论文理解【Offline RL】——【BooT】Bootstrapped Transformer for Offline Reinforcement Learning
- 标题:Bootstrapped Transformer for Offline Reinforcement Learning
- 文章链接:Bootstrapped Transformer for Offline Reinforcement Learning
- 官方主页:Bootstrapped Transformer for Offline Reinforcement Learning
- 发表:NIPS 2022
- 领域:离线强化学习(offline/batch RL)—— Transformer-Based / 数据增强
- 摘要:Offline RL 的目标是在不与真实环境交互的情况下,从以前收集的静态轨迹数据中学习 policy。最近的工作提供了一个新的视角,即将 Offline RL 视为一个通用的序列生成问题,采用序列模型来建模轨迹分布,并利用 Beam Search 作为一种规划算法。然而,用于一般 Offline RL 任务的训练数据常常相当有限,常受数据分布覆盖不足问题的影响,这可能对训练序列生成模型有害。本文中,我们提出一种新算法名为 Bootstrapped Transformer (BooT),它包含 bootstrapping 思想,能利用学得模型自我生成更多的 Offline 数据来进一步辅助序列模型的训练。我们在两个 Offline RL benchmarks 上进行了广泛的实验,证明了我们的模型可以在很大程度上弥补现有 Offline RL 训练的限制,并击败其他强 Baseline 方法。我们还分析了模型生成的伪数据,所揭示的特征可能有助于 Offline RL 训练。代码和补充材料可在 https://seqml.github.io/bootorl 上找到
文章目录
- 1.背景
- 2. 本文方法
-
- 2.1 思想
- 2.2 方法
-
- 2.2.1 训练序列模型
- 2.2.2 生成伪轨迹
- 2.2.3 在增强数据集上训练
- 2.2.4 伪代码
- 3. 实验
-
- 3.1 性能对比
- 3.2 伪轨迹分析
- 3.3 其他
- 4. 总结
1.背景
Offline RL是这样一种问题设定:Learner 可以获取由一批 episodes 或 transitions 构成的固定交互数据集,要求 Learner 直接利用它训练得到一个好的策略,而且禁止 Learner 和环境进行任何交互,示意图如下

关于 Offline RL 的详细介绍,请参考 Offline/Batch RL简介- Offline RL 是近年来很火的一个方向,下图显示了 2019 年以来该领域的重要工作

本文出现在 22 年,是对 21 年重要方法 TT 的一个扩展。TT 使用具有生成能力的 GPT 模型直接对 Offline 轨迹进行建模(注意这相当于同时建模环境和 behavior policy),然后使用规划算法 Beam Search 方法进行规划,依据规划时使用的不同标准,可以做 IL、Goal conditioned RL、Offline RL 等等任务。本文很大程度上只是对 TT 训练过程的一个改变,模型本身没有太多变化,因此务必先了解 TT,可参考 论文理解【Offline RL】——【TT】Offline Reinforcement Learning as One Big Sequence Modeling Problem
2. 本文方法
2.1 思想
-
本文思想很简单,由于 TT 模型本身是在对 Offline 轨迹进行建模,理论上它可以生成分布内的伪轨迹,进一步地,TT 论文中验证了其具有很强的长跨度轨迹预测能力,因此这些伪轨迹至少是比较可靠的。受此启发,作者想利用 TT 模型的 “伪轨迹生成能力” 对 Offline 数据进行扩展,再用扩展后的数据训练 TT,如此 bootstrap 迭代下去以提升性能,这也是本文方法名称 Bootstrapped Transformer (BooT) 的由来
