戴琼海:深度学习遭遇瓶颈,全脑观测启发下一代AI算法
2020-09-03 02:24:51

作者 | 青暮、陈彩娴
编辑 | 陈彩娴
目前我们还无法精细到神经元级别的观测,只能从功能层面理解大脑,但这些成果也启发了很多经典的人工智能算法,例如卷积神经网络启发自猫脑视觉感受野研究,胶囊网络启发自脑皮层微柱结构研究。在未来,我们能不能深入到神经元的层面研究大脑,是非常重要的一步。
8月29日至30日,主题为“智周万物”的2020年中国人工智能大会(CCAI 2020)在位于江苏南京的新加坡·南京生态科技岛举办。
在大会上,中国工程院院士戴琼海做了主题为《人工智能:算法·算力·交互》的特邀报告,从算力、算法与人机交互三方面展开了分享,指出光电智能计算是未来算力发展的一大候选,深度学习遭遇算力和算法瓶颈,全脑观测对于启发下一代AI算法至关重要,在人机交互的发展中,我们要谨记图灵的教诲,完善AI伦理,并且机器视觉、触觉的协同是一大技术重点。

以下是演讲全文,AI科技评论进行了不改变原意的整理:
1 光电计算推动AI算力飙升
在人工智能发展的时代,特定学科的定义越来越含糊,交叉学科成为机器学习的特点。同时,人类在脑力层面进一步依赖机器,并逐渐把更多大脑思考和不可解析的问题交给机器来执行。这其中也涉及到“力量”的问题。
但是,我们发现,在许多由机器辅助或代替人类处理问题的领域里,如无人系统、量子计算、纳米科技、物联网等,机器的“力量”还不够,原因在于:现有的许多模型和算法还达不到机器学习的需求。
截止今日,人类在算力方面的研究已有半个世纪。
1956年,Rosenblatt发明第一台基于感知机的神经计算机,“Mark 1感知机”,仅包含512个计算单元。这台感知机只能进行初步的数据分类,但无法进行更复杂的算法分类和数据分类,因为算力不够,后者需要用到更复杂的算法。人工智能技术发展的低谷主要来自两方面:一是模型性能差,二是算力不够。算力实际上就体现了软件与硬件应如何结合、发展。
1965年,Gordon Moore建立摩尔定理,提出:集成电路芯片上所集成的晶体管数量,每隔18个月翻一番。为什么每隔18个月就要翻一番呢?这是为了提高算力和算法的可实现性。随后,在1980年,芯片技术出现。这是信息时代最伟大的贡献。计算机芯片加上互联网,专家系统的投入使用成为一个新的里程碑。
到了1999年,英伟达为了提升算力,提出使用 GPU进行并行计算,于是出现首个名义上的GPU:Nvidia GeForce 256,算力为50 GFLOPs。这为算力提升起到关键作用,也实现了人类脑力的迁移。之后,我们可以看到,2012年,Alpha Go使用176个GPU、1202个CPU,在围棋上战胜人类。包括后来2016年,AlexNet性能的提升也得益于GPU,并开启深度学习的黄金时代。

由此可见,算力对人工智能的发展和应用有着关键影响。兴,算力也;亡,算力也。算力的不足,将会导致人工智能的衰落。
