Hive基准测试神器-hive-testbench
TPC-DS测试概述
在对Hive的语法及性能进行测试时,需要构造大量数据,TPC-DS测试基准是TPC组织推出的用于替代TPC-H的下一代决策支持系统测试基准。在使用TPC-DS时需要进行编译,生成数据以及查询SQL还要把Hive建表语句进行修改手动创建,数据也需要再上传hdfs,操作比较麻烦,数据生成性能也较差。hive-testbench是Hortonwork基于TPC-H和TPC-DS封装的专门用于Hive的基准测试工具,自动生成HDFS数据,并进行建表操作,使用非常方便。
TPC-H和TPC-DS相关介绍如下:
1. TPC-H
TPC-H是一款面向商品零售业的决策支持系统测试基准,它定义了8张表,22个查询,遵循SQL92。TPC-H的数据模型如图4所示。TPC-H基准的数据库模式遵循第三范式,叶晓俊教授等学者[6]认为“它的数据表数据特征单一(如数据不倾斜) ,其数据维护功能仅仅限制了潜在的对索引的过度使用,而没有测试DBMS 执行真实数据维护操作——数据提取、转换和加载(ETL) 功能的能力”。同时,新兴的数据仓库开始采用新的模型,如星型模型、雪花模型。TPC-H已经不能精准反映当今数据库系统的真实性能。为此,TPC组织推出了新一代的面向决策应用的TPC-DS 基准。
2. TPC-DS
TPC-DS采用星型、雪花型等多维数据模式。它包含7张事实表,17张纬度表平均每张表含有18列。其工作负载包含99个SQL查询,覆盖SQL99和2003的核心部分以及OLAP。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。可以说TPC-DS是与真实场景非常接近的一个测试集,也是难度较大的一个测试集。
TPC-DS的这个特点跟大数据的分析挖掘应用非常类似。Hadoop等大数据分析技术也是对海量数据进行大规模的数据分析和深度挖掘,也包含交互式联机查询和统计报表类应用,同时大数据的数据质量也较低,数据分布是真实而不均匀的。因此TPC-DS成为客观衡量多个不同Hadoop版本以及SQL on Hadoop技术的最佳测试集。这个基准测试有以下几个主要特点:
一共99个测试案例,遵循SQL’99和SQL 2003的语法标准,SQL案例比较复杂
分析的数据量大,并且测试案例是在回答真实的商业问题
测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等)
几乎所有的测试案例都有很高的IO负载和CPU计算需求
这个基准测试的完整信息请参考http://www.tpc.org/tpcds/。
Hive-testbentch介绍及使用
1. 基本介绍
hive-testbench是hortonworks的一个开源项目,github地址:http://github.com/hortonworks/hive-testbench, 该项目主要基于TPC-DS进行封装利用MapReduce的方式快速的生成Hive基准测试数据,接下来介绍如何编译及使用hive-testbench生成指定数据量的Hive基准测试数据。
2. 基本操作
hive-testbentch需要进行编译后才可以使用,由于测试要在内网进行,需要找一台可联网环境及逆行编译然后把编译后工具拷贝过来才可以使用。
具体步骤如下:
1、下载hive-testbench-hdp源码(可用git clone),并下载TPCDS_Tools.zip包(更名为tpcds_kit.zip,后续会用上)。
2、虚拟机需要安装(缺少什么装什么):
gcc,yum -y install gcc gcc-c++安装;
maven,依赖python和java环境(这个工具会自动安装);
3、在虚拟机中进入到hive-testbench-hdp3/目录下,执行tpcds-build.sh,编译脚本会调用tpcds-gen目录下执行make,等执行完毕后,进入目录 “/hive-testbench-hdp3/tpcds-gen/target”,可以找到 “tpcds-gen-1.0-SNAPSHOT.jar”文件,此文件是内网无法产生最为需要的。
4、将整个hive-testbench-hdp3文件上传到内网环境中,此时可开始进行测试。
5、生成数据时可以设置数据格式,FORMAT=parquet ./tpcds-setup.sh 10 /tpcds
参数说明:
- FORMAT=parquet ,指定格式化方式为parquet,也可以是rcfile等等,默认是textfile格式
- 10表示生成的数据量大小GB单位
- /tpcds表示数据在HDFS上生成的目录,目录不存在自动生成,如果不指定数据目录则默认生成到/tmp/tpcds目录下。
执行时我们可以看到生成数据的方式是向集群提交了一个MapReduce作业,这种方式更适合大量数据的快速生成,等待脚本执行成功:
后面这个optimizing过程就是格式化数据为指定FORMAT格式的过程,最后我们生成了两个数据库一个数据库中的格式是text,一个是parquet。使用该命令hdfs dfs -du -h /tpcds/10 查看生成表的大小数据总量与指定10GB数据量一致(注意:这里生成数据会与指定的量会有些许出入)
3 运行测试
测试sql脚本目录:sample-queries-tpcds
$ cd sample-queries-tpcds
hive> use tpcds_bin_partitioned_parquet_10;
hive> source query12.sql;
4 批量测试
根据需要修改hive配置:sample-queries-tpcds/testbench.settings
根据需要修改测试脚本(perl):runSuite.pl
$ perl runSuiteCommon.pl
ERROR: one or more parameters not definedUsage:
perl runSuiteCommon.pl [tpcds|tpch] [scale]Description:
This script runs the sample queries and outputs a CSV file of the time it took each query to run. Also, all hive output is kept as a log file named 'queryXX.sql.log' for each query file of the form 'queryXX.sql'. Defaults to scale of 2.