这种想法是比较合理的,因为训练 GPT 对数据量要求较高,如果能补充更多分布内数据,对 GPT 的训练肯定有帮助,作者想以此缓解数据不足的影响。但另一方面,数据不足时 GPT 本身可能就训得比较差,这种情况下其生成的轨迹是否还很可靠就要打个问号了,我觉得数据量应该至少达到某个门槛才能开始有效的 bootstrap
-
在使用 Transformer-based 的方法解 Offline RL 问题时,数据层面主要有以下两个问题制约模型性能
Offline 数据分布覆盖窄:由于 Offline RL 不限制 behavior policy,Offline 数据集可能来自熵很小的策略,导致轨迹分布空间的覆盖度很小,比如使用专家策略收集数据时常有此问题Offline 数据量少:Transformer 模型容量非常大,对训练数据复杂度的要求很高。Offline 常见的 D4RL 数据集中只包含约 4000 条轨迹,而 NLP 领域中训练 GPT/BERT 等模型的数据集通常比这高几个数量级
传统 Offline RL 也受到数据制约,因此过去也有些数据增强方法,包括
- 对于状态为图像输入的环境,可以用 CV 领域的各种数据增强方法,这个思路其实上古时期就有了,甚至世界上第一篇 IL 文章中就能看到。这类方法的问题在于只能用于状态输入是图像形式的环境,且增强后可能不符合马尔可夫性
- 先对环境建模,再配合一定的策略 “想象” 出伪轨迹,这些一般都是 model-based 方法了。这类方法的问题在于需要单独学习环境,而模型学习和策略优化的目标并不一致,这可能会得到次优解,且传统方法没有使用 Transformer 等先进序列建模框架
-
为解决以上问题,作者充分利用 TT 的 “可靠长跨度序列生成能力” 来做数据增强,即 “一边基于 Offline 数据集训练 TT 轨迹生成器,一边使用 TT 模型本身来成伪轨迹来扩展 Offline 数据集”。实验中作者进一步对比了以下两个实现细节
- 训练 TT(本质是 GPT)时使用 AutoRegress 模式还是 Teacher-Forcing 模式
- 生成的伪轨迹是只用一次就丢弃,还是加入到 Offline 数据集(可能在将来多次重用)
2.2 方法
- 作者提出的 BooT 分为以下几个主要部分
- 用 Offline 数据集训练 GPT 序列生成模型
- 用学习到的模型生成伪轨迹
- 使用生成的轨迹来增强原始 Offline 数据集,并引导序列模型学习
2.2.1 训练序列模型
- 本文中序列模型的
模型结构、轨迹序列的 tokenize 方法、训练优化目标及序列模型训练好后的规划方法都和 TT 完全一致,训练方式上除了 TT 使用的 Teacher-Forcing 方式,还测试了 AutoRegress 方式,基本可以说本文使用的序列模型就是 21 年的 TT 模型。具体而言- 模型结构:标准 GPT 模型
- 序列的 tokenize 方法:首先在轨迹中加入辅助的 reward-to-go 信息 R t = ∑ t ′ = t T γ t ′ − t r t ′ R_t = \sum_{t'=t}^T\gamma^{t'-t}r_{t'} Rt=∑t′=tTγt′−trt′ 以避免后续规划是出现短视问题(具体说明参考 TT 论文),Offline 轨迹表示为
τ aux = ( s 1 , a 1 , r 1 , R 1 , … , s T , a T , r T , R T ) \boldsymbol{\tau}_{\text {aux }}=\left(\boldsymbol{s}_{1}, \boldsymbol{a}_{1}, r_{1}, R_{1}, \ldots, \boldsymbol{s}_{T}, \boldsymbol{a}_{T}, r_{T}, R_{T}\right) τaux =(s1,a1,r1,R1,…,sT,aT,rT,RT) 接下来将可能是连续取值的 state 和 action 的各个维度分别离散化以完成 tokenize 。假设状态空间和动作空间分布是 N N N 和 M M M 维,则 tokenize 后轨迹表示为
