【Pytorch】normal_(), fill_(), index_fill(),nonzero(),index_select(),masked_fill(),torch.scatter()函数解读
1 首先初始化一个矩阵shape(3,5)
x=torch.zeros(3,5)
x
#输出
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
2 x.normal_()
x.normal_()
#输出
tensor([[-2.2073, 0.2486, -1.9729, 1.1014, 1.0692],
[-1.4998, 0.2739, -1.6685, -0.2012, -1.4844],
[-0.3354, 0.0196, 1.9857, 1.1611, -0.8139]])
3 x.fill_(1)
x.fill_(1)
#输出
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
这两个函数常常用在神经网络模型参数的初始化中
例如:
net = torch.nn.Linear(16, 2)
for m in net.modules():
if isinstance(m, nn.Linear):
m.weight.data.normal_(mean=0, std=0.01)
m.bias.data.fill_(0.0)
4 index_fill_()原地修改
Parameters
dim (int) – dimension along which to index
index (LongTensor) – indices of self tensor to fill in
value (float) – the value to fill with
index_fill_(dim,index,value)通过按index中给定的顺序 选择索引,用value值填充元素
dim(int)–索引所依据的维度
index(LongTensor)–要填充的自张量的索引
value(浮点数)–要填充的值
x=torch.rand(5,5)
x
#输出
tensor([[0.7544, 0.5131, 0.0514, 0.2504, 0.6123],
[0.5966, 0.1831, 0.5157, 0.4867, 0.5622],
[0.8991, 0.1074, 0.6713, 0.1969, 0.8667],
[0.5758, 0.3801, 0.1418, 0.5761, 0.6210],
[0.3357, 0.1730, 0.4177, 0.3893, 0.2613]])
idx=torch.tensor([1,3])
x.index_fill_(0,idx,6)
#输出
tensor([[0.7544, 0.5131, 0.0514, 0.2504, 0.6123],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.8991, 0.1074, 0.6713, 0.1969, 0.8667],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.3357, 0.1730, 0.4177, 0.3893, 0.2613]])
x
#输出
tensor([[0.7544, 0.5131, 0.0514, 0.2504, 0.6123],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.8991, 0.1074, 0.6713, 0.1969, 0.8667],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.3357, 0.1730, 0.4177, 0.3893, 0.2613]])
5 index_fill()不改变原数据,将修改的结果返回
x=torch.rand(5,5)
x
#输出
tensor([[0.5710, 0.5054, 0.1349, 0.0128, 0.5955],
[0.6552, 0.1424, 0.2844, 0.1823, 0.3272],
[0.2421, 0.7303, 0.8094, 0.8583, 0.6807],
[0.1183, 0.2639, 0.0735, 0.6195, 0.1194],
[0.4702, 0.5043, 0.2006, 0.4968, 0.1472]])
idx=torch.tensor([1,3])
x.index_fill(0,idx,6)
#输出
tensor([[0.5710, 0.5054, 0.1349, 0.0128, 0.5955],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.2421, 0.7303, 0.8094, 0.8583, 0.6807],
[6.0000, 6.0000, 6.0000, 6.0000, 6.0000],
[0.4702, 0.5043, 0.2006, 0.4968, 0.1472]])
x
#输出
tensor([[0.5710, 0.5054, 0.1349, 0.0128, 0.5955],
[0.6552, 0.1424, 0.2844, 0.1823, 0.3272],
[0.2421, 0.7303, 0.8094, 0.8583, 0.6807],
[0.1183, 0.2639, 0.0735, 0.6195, 0.1194],
[0.4702, 0.5043, 0.2006, 0.4968, 0.1472]])
6 nonzero()
获取所有非零元素的下标
x=torch.rand(3,3)
x
#输出
tensor([[0.5246, 0.6662, 0.7522],
[0.2468, 0.7157, 0.6423],
[0.0796, 0.3659, 0.6216]])
x.nonzero()
#torch.nonzero(x)也是同样的效果
#输出
tensor([[0, 0],
[0, 1],
[0, 2],
[1, 0],
[1, 1],
[1, 2],
[2, 0],
[2, 1],
[2, 2]])
7 nonzero()的另一种用法
torch.nonzero(x>0.5)
#输出
tensor([[0, 0],
[0, 1],
[0, 2],
[1, 1],
[1, 2],
[2, 2]])
输出所有位置上的元素>0.5的元素的下标
8 index_select()
torch.index_select(input, dim, index) 函数返回的是沿着输入张量的指定维度的指定索引号进行索引的张量子集,函数参数有:
input(Tensor) - 需要进行索引操作的输入张量;
dim(int) - 需要对输入张量进行索引的维度;
index(LongTensor) - 包含索引号的 1D 张量;
x=torch.rand(3,3)
x
#输出
tensor([[0.5246, 0.6662, 0.7522],
[0.2468, 0.7157, 0.6423],
[0.0796, 0.3659, 0.6216]])
torch.index_select(x,dim=0,index=torch.tensor([0,2]))
#输出
tensor([[0.5246, 0.6662, 0.7522],
[0.0796, 0.3659, 0.6216]])
torch.index_select(x,dim=1,index=torch.tensor([1]))
#输出
tensor([[0.6662],
[0.7157],
[0.3659]])
9 结合使用torch.nonzero()和torch.index_select(),可以选出符合某种条件的元素。下面的例子是从一维张量a中选出大于6的元素
参考:http://t.zoukankan.com/picassooo-p-15187175.html
a=torch.tensor([9.3,4.2,8.5,2.7,5.9])
print(a)
b=torch.nonzero(a>6,as_tuple=False)
print(b)
c=torch.index_select(a,dim=0,index=b.squeeze())
print(c)
#输出
tensor([9.3000, 4.2000, 8.5000, 2.7000, 5.9000])
tensor([[0],
[2]])
tensor([9.3000, 8.5000])
10 masked_fill()
部分参考:https://zhuanlan.zhihu.com/p/151783950
The shape of mask must be broadcastable with the shape of the underlying tensor.
