity = ', self.rbr_identity)
def forward(self, x):
if hasattr(self, 'rbr_reparam'):
return self.relu(self.identity(self.rbr_reparam(x)))
out1 = self.conv3_3(x)
out2 = self.conv1_1(x)
out3 = self.identity(x)
return self.relu(out1 + out2 + out3)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv3_3)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv1_1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return F.pad(kernel1x1, [1, 1, 1, 1]) # 在1x1四周补padding
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight # 卷积的权值
running_mean = branch.bn.running_mean # bn的均值 没有BN层可以考虑删除改部分
running_var = branch.bn.running_var # bn的方差
gamma = branch.bn.weight # bn的权值
beta = branch.bn.bias # bn的bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d) # identity
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32) # 创建一个全零32*32*3*3的矩阵用来记录权值
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1 # 获得一个中间值为1,周边值为0的新卷积核
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std =(running_var + eps).sqrt()
t = (gamma/std).reshape(-1, 1, 1, 1)
return kernel * t, beta -running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(self.conv3_3.conv.in_channels, self.conv3_3.conv.out_channels,
kernel_size=self.conv3_3.conv.kernel_size,
stride=self.conv3_3.conv.stride,
padding=self.conv3_3.conv.padding,
dilation=self.conv3_3.conv.dilation,
groups=self.conv3_3.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for param in self.parameters():
param.detach_()
self.__delattr__('conv3_3')
self.__delattr__('conv1_1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
def repconv(model:nn.Module, save_path=None, do_copy=True):
if do_copy:
model =copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'switch_to_deploy'):
module.switch_to_deploy()
if save_path is not None:
torch.save(model.state_dict(), save_path)
return model
model = ConvBlock(32, 32)
print(model)
x = torch.randn(1, 32, 24, 24)
torch.onnx.export(model, x, "Conv.onnx", verbose=True, input_names=['images'], output_names=['output'],
opset_version=12)
rep_model = repconv(model)
torch.onnx.export(rep_model,x,'rep_model.onnx', verbose=True,input_names=['images'], output_names=['output'],
opset_version=12)
有些细节后面再慢慢补充,最近阳了有些不太舒服~