在智能医疗、智能制造、无人驾驶和无人系统等领域,我们需要用到的算法和模型越来越复杂。其次,在互联网影视、短视频、网络直播等行业,据调查,流媒体视频占全球互联网下行流量的58%,2019年8月国内互联网终端数量突破20亿,每月超过20亿的注册访问量,每分钟高达500个小时的上传视频。
值得注意的是,随着军事AI的快速发展,军事技术对算力的需求也逐渐增长,然而电子摩尔定律逼近极限,传统芯片瓶颈凸显。举个例子,在中程导弹和远程导弹的研发中,光纤牵引头是一个关键点,用于探路与开路,但由于算力不够,导弹的飞行速度被制约。如果算力能将飞行识别的速度提高到纳秒级、甚至是皮秒级,那么导弹的飞行速度就能提高。
人工智能产业的发展对算力需求呈指数增长,如何从硬件与软件上提高算力,成为国内外科研者的研究热点。算力颠覆性提升、催生新国防武器和新应用也成为国际竞争的一个体现。
最近,MIT的一位计算机科学家Charles Leiserson 在《Science》上发表了一篇文章:《There's plenty of room at the Top: What will drive computer performance after Moore's law?》。他们在研究算力上,就上千篇文章进行了细致的分析,总结出:深度学习正在逼近现有芯片的算力极限;计算能力提高10倍相当于三年的算法改进;算力提高的硬件、环境和金钱成本将无法承受。
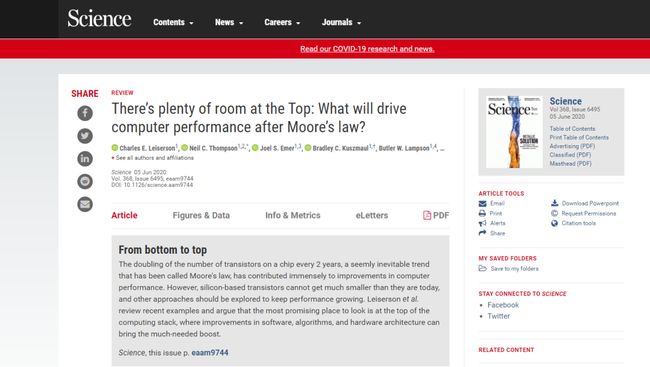
我们对人工智能的期望越来越高,发展AI所承受的压力也很大。据Intel Nvidia OpenAI的调研显示,尽管人工智能对算力的需求快速增长,但算力的提升速度却逐渐放缓:
那么,我们接下来要如何提升算力呢?全世界都在讨论,最后得出:可以通过芯片架构创新,研制神经网络专用芯片,以实现算力的提升,满足人工智能的发展需求。在国内,有地平线、寒武纪等企业专门在做人工智能芯片。Google TPU Array做的则是神经网络的专用芯片。比方说,Alpha Zero便是用了5000个TPU的芯片训练40天,学会下围棋,还拿了国际NO.1。
针对人工智能算力提升的变革,研究人员提出了几个不同的途径,包括:量子计算、存算一体架构、类脑计算和光电智能计算。
1、量子计算:
近年来,谷歌、IBM等名企纷纷看中了量子计算的的指数级计算能力,能够适用于大规模计算场景。但是,搭建量子计算至少要占用100平米的大房子,因为要保证在特定时间段内捕获的量子的相关性要强,而且在持续工作中的稳定性要高。所以,量子计算其实属于特殊的计算应用,对当下,或未来10年、20年的AI算力提升是有难度的。我们希望将算力提升应用到多个方面,而不仅仅是特殊计算。
2、存算一体架构:
存算一体架构使用了忆阻器阵列,存储和计算是一体的,相当于不用先调用内存中的数据再进行计算,因此能大大提升算力。
