推荐排序模型2—— wide&Deep及python(DeepCTR)实现
wide&Deep模型重点指出了Memorization和Generalization的概念,这个是从人类的认知学习过程中演化来的。人类的大脑很复杂,它可以记忆(memorize)下每天发生的事情(麻雀可以飞,鸽子可以飞)然后泛化(generalize)这些知识到之前没有看到过的东西(有翅膀的动物都能飞)。但是泛化的规则有时候不是特别的准,有时候会出错(有翅膀的动物都能飞吗)。那怎么办那,没关系,记忆(memorization)可以修正泛化的规则(generalized rules),叫做特例(企鹅有翅膀,但是不能飞)。wide&Deep就是以这个思想出发形成的。
目录
- 1,wide&deep的概念
- 2, wide&deep结构
- 3,python(deepCTR)实现
1,wide&deep的概念
Wide也是一种特殊的神经网络,他的输入直接和输出相连。属于广义线性模型的范畴。Deep就是指Deep Neural Network,这个很好理解。
Wide Linear Model用于memorization;Deep Neural Network用于generalization。

Memorization:
之前大规模稀疏输入的处理是:通过线性模型 + 特征交叉。所带来的Memorization以及记忆能力非常有效和可解释。但是Generalization(泛化能力)需要更多的人工特征工程。
Generalization:
相比之下,DNN几乎不需要特征工程。通过对低纬度的dense embedding进行组合可以学习到更深层次的隐藏特征。但是,缺点是有点over-generalize(过度泛化)。推荐系统中表现为:会给用户推荐不是那么相关的物品,尤其是user-item矩阵比较稀疏并且是high-rank(高秩矩阵)
两者区别:
Memorization趋向于更加保守,推荐用户之前有过行为的items。相比之下,generalization更加趋向于提高推荐系统的多样性(diversity)。
Wide & Deep:
Wide & Deep包括两部分:线性模型 + DNN部分。结合上面两者的优点,平衡memorization和generalization。
2, wide&deep结构
wide&deep模型是一种组合思想。如上图所示,所谓Wide&Deep就是整个模型结构由wide部分和deep部分共同组成,图中左边是wide模型,一个逻辑回归,右边是deep模型,认为大概3层左右的DNN即可。
假设输入的都是类别特征,deep模型的输入是用one-hot表示的Sparse Features。比如,对手机型号这个特征而言,市面上可能存在数千个手机型号,但是每个用户只对应一个手机型号,那么这个稀疏向量有几千个维度,只有一个位置为1,其余位置为0。将每个特征以embedding表示,embedding是一个低维稠密向量。将高维稀疏特征,映射到对应的embedding上去,将所有特征的embedding水平拼接起来,生成图中的Dense Embeddings,最后通过若干层神经网络得到输出。将wide和deep部分组合起来,就是图中间的wide&deep模型。
公式化表达如下所示:
![]()
其中,b表示偏置bias, a ( l ) a^{(l)} a(l) 表示deep模型最后一层输出,x表示原始的输入特征,注意还有一个 ϕ ( x ) \phi(x) ϕ(x),这个是原始特征的特征交叉,如下所示:
ϕ k ( x ) = ∏ i = 1 d d i c k i c k i ∈ { 0 , 1 } \phi_k(x) = \prod_{i=1}^dd_i^{c_{ki}} \ \ \ \ \ \ c_{ki}\in \{0,1\} ϕk(x)=i=1∏ddicki cki∈{0,1}
k表示第k个组合特征。i表示输入X的第i维特征。 C k i C_{ki} Cki表示这个第i维度特征是否要参与第k个组合特征的构造。d表示输入X的维度。那么到底有哪些维度特征要参与构造组合特征呢?这个是你之前自己定好的(人工部分),在公式中没有体现。公式整的复杂了些,但是仍然是一种特征交叉。
所以,原文中提到wide&deep仍然需要做特征工程实现特征交叉,但是相比于原生的逻辑回归,只需要做少量的特征交叉,大大减少了特征工程的工作量,并且效果优于逻辑回归。原文对wide和deep模型的含义做了介绍,wide模型的特征交叉部分主要负责记忆功能,记住样本中出现过的特征交叉。deep部分有泛化功能,学习特征的embedding,泛化到那些未曾出现过的特征交叉。
Deep部分使用的特征:连续特征,Embedding后的离散特征,Item特征 Wide部分使用的特征:Cross Product
Transformation生成的组合特征
但是,官方给出的示例代码中,Wide部分还使用了离散特征(没有one-hot)。也有大佬说不用特征交叉效果也很好,这个大家在实际项目中就以实验为准吧。
总结一下:
线性模型无法学习到训练集中未出现的组合特征;FM或DNN通过学习embedding vector虽然可以学习到训练集中未出现的组合特征,但是会过度泛化。Wide & Deep Model通过组合这两部分,解决了这些问题。
3,python(deepCTR)实现
本篇文章编写在DeepFM之后,要晚一些,详细的实现过程及解释可以去参考DeepFM,这里不再重复解释。
同样的,这里使用的代码主要采用开源的DeepCTR,相应的API文档可以在这里阅读。DeepCTR是一个易于使用、模块化和可扩展的深度学习CTR模型库,它内置了很多核心的组件从而便于我们自定义模型,它兼容tensorflow 1.4+和2.0+
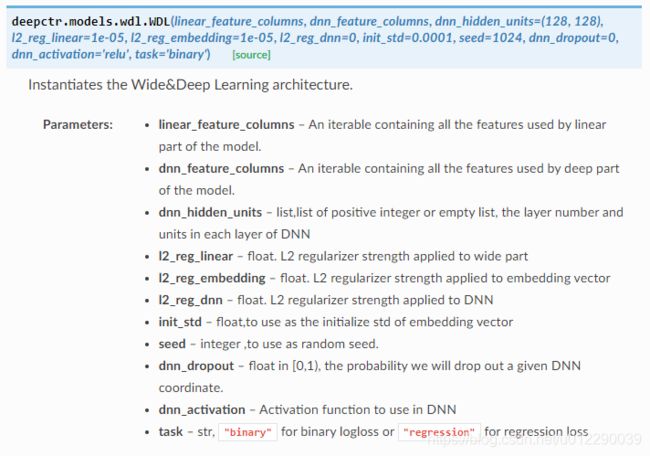
模型实现如下:
import pandas as pd
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import train_test_split
from deepctr.models.wdl import WDL
from deepctr.inputs import SparseFeat, DenseFeat, get_feature_names
data = pd.read_csv('./criteo_sample.txt')
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_features = ['I' + str(i) for i in range(1, 14)]
data[sparse_features] = data[sparse_features].fillna('-1', )
data[dense_features] = data[dense_features].fillna(0, )
target = ['label']
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(), embedding_dim=4)
for i, feat in enumerate(sparse_features)]
# 或者hash,vocabulary_size通常要大一些,以避免hash冲突太多
# sparse_feature_columns = [SparseFeat(feat, vocabulary_size=1e6,embedding_dim=4,use_hash=True)
# for i,feat in enumerate(sparse_features)]#The dimension can be set according to data
dense_feature_columns = [DenseFeat(feat, 1)
for feat in dense_features]
dnn_feature_columns = sparse_feature_columns + dense_feature_columns
linear_feature_columns = sparse_feature_columns + dense_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
train, test = train_test_split(data, test_size=0.2)
train_model_input = {name: train[name].values for name in feature_names}
test_model_input = {name: test[name].values for name in feature_names}
model = WDL(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy",
metrics=['binary_crossentropy'], )
history = model.fit(train_model_input, train[target].values,
batch_size=256, epochs=10, verbose=2, validation_split=0.2, )
pred_ans = model.predict(test_model_input, batch_size=256)
参考文献:
https://deepctr-doc.readthedocs.io/en/latest/deepctr.models.wdl.html
https://mp.weixin.qq.com/s?__biz=MzU0NDgwNzIwMQ==&mid=2247483689&idx=1&sn=c6e55677fe4ee1983e8f51fb61dffab5&chksm=fb77c167cc004871347a79fddb1c70d44f2b4bb54cbf09c3d1ecc5473ff8653802354d65bb8d&scene=21#wechat_redirect