核心代码:
my $suite = shift;
my $scale = shift || 2;
dieWithUsage("suite name required") unless $suite eq "tpcds" or $suite eq "tpch";
chdir $SCRIPT_PATH;
if( $suite eq 'tpcds' ) {
chdir "sample-queries-tpcds";
} else {
chdir 'sample-queries-tpch';
} # end if
my @queries = glob '*.sql';
my $db = {
'tpcds' => "tpcds_bin_partitioned_orc_$scale",
'tpch' => "tpch_flat_orc_$scale"
};
print "filename,status,time,rows\n";
for my $query ( @queries ) {
my $logname = "$query.log";
my $cmd="echo 'use $db->{${suite}}; source $query;' | hive -i testbench.settings 2>&1 | tee $query.log";这个脚本有两个参数:suite scale,比如tpcds 10
可以修改的更通用,一个是数据库硬编码orc,一个是硬编码hive命令,一个是打印正在执行的cmd,一个是启动命令有初始化环境的时间成本,直接使用beeline连接server的耗时更真实;修改之后可以用于其他测试,比如spark-sql、impala、drill等;
修改之后是这样:
#!/usr/bin/perl
use strict;
use warnings;
use POSIX;
use File::Basename;
# PROTOTYPES
sub dieWithUsage(;$);
# GLOBALS
my $SCRIPT_NAME = basename( __FILE__ );
my $SCRIPT_PATH = dirname( __FILE__ );
# MAIN
dieWithUsage("one or more parameters not defined") unless @ARGV >= 4;
my $suite = shift;
my $scale = shift || 2;
my $format = shift || 3;
my $engineCmd = shift || 4;
dieWithUsage("suite name required") unless $suite eq "tpcds" or $suite eq "tpch";
print "params: $suite, $scale, $format, $engineCmd;";
chdir $SCRIPT_PATH;
if( $suite eq 'tpcds' ) {
chdir "sample-queries-tpcds";
} else {
chdir 'sample-queries-tpch';
} # end if
my @queries = glob '*.sql';
my $db = {
'tpcds' => "tpcds_bin_partitioned_${format}_$scale",
'tpch' => "tpch_flat_${format}_$scale"
};
print "filename,status,time,rows\n";
for my $query ( @queries ) {
my $logname = "$query.log";
my $cmd="${engineCmd}/$db->{${suite}} -i conf.settings -f $query 2>&1 | tee $query.log";
# my $cmd="cat $query.log";
#print $cmd ; exit;
my $currentTime = strftime("%Y-%m-%d %H:%M:%S", localtime(time));
print "$currentTime : ";
print "$cmd \n";
my $hiveStart = time();
my @hiveoutput=`$cmd`;
die "${SCRIPT_NAME}:: ERROR: hive command unexpectedly exited \$? = '$?', \$! = '$!'" if $?;
my $hiveEnd = time();
my $hiveTime = $hiveEnd - $hiveStart;
my $is_success = 0;
foreach my $line ( @hiveoutput ) {
if( $line =~ /[(\d+|No)]\s+row[s]? selected \(([\d\.]+) seconds\)/ ) {
$is_success = 1;
print "$query,success,$hiveTime,$1\n";
} # end if
} # end while
if( $is_success == 0) {
print "$query,failed,$hiveTime\n";
}
} # end for
sub dieWithUsage(;$) {
my $err = shift || '';
if( $err ne '' ) {
chomp $err;
$err = "ERROR: $err\n\n";
} # end if
print STDERR <执行:
# beeline to hiveserver2
$ perl runSuite.pl tpcds 10 parquet "$HIVE_HOME/bin/beeline -u jdbc:hive2://localhost:10000"
# beeline to spark thrift server
$ perl runSuite.pl tpcds 10 parquet "$SPARK_HOME/bin/beeline -u jdbc:hive2://localhost:11111"
# beeline to impala
perl runSuite.pl tpcds 10 parquet "$HIVE_HOME/bin/beeline -d com.cloudera.impala.jdbc4.Driver -u jdbc:impala://localhost:21050"
批量测试脚本
#!/bin/sh
current_dir=`pwd`
scale="$1"
format="$2"
if [ -z "$scale" ]; then
scale=10
fi
if [ -z "$format" ]; then
format="parquet"
fi
#echo "$current_dir $component $scale $test_dir"
echo "mkdir merge"
echo ""
component="hive"
test_dir="test_$component"
echo "# test $component"
echo "mkdir $test_dir"
echo "cp -R sample-queries-tpcds $test_dir"
echo "ln -s $current_dir/runSuiteCommon.pl $test_dir/runSuite.pl"
echo "cd $test_dir"
echo "perl runSuite.pl tpcds ${scale} $format \"$HIVE_HOME/bin/beeline -i conf.settings -n hadoop -u jdbc:hive2://localhost:10000\" 2>&1| tee ${component}_${scale}_${format}.log"
echo "cd .."