3、类脑计算:
类脑计算的目的是希望机器能够逼近人脑的计算,这样也能够提升一定的算力。
4、光电智能计算:
如果将光电智能计算和存算一体架构、类脑计算成功结合起来,算力的提升至少能满足未来10年、甚至20年内人工智能对算力的需求。彼时,我们便能证明,人工智能不是泡沫,现有的难题是因为算力技术遇到了瓶颈。

来自普林斯顿大学的电气工程教授Paul Prucnal专门对光计算进行了理论推导,推导的结果是:如果用光计算,算力能提升3个数量级。而且,光计算是不需要耗电的,功耗又能下降6个数量级。有了理论的保障后,研究人员提出做光电计算,有望实现速度千倍提升、效率百万倍提升。

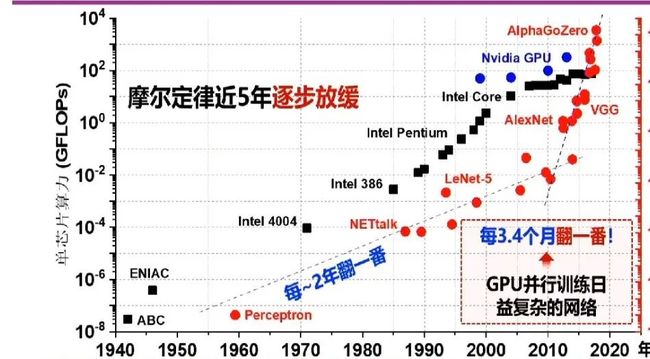
下图为光计算的发展历史。光计算的发展与人工智能的发展路径很相似。光计算的发展可谓“一波三折”:1956年,激光器发明,光计算机被提出,信息光学开始飞速发展。但上世纪60年代之后,光计算研究开始走下坡,原因是当时计算机不需要那么高的算力,电子计算所提供的算力已足够使用。随后,在1990年,贝尔实验室采用砷化镓光学材料研制出“光计算机原型系统”,但此时光计算只充当开关,不参与计算。2007年,英伟达的GPU快速发展,又冲击了光计算领域的研究,直到2017年之后,光神经网络的片上集成实现,光计算才开始突飞猛进。
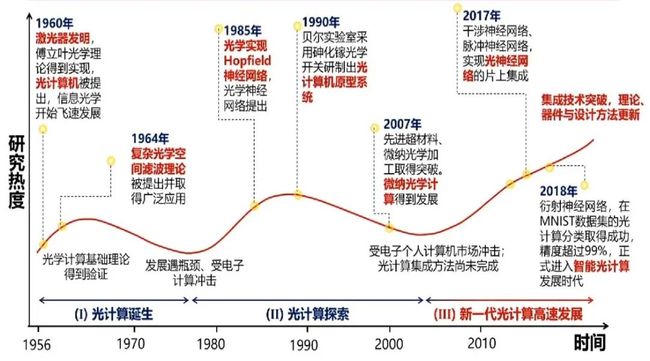
与人工智能相比,光计算的腾飞滞后近10年,主要原因为:人工智能一开始不需要太大的算力,但2017年之后,人工智能对算力的需求提升,光计算便迅速得到发展。
在未来,研究人员希望通过可控高维光场传播,来实现高速高效的并行计算,主要措施如下:
1、三维受控衍射传播实现全并行光速计算;
2、全相位调制99%通关率带来极低损耗;
3、高维光场信号带来前所未有的通量带宽;
4、感存算一体结合超材料实现小型化。
光学作为新的计算必然带来显著的变革,比方说:1、范式颠覆传统:采集与计算无缝衔接,突破存算分离速度制约;2、速度提升至少千倍:计算频次>1 THz,远超~GHz电子芯片频率;3、功能降低百万倍:光学10^7 GMAC/W/s,电子10GMAC/W/s。
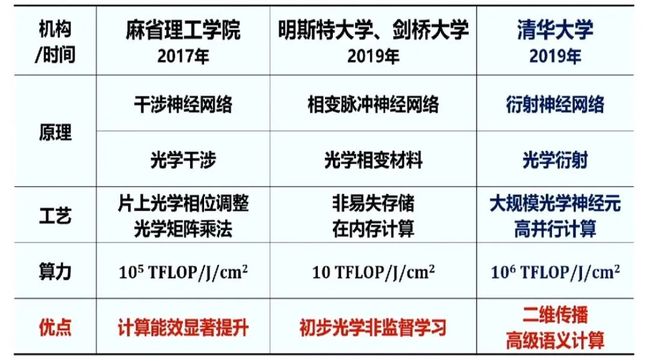
目前,在全球范围内,有三个重要的机构在进行光电智能计算的研究,分别是麻省理工学院、明斯特大学和剑桥大学、清华大学。对比如下:
光电计算发展起来后,研制超小型智能武器、智能仿生机器人、微型修理机器人和光电计算自动驾驶便容易得多。若光电计算发展得好,云计算的服务器功耗也会大大下降,光电计算自动驾驶的速度可以不断提升。
此外,光电智能芯片也能满足庞大的计算中心小型化,大规模存储云计算的小型化可以做到纳秒级目标感知与识别,能够应用于各类无人系统。不仅如此,光电智能芯片也能应用于新基建,如工业互联网、计算机视觉、大数据分析,光通讯等。