import torch
a=torch.tensor([[[5,5,5,5], [6,6,6,6], [7,7,7,7]], [[1,1,1,1],[2,2,2,2],[3,3,3,3]]])
print(a)
print(a.size())
print("#############################################3")
mask = torch.ByteTensor([[[1],[1],[0]],[[0],[1],[1]]])
print(mask.size())
b = a.masked_fill(mask, value=torch.tensor(-1e9))
print(b)
print(b.size())
#输出
tensor([[[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]],
[[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]]])
torch.Size([2, 3, 4])
#############################################3
torch.Size([2, 3, 1])
tensor([[[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000],
[ 7, 7, 7, 7]],
[[ 1, 1, 1, 1],
[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000]]])
import torch
a=torch.tensor([[[5,5,5,5], [6,6,6,6], [7,7,7,7]], [[1,1,1,1],[2,2,2,2],[3,3,3,3]]])
print(a)
print(a.size())
print("#############################################3")
mask = torch.ByteTensor([[[0]],[[1]]])
print(mask.size())
b = a.masked_fill(mask, value=torch.tensor(-1e9))
print(b)
print(b.size())
#输出
tensor([[[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]],
[[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]]])
torch.Size([2, 3, 4])
#############################################3
torch.Size([2, 1, 1])
tensor([[[ 5, 5, 5, 5],
[ 6, 6, 6, 6],
[ 7, 7, 7, 7]],
[[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000]]])
torch.Size([2, 3, 4])
mask维度和原矩阵维度相同时
import numpy as np
a = torch.randn(5,6)
x = [5,4,3,2,1]
mask = torch.from_numpy(np.triu(torch.ones(5,6),k=1))
print(mask)
a.data.masked_fill_(mask.byte(),-float('inf'))
print(a)
#输出
tensor([[0., 1., 1., 1., 1., 1.],
[0., 0., 1., 1., 1., 1.],
[0., 0., 0., 1., 1., 1.],
[0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 0., 1.]])
tensor([[ 0.6936, -inf, -inf, -inf, -inf, -inf],
[ 1.3120, -1.0768, -inf, -inf, -inf, -inf],
[ 1.0248, -0.7090, 0.8123, -inf, -inf, -inf],
[ 0.6258, -0.6310, -1.7462, 0.4282, -inf, -inf],
[-0.0499, -1.1517, 0.4501, -0.3715, 0.2207, -inf]])
11 torch.scatter()
参考:https://blog.csdn.net/lifeplayer_/article/details/111561685
https://zhuanlan.zhihu.com/p/339043454
scatter(dim, index, src) 的参数有 3 个
dim:沿着哪个维度进行索引
index:用来 scatter 的元素索引
src:用来 scatter 的源元素,可以是一个标量或一个张量
scatter 可以理解成放置元素或者修改元素
dim=0表示按行,即第0个维度

x = torch.rand(2, 5)
print(x)
torch.zeros(3, 5).scatter_(0, torch.tensor([[0, 1, 2, 0, 0], [2, 0, 0, 1, 2]]), x)
#输出
tensor([[0.3902, 0.5160, 0.5764, 0.4354, 0.8828],
[0.1031, 0.9063, 0.1157, 0.0418, 0.3656]])
tensor([[0.3902, 0.9063, 0.1157, 0.4354, 0.8828],
[0.0000, 0.5160, 0.0000, 0.0418, 0.0000],
[0.1031, 0.0000, 0.5764, 0.0000, 0.3656]])

dim=1表示按列,即第一个维度(从第0个维度开始)
src = torch.from_numpy(np.arange(1, 11)).float().view(2, 5)
print("src:",src)
input_tensor = torch.zeros(3, 5)
print("input_tensor:",input_tensor)
index_tensor = torch.tensor([[3, 0, 2, 1, 4], [2, 0, 1, 3, 1]])
dim = 1
input_tensor.scatter_(dim, index_tensor, src)
#输出
src: tensor([[ 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10.]])
input_tensor: tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
tensor([[ 2., 4., 3., 1., 5.],
[ 7., 10., 6., 9., 0.],
[ 0., 0., 0., 0., 0.]])
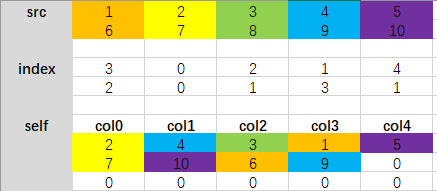
那么,这个scatter函数有什么用呢
该函数最常用的场景是把标量的标签转换为one-hot编码
batch_size = 4
class_num = 5
labels = torch.tensor([4, 0, 1, 2]).unsqueeze(1)
one_hot = torch.zeros(batch_size, class_num)
print("one_hot:",one_hot)
dim=1
index_tensor = labels
src=1
print(dim,src,labels)
one_hot.scatter_(dim, index_tensor, src)
print(one_hot)
#输出
one_hot: tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
1 1 tensor([[4],
[0],
[1],
[2]])
tensor([[0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.]])