τ d i s = ( … , s t 1 , s t 2 , … , s t N , a t 1 , a t 2 , … , a t M , r t , R t , … ) \boldsymbol{\tau}_{\mathrm{dis}}=\left(\ldots, s_{t}^{1}, s_{t}^{2}, \ldots, s_{t}^{N}, a_{t}^{1}, a_{t}^{2}, \ldots, a_{t}^{M}, r_{t}, R_{t}, \ldots\right) τdis=(…,st1,st2,…,stN,at1,at2,…,atM,rt,Rt,…) 轨迹长度(所含 token 数量)从 T T T 变成 ( M + N + 2 ) T (M+N+2)T (M+N+2)T - 训练过程就是用 AutoRegress 或者 Teacher-Forcing 方法来最大化 Offline 轨迹的对数似然函数。我们首先定义模型单步预测/生成 token 的对数似然为
log P θ ( τ t ∣ τ < t ) = ∑ i = 1 N log P θ ( s t i ∣ s t < i , τ < t ) + ∑ j = 1 M log P θ ( a t j ∣ a t < j , s t , τ < t ) + log P θ ( r t ∣ a t , s t , τ < t ) + log P θ ( R t ∣ r t , a t , s t , τ < t ) , \begin{aligned} \log P_{\theta}\left(\boldsymbol{\tau}_{t} \mid \boldsymbol{\tau}_{
L ( τ ) = ∑ t = 1 T log P θ ( τ ∣ τ < t ) \mathcal{L}(\pmb{\tau}) = \sum_{t=1}^T \log P_\theta(\pmb{\tau}|\pmb{\tau}_{< t}) L(τ)=t=1∑TlogPθ(τ∣τ<t) 其中 τ < t \pmb{\tau}_{ - GPT 模型训练完成后的规划阶段,使用 Beam Search 最大化每个时刻模型预测/生成的 r t + R t r_t+R_t rt+Rt
2.2.2 生成伪轨迹
-
现在考虑如何用训练好的轨迹 GPT 模型生成伪轨迹。首先从 Offline 数据集中任取一条轨迹 τ ∈ D \pmb{\tau} \in\mathcal{D} τ∈D 然后用 GPT 模型预测/生成其最后 T ′ < T T'
T′<T 个时间步,即
τ ~ > T − T ′ = ( s ~ T − T ′ + 1 , a ~ T − T ′ + 1 , … , R ~ T ) ∼ P θ ( τ > T − T ′ ∣ τ ≤ T − T ′ ) \tilde{\boldsymbol{\tau}}_{>T-T^{\prime}}=\left(\tilde{\boldsymbol{s}}_{T-T^{\prime}+1}, \tilde{\boldsymbol{a}}_{T-T^{\prime}+1}, \ldots, \tilde{R}_{T}\right) \sim P_{\theta}\left(\boldsymbol{\tau}_{>T-T^{\prime}} \mid \boldsymbol{\tau}_{\leq T-T^{\prime}}\right) τ~>T−T′=(s~T−T′+1,a~T−T′+1,…,R~T)∼Pθ(τ>T−T′∣τ≤T−T′) 其中 τ ≤ T − T ′ \boldsymbol{\tau}_{\leq T-T^{\prime}} τ≤T−T′ 代表原始轨迹的前 T − T ′ T-T' T−T′ 个时间步,将它和重新预测的最后 T ′ T' T′ 个时间步拼接就得到新轨迹/伪轨迹
τ ′ = τ ≤ T − T ′ ∘ τ ~ > T − T ′ \boldsymbol{\tau}^{\prime}=\boldsymbol{\tau}_{\leq T-T^{\prime}} \circ \tilde{\boldsymbol{\tau}}_{>T-T^{\prime}} τ′=τ≤T−T′∘τ~>T−T′ -
这里作者考虑了两种不同的生成方法来生成最后 T ′ T' T′ 个时间步 n n n 个 token 的新轨迹