算力的提升,也意味着我们将突破人工智能的现有制约。
2 全脑观测启发下一代AI算法
人工智能的新热潮紧随深度学习的崛起之后,这也是归功于算法的发展:

目前,人工智能的算法在鲁棒性、迁移性、能效比、自适应和解释性等方面仍存在一定的缺陷。
1、鲁棒性差
比方说,我们在检测汽车时使用深度学习算法,汽车的后视镜亮起尾灯,我们可以通过提升亮度来检测汽车,但检测失败。输入的小变化引起输出的大变化,鲁棒性较差。
2、迁移性差
深度学习依赖大规模数据集,并且在这些数据集里面,通常极端场景不足,在特殊场景和新场景的迁移性比较差。
3、能效比低
人脑的正常功耗在20瓦左右,而英伟达的V100 GPU的功耗大概在250瓦到300瓦,其功耗相比人脑还是很大的,因此相对生物神经网络,现有计算硬件的能效比更低。
4、自适应性差
深度学习模型在自适应方面很差,比如诊断模型,如果在训练过程中未见过相应的数据,就不能对不同体质、不同病史的人进行诊断。
5、可解释性差
深度学习网络是个黑箱,虽然有明显的效果,但是无法理解产生这些效果的原因。
所以正如获得了2018年图灵奖的三位科学家所说,深度学习缺乏鲁棒性,不具备学习因果关系的能力,缺乏可解释性,而人类在无监督学习方面远远优于深度学习。因此我们要思考如何做算法创新。
现有的人工智能仅实现了简单的初级视觉感知功能,在初级感知信息处理与高级认知过程上的性能远不如人脑,人脑具有物理学习和数据抽象能力。Hinton、LeCun等认为,深度学习存在极大危机,BP算法有很大局限性,需要推倒重来,再次从大脑的认知模型中寻找灵感。
所以我们还要从神经科学中借鉴很多知识和原理,比如多模数据表示、变换和学习规律,以及反馈方式,认知计算将推动人工智能的变革,从而实现高效、可解释、鲁棒的新一代认知智能。
深度学习的来源实际上是优化控制论,BP算法即反向传播算法是深度学习中使用最广泛的算法,它最早的雏形出现在“最优控制理论”,1986年Rumelhart、Hinton等人将BP算法引入多重神经网络中。现在,包括卷积神经网络、语言和注意力模型、生成对抗网络以及深度强化学习,都应用了该算法。
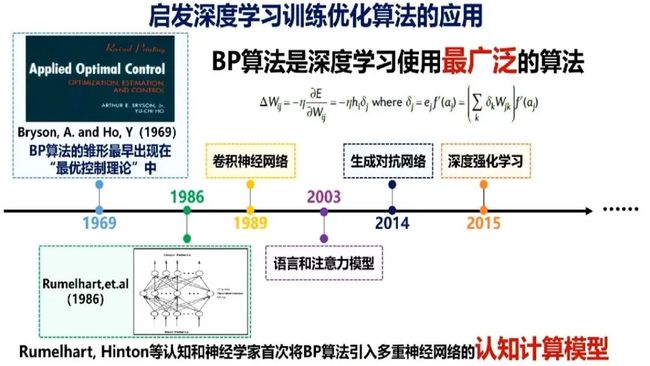
此外,我们怎么从意识方面讨论算法问题呢?以前的做法是从神经科学里获得启发。
比如,在卷积神经网络的发现过程中,科学家先是发现了简单和复杂细胞,并发现视觉系统的卷积特性,然后人们提出借鉴简单复杂细胞的新认知机,这是CNN的前身。1982年,David Marr出版了计算机视觉开山之作《视觉》,之后,卷积神经网络被正式提出。Tomaso Poggio在2007年提出了H-MAX计算模型,2012年的AlexNet和2015年的ResNet则正式开启人工智能的黄金时代。回顾历史后,我们可以想到,如果再反过头来重新认识脑科学,会不会给深度学习带来新的启发?