echo "grep -e '^query' $test_dir/${component}_${scale}_${format}.log|sort > merge/${component}_${scale}_${format}.log"
echo "wc -l merge/${component}_${scale}_${format}.log"
echo ""
component="spark"
test_dir="test_$component"
echo "# test $component"
echo "mkdir $test_dir"
echo "cp -R sample-queries-tpcds $test_dir"
echo "ln -s $current_dir/runSuiteCommon.pl $test_dir/runSuite.pl"
echo "cd $test_dir"
echo "perl runSuite.pl tpcds ${scale} $format \"$SPARK_HOME/bin/beeline -i conf.settings -u jdbc:hive2://localhost:11111\" 2>&1| tee ${component}_${scale}_${format}.log"
echo "cd .."
echo "grep -e '^query' $test_dir/${component}_${scale}_${format}.log|sort > merge/${component}_${scale}_${format}.log"
echo "wc -l merge/${component}_${scale}_${format}.log"
echo ""
component="impala"
test_dir="test_$component"
echo "# test $component"
echo "mkdir $test_dir"
echo "cp -R sample-queries-tpcds $test_dir"
echo "ln -s $current_dir/runSuiteCommon.pl $test_dir/runSuite.pl"
echo "cd $test_dir"
echo "perl runSuite.pl tpcds ${scale} $format \"$HIVE_HOME/bin/beeline -i conf.settings -d com.cloudera.impala.jdbc4.Driver -u jdbc:impala://localhost:21050\" 2>&1| tee ${component}_${scale}_${format}.log"
echo "cd .."
echo "grep -e '^query' $test_dir/${component}_${scale}_${format}.log|sort > merge/${component}_${scale}_${format}.log"
echo "wc -l merge/${component}_${scale}_${format}.log"
echo ""
component="presto"
test_dir="test_$component"
echo "# test $component"
echo "mkdir $test_dir"
echo "cp -R sample-queries-tpcds $test_dir"
echo "ln -s $current_dir/runSuiteCommon.pl $test_dir/runSuite.pl"
echo "cd $test_dir"
echo "perl runSuite.pl tpcds ${scale} $format \"$HIVE_HOME/bin/beeline -i conf.settings -d com.facebook.presto.jdbc.PrestoDriver -n hadoop -u jdbc:presto://localhost:8080/hive\" 2>&1| tee ${component}_${scale}_${format}.log"
echo "cd .."
echo "grep -e '^query' $test_dir/${component}_${scale}_${format}.log|sort > merge/${component}_${scale}_${format}.log"
echo "wc -l merge/${component}_${scale}_${format}.log"
echo "awk -F ',' '{if(NF==4){print \$1\",\"\$4}else{print \$1\",0\"}}' merge/hive_${scale}_${format}.log > /tmp/hive_${scale}_${format}.log"
echo "awk -F ',' '{if(NF==4){print \$4}else{print \"0\"}}' merge/spark_${scale}_${format}.log > /tmp/spark_${scale}_${format}.log"
echo "awk -F ',' '{if(NF==4){print \$4}else{print \"0\"}}' merge/impala_${scale}_${format}.log > /tmp/impala_${scale}_${format}.log"
echo "awk -F ',' '{if(NF==4){print \$4}else{print \"0\"}}' merge/presto_${scale}_${format}.log > /tmp/presto_${scale}_${format}.log"
echo "paste -d\",\" /tmp/hive_${scale}_${format}.log /tmp/spark_${scale}_${format}.log /tmp/impala_${scale}_${format}.log /tmp/presto_${scale}_${format}.log > merge/result_${scale}_${format}.csv"
echo "sed -i \"1i sql_${scale}_${format},hive,spark,impala,presto\" merge/result_${scale}_${format}.csv"
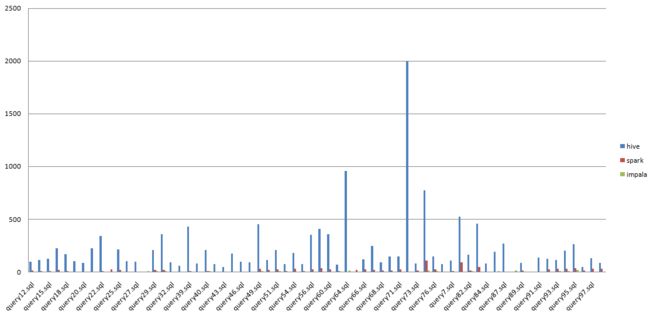
echo ""结果合并之后使用excel图形化显示