Autoregressive generation (AG):在顺序生成多个时间步时,后面的预测是基于先前生成的 token 进行的。用公式表示,第 n n n 个 token 是从条件包含前 n − 1 n-1 n−1 的个生成 token y ~ < n \tilde{\boldsymbol{y}}_{
y ~ n ∼ P θ ( y n ∣ y ~ < n , τ ≤ T − T ′ ) \tilde{y}_{n} \sim P_{\theta}\left(y_{n} \mid \tilde{\boldsymbol{y}}_{Teacher-forcing generation (TF):在顺序生成多个时间步时,每一步预测都是基于原始轨迹进行的。用公式表示,第 n n n 个 token 是从条件仅包含原始序列 token y < n \boldsymbol{y}_{
y ~ n ∼ P θ ( y n ∣ y < n , τ ≤ T − T ′ ) \tilde{y}_{n} \sim P_{\theta}\left(y_{n} \mid \boldsymbol{y}_{
由于 Autoregressive 过程存在误差积累,这种方式生成的伪轨迹相比 Teacher-forcing 会更偏离原始轨迹分布,可以更有效地扩展数据集,但由于需要 n n n 次串行前向传播(相比而言 Teacher-forcing 可以一次并行做完),Autoregressive 生成伪轨迹的时间消耗要多很多倍。下面给出两种伪轨迹生成方式的示意图
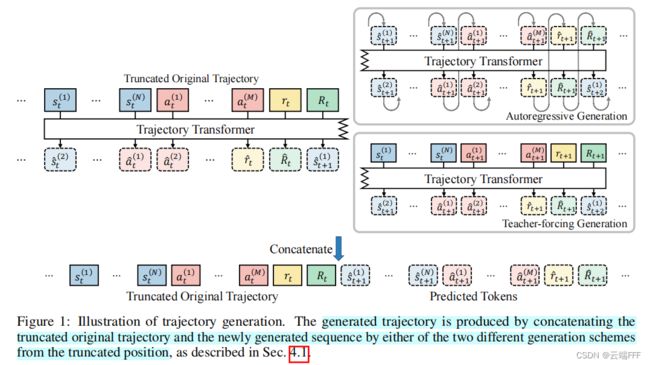
2.2.3 在增强数据集上训练
- 这是本文的重点也是核心创新点,得到 2.2.2 节的伪轨迹后,我们进一步用它们来指导 2.2.1 节中序列模型的训练。这里作者也考虑了两种细节做法
只用一次 (BooT-o):每个生成的伪轨迹用来更新一次序列模型后就丢弃重复使用 (BooT-r):每个生成的伪轨迹都直接加入 Offline 数据集 D \mathcal{D} D,这样伪轨迹可能被多次抽样来更新模型
- 为了避免因生成的伪轨迹不够准确使模型引入偏差,作者只选择每个 batch 中置信度 top η % \eta\% η% 的伪轨迹来指导模型。这里
置信度定义为所有生成 token 的平均对数概率
c ( τ ) = 1 T ′ ( N + M + 2 ) ∑ t = T − T ′ + 1 T log P θ ( τ t ∣ τ < t ) c(\boldsymbol{\tau})=\frac{1}{T^{\prime}(N+M+2)} \sum_{t=T-T^{\prime}+1}^{T} \log P_{\theta}\left(\boldsymbol{\tau}_{t} \mid \tau_{ - 为稳定 bootstrap 训练过程,训练应从原始 Offline 数据开始再逐渐引入伪轨迹。作者这里做法很简单,使用原始 Offline 数据训练 k k k 个 epoch 后开始引入伪轨迹,这种简单的 schedule 在实验中显示出了良好的有效性,且无需引入过多超参数
2.2.4 伪代码
- 下面给出本文的伪代码,蓝/黄/红三个色块分别代表上面的 2.2.1/2.2.2/2.2.3 节

3. 实验
3.1 性能对比
- 实验环境包括 D4RL Gym 的连续控制任务和 D4RL Adroit 和中的几个高维机械臂任务,对比方法包括 BC、MBOP(model-based SOTA )、CQL(model-free SOTA)以及 Transformer-based 方法 DT 和 TT
-
Gym 结果如下
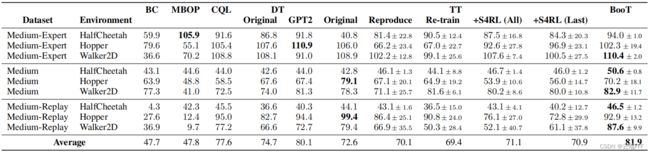
DT-GPT2是序列模型改用 GPT2 的 DTTT-Reproduce是作者重新实现的 TTTT-Retrain是在普通 TT 训练 k k k 个epoch 后,对每个 batch 随机选择 ⌊ η % ⋅ K ⌋ \lfloor\eta \% \cdot K\rfloor ⌊η%⋅K⌋ 条原始轨迹再训练一下,以保证 TT 和 BooT 的训练步数相同TT-S4RL(All)是对 Offline 轨迹中所有状态添加随机噪声,目的是比较其他 Offline 数据增强方法TT-S4RL(Last)是对 Offline 轨迹中最后 T ‘ T‘ T‘ 个时间步的状态添加随机噪声,目的是比较其他 Offline 数据增强方法