不仅仅是算法,人们也在硬件上按照类脑计算的方向探索。1989年,科学家首次提出用集成电路实现神经形态计算,到最近,清华大学发布首款结合深度学习与神经形态计算的异构融合类脑芯片,以及基于多个忆阻器阵列的存算一体系统,我们已经向前迈出了一大步。

我们以前通过核磁共振、CT等技术来观测大脑。目前我们还无法精细到神经元级别的观测,只能从功能层面理解大脑,但这些成果也启发了很多经典的人工智能算法,例如卷积神经网络启发自猫脑视觉感受野研究,胶囊网络启发自脑皮层微柱结构研究。在未来,我们能不能深入到神经元的层面研究大脑,是非常重要的一步。总之,利用脑观测成果启发人工智能理论应该还大有可为。
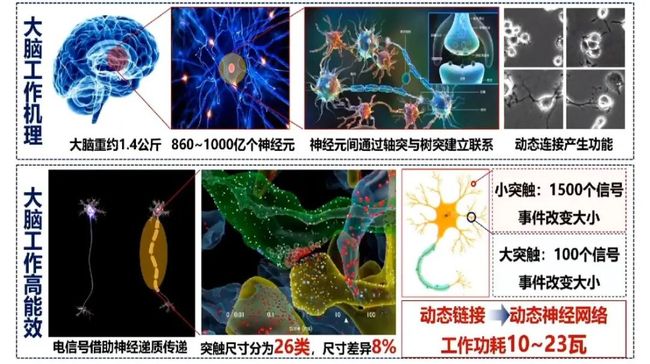
神经元通过轴突和树突建立和其他神经元的关系,人脑有860亿个神经元。神经元要通过构建环路进行工作,工作一结束环路就断掉了。神经元通过从不同的环路解决不同的问题,包括记忆。神经元的动态连接构成动态神经网络,这也可能是其功耗低的原因。突触的尺寸有26类,神经元细胞的尺寸在10微米左右,现在用核磁共振还观察不到轴突和树突,因此研究介观尺度对于脑科学的突破尤为重要。
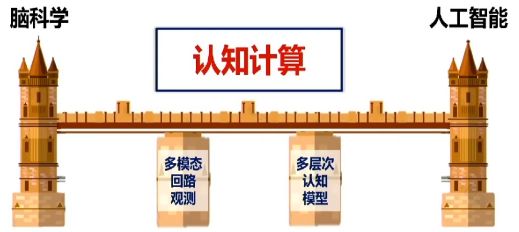
近年来,脑科学和人工智能是两条平行线,互不相交。在未来,我们需要在两者之间构建一个桥梁,即认知计算。认知计算是通过先进神经技术揭示脑结构、脑功能与智能产生的多层次关联与多模态映射机制,从而建立认知模型与类脑智能体系的科学。
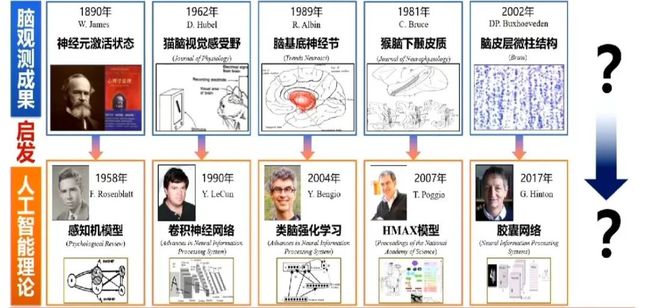
我们对1906年来脑科学和人工智能的重要成果进行了调研,这些研究分别探索了人类的思考模式以及机器的思考模式。

为了建立新型认知计算模型,人类已经开始了大量投入。2016年,美国IARPA部门启动了皮质网络机器智能MICrONS计划,项目经费达到一亿美金,被称为阿波罗脑计划。并且,人类目前已经绘制出了啮齿动物一立方毫米大脑皮层中的所有神经回路,其中包含了10万个神经元的活动和连接。

以记忆机制为例,目前人类已经在该研究领域有了很大建树。自1904科学家首次提出记忆痕迹假设,1949年提出突触可塑性假说以来,人们接连发现,海马体和记忆形成有关,LTP是学习记忆的重要机制,工作记忆和不同脑区有关,尖波涟漪在记忆巩固、回放、预演、提取中有重要作用,并观察到了记忆在多个脑区的动态协同过程。
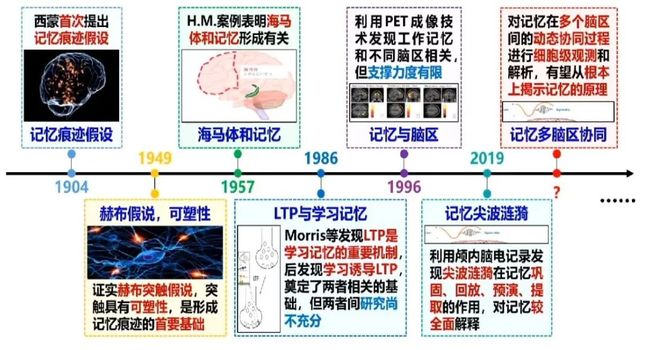
清华大学通过三年的努力,构建了一个大脑的模型架构,如下图所示。

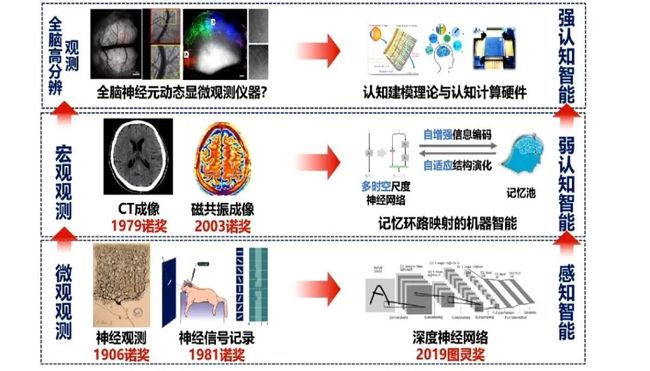
结构决定功能,从结构到功能研究机器学习的算法,人工智能要从这个方向上打通。从不同规模和精细度的脑观测技术,可以启发出不同级别的智能算法。比如神经观测和神经信号记录属于微观观测,启发了卷积神经网络算法。CT成像和磁共振成像属于宏观观测,启发了记忆环路映射的机器智能。在未来,我们或许可以利用全脑神经元动态显微观测仪器对大脑进行全脑高分辨观测,进而发展认知建模理论和开发认知计算硬件,从而实现强人工智能。
这是知识驱动模型的研究模式,另外还有数据驱动的研究模式,这是当前的主流。我们想问的是,未来能不能实现认知驱动?我希望人工智能学界关注和研究这个问题,从而产生颠覆性的算法和应用,推动算力、算法往前走。
3 人机交互:协同视觉和触觉
图灵说过,人工智能的发展不是把人变为机器,也不是把机器变成人,而是“研究、开发用于模拟、延伸和扩展人类智慧能力的理论、方法、技术及应用系统,从而解决复杂问题的技术科学并服务于人类。所以,我们要思考人工智能与人如何共处的问题。
在人工智能时代,我们希望构建AI的通用接口,从而实现人类物理世界和机器虚拟世界的融合,也就是促进AR、VR、视觉三维重建、全息成像等技术的成熟。
目前的人工智能技术可以称为离身学习,其组成三要素为大数据、深度学习和GPU,并形成了图像识别、图像检测、语义理解、语音识别和机器翻译等应用。这些应用割裂了感知、学习与动作之间的整体行为效应,所以未来的发展方向应该是具身认知和多模态感知,即智能由脑、身体与环境协同影响,智能的发展需要一个完整的、可感知、、可思考、可行动的身体。目前的机械手在功能和灵活性上就远远不如人类。