这里所有实验中 TT 都用了相同的超参数,BooT 使用了与 TT 相同的模型结构和模型大小。如上表所示
- BooT 相比其他方法更好或媲美
- 和 TT-Reproduce、TT-Retrain 之间的比较表明,BooT 性能的提高并不是由于算法的额外训练步骤
- 和 TT-S4RL 之间的比较表明,直接在训练数据中添加高斯噪声并不能有效地提高性能,作者认为 BooT 性能更好可能是因为其序列模型生成的伪轨迹比通过添加噪声得到的伪轨迹更符合真实 MDP
-
Adroit 结果如下
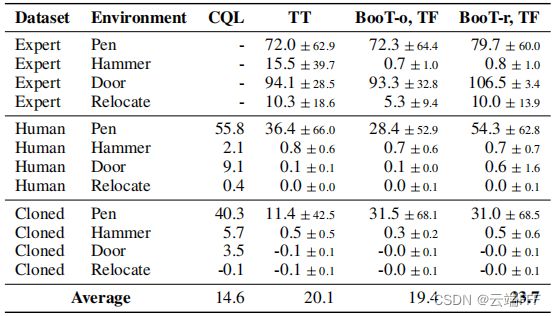
这个有点牵强了,CQL 在被测试的所有 Offline RL 任务上表现都更好,不过 BooT 的性能确实超过了 TT Baseline。由于这里轨迹维数太大,Autoregress 生成耗时太久,因此这里只做了 Teacher-Forcing 实验
-
- 另外,作者在 gym 环境对比了 AG 和 TF 两种伪轨迹生成方式,发现这些简单环境中没有太大区别

3.2 伪轨迹分析
-
为了比较 BooT 通过 GPT 生成的伪轨迹和传统方案 S4RL 中通过添加高斯噪声生成的伪轨迹的性质,作者分别计算了 “伪轨迹距离原始 Offline 轨迹”(记为 Dataset)的 RMSE 和 MMD和 “伪轨迹距离评估时真实遇到轨迹”(记为 Environment)的 RMSE 和 MMD,如下
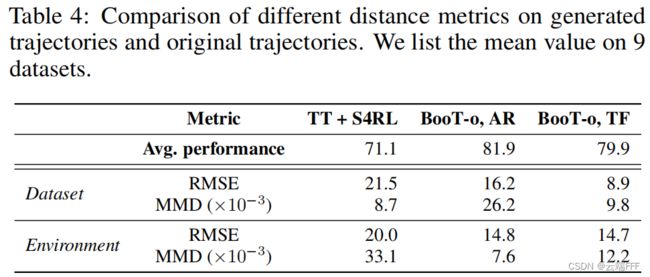
这里 RMSE 反映伪轨迹在欧氏空间中与原始 Offline 轨迹的距离;MMD 反映伪轨迹分布和原始 Offline 轨迹分布间的差距。如图所示,与 Baseline TT+S4RL 这样添加随机噪声的 naive 增强方案相比- 相比 Offline 数据集,BooT 产生的轨迹 RMSE 更小,而 MMD 更大,说明伪轨迹在欧几里得空间中原始轨迹的邻域中,且其分布和原始轨迹不太一样,表明 BooT 确实扩展了原始的 Offline 数据
- 相比评估时真实遇到的轨迹,BooT 产生的轨迹 RMSE 和 MMD 都更小,说明生成的伪轨迹更符合真实分布的底层 MDP,BooT 对原始离线数据的扩展是合理的,模型性能因此能够提升
作者还对 halfcheetah-medium dataset,使用 t-SNE 方法绘制了轨迹 transition 的二维嵌入图,如下
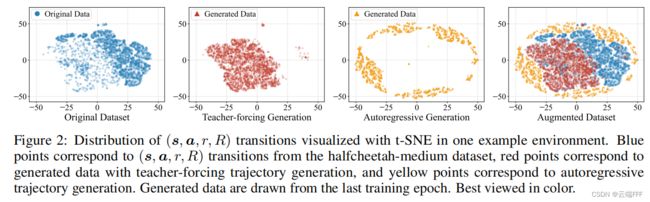
这里就能很清楚地看到 BooT 对原始 Offline 数据集的扩展情况,TF 方法生成的很大一部分数据与原始数据集重叠,而 AG 生成的数据则远离原始数据分布。总体结果表明 BooT 生成的伪轨迹确实扩展了数据覆盖范围,且保持了与 RL 任务的底层 MDP 的一致性,因此它能获得比 Baseline 更好的性能,且无需 “悲观假设” 等额外约束也能工作
3.3 其他
- 作者还实验分析了超参数 k , η , T ′ k,\eta,T' k,η,T′ 对性能的影响,具体请看原文。比较有意思的是设置 T ′ = 1 T'=1 T′=1 是比较好的选择
- 另外作者测试了 BooT 的伪轨迹能否用于辅助 CQL 这样的传统 Offline RL 算法,遗憾的是这样做表现不佳
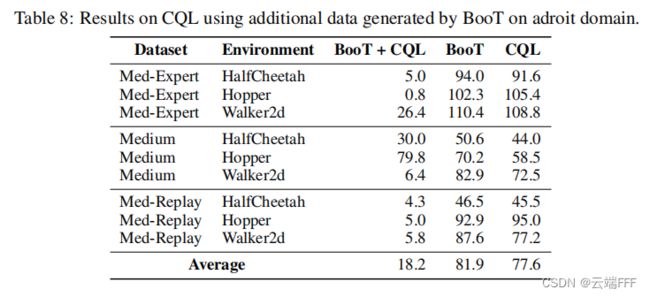
作者认为问题出在两方面- BooT 生成的数据是离散化的,而CQL使用来自环境的原始连续数据格式,从离散的 token 中恢复连续的输入数据可能会导致信息丢失
- BooT 是一种自改进的方法,它利用生成的数据来改进序列模型本身,这里和传统方法结合的做法不符合 BooT 的设计思想,它本身不是针对这样使用而设计的
4. 总结
- 这篇文章在模型层面没什么改进,但是充分利用 TT 模型的轨迹生成能力在训练流程部分进行了创新,这个思路值得学习
- 结合最近的一些热点看,大规模生成模型潜力巨大,目前引领潮流的主要是 NLP 领域,而 RL 这边刚起步,NLP 的发展动向值得密切关注