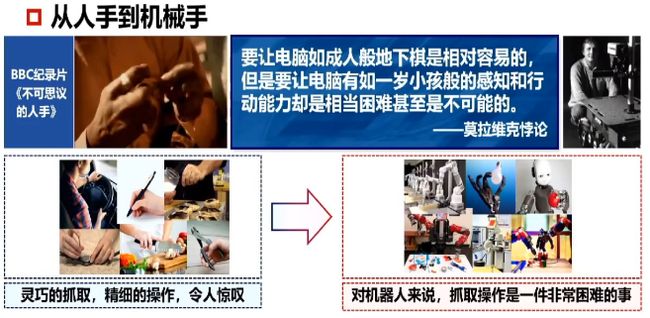
要实现成功的操作,需要考虑三大重要因素,即感知、学习和多模态。
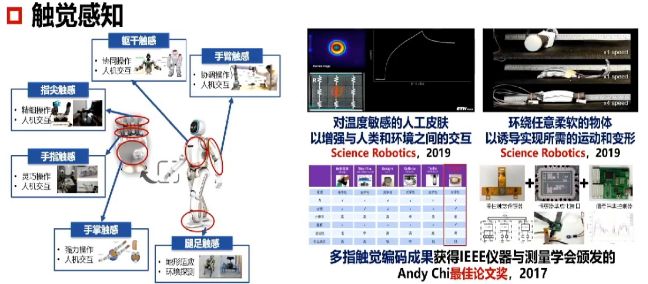
要利用视觉和触觉的多模态融合实现 AI对环境的感知、学习能力和复杂交互能力的提升,首先要让AI拥有皮肤。人手具有上百亿个触感神经元,人体的动态触觉可以区分不超过十几纳米的凸起,相当于在地球上感知到一辆运动的汽车。
机器人必须具备包裹自己全身的人造皮肤,形成个体边界,人造皮肤要有很高的多模态(光洁度、湿度、压力、张力、温度、材质)感知精度,以及很强的综合感知能力,皮肤受损后能闭合自愈,才谈得上区分“我”和“非我”。人工制造出这样敏感的电子皮肤或者量子皮肤,任重而道远。
触觉感知是一个非常难的问题,也是非常重要的问题。在国际上,欧盟、美国、学术界都开展了这方面的研究,机器人、触觉智能引起广泛关注和高度重视。
触觉先于视觉,也先于语言,既是第一语言也是最后语言,所以触觉在AI感知自然场景当中起到非常重要的作用。视觉可以帮助我们了解全貌,触觉可以帮助我们了解细节。AI触觉和视觉的协同感知是未来人工智能的核心关键基础问题。
触觉涉及很多细节,包括指尖、手掌、腿足、手臂、躯干等等方面,因此触觉传感器是机器人的核心部件。《科技日报》曾经报道了35个卡脖子的问题,触觉是其中一个。
发挥多智能体的群体效应,也是未来发展的重要研究方向,包括群体的协同和交互问题。群体协同交互是构筑智能通天塔的必由之路,也是有望挑战莫拉维克悖论的途径。
所以,我们希望机器有更灵巧的手、更明亮的眼睛、更灵敏的耳朵,对环境能够更加深刻的认识,通过智能光电芯片、知识驱动、数据驱动、认知驱动,使得未来的AI能够发展得更好。
总结来说,我们希望在算力上,能得到数量级性能提升的新型计算范式和芯片架构;在算法上,能更接近本源的认知计算理论与方法,在人机交互上,能实现更高的工作效率、生活质量和安全保障。