知识抽取-关系抽取之Bootstrapping:快速构建大规模知识图谱利器
CHANGELOG
- 5/5/2021,新增 Neural Snowball 方法
- 7/15/2020,细致梳理知识抽取体系和信息抽取体系
- 7/2/2020,Snowball 方法新增 pattern 置信度计算公式 RlogF 解析
- 5/10/2020,初次发表。
前言
知识抽取是知识图谱构建的前置步骤,其中,关系抽取是建立图谱中实体关联的必经之路。而今,学术界往往倾向于结合最新的深度学习技术探索关系抽取效果的边界。然而,在工业界中,低成本高效的 Bootstrapping 方法往往也能达到令人满意的效果。本文将和各位读者一起,溯本还原,一探“老而弥坚”的 Bootstrapping 方法的前世今生。
目录
- 导言
- 相关工作
- Dipre
- Snowball
- Neural Snowball
- 总结
1. 导言
1.1. 知识抽取
知识抽取(Knowledge Extraction)的目标是从结构化(关系数据库,XML)数据和非结构化(文本,文档,图像)数据中抽取知识。 尽管知识抽取在方法上类似于信息抽取(NLP)和ETL(数据仓库),但它的抽取结果不仅限于结构化信息的生成或关系数据库 schema 的转换。 知识抽取还需要复用已有的知识表示(本体等)或基于源数据生成 schema [1]。
知识抽取任务总览[2]:
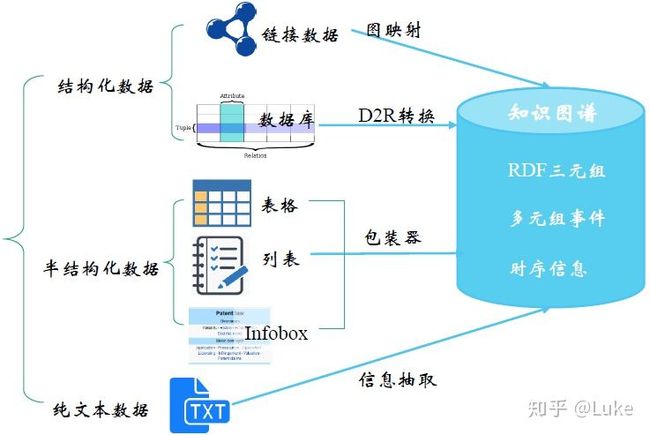
图1.1: 知识抽取总览
不难发现,结构化数据和半结构化数据的抽取瓶颈主要在数据获取上。与之相反,如今的互联网上有海量的纯文本数据,从中获取知识的难点在于信息抽取技术。
这里简单介绍下信息抽取(Information Extraction),该技术的目标是从非结构化数据中抽取出结构化的信息[3],其最重要/最受关注三个的子任务是[2]:

图1.2: 信息抽取主要任务
本文将聚焦于作用在纯文本数据的信息抽取技术。
1.2. 关系抽取
作为信息抽取的主要任务之一,关系抽取需要从文本中抽取两个或多个实体之间的语义关系,主要方法有下面几类[2]:

图1.3: 关系抽取主要方法
本文将主要探究半监督学习关系抽取方法中的Bootstrapping方法。
2. 相关工作
半监督学习主要是利用少量的标注信息进行学习,这方面的工作主要有远程监督方法(distance supervision)以及基于 Bootstrapping 的方法。远程监督方法主要是对知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。传统的 Bootstrapping 的方法主要是利用少量实例作为初始种子(seed tuples)集合,然后进行学习得到新的pattern,进而基于新老pattern抽取新的tuples并扩充种子集合,通过不断迭代从非结构化数据中寻找和发现新的潜在关系三元组。现代基于深度学习的 Bootstrapping 的方法则更多地体现“自扩张”的思想,着重于把数据像“滚雪球”一样扩充的过程,具体实体方法已经和传统方法有了较大变化。
2.1. 研究进展
- Brin[4]等人通过少量的实例学习种子模板,从网络上大量非结构化文本中抽取新的实例,同时学习新的抽取模板,其主要贡献是构建了DIPRE系统;
- Agichtein[5]在Brin的基础上对新抽取的实例进行可信度的评分和完善关系描述的模式,设计实现了Snowball抽取系统;
- 此后的一些系统都沿着 Bootstrapping 的方法,但会加入更合理的对pattern描述、更加合理的限制条件和评分策略,或者基于先前系统抽取结果上构建大规模pattern;如 NELL (Never-Ending Language Learner) 系统[6][7],NELL初始化一个本体和种子 pattern,从大规模的 Web 文本中学习,通过对学习到的内容进行打分来提高准确率,目前已经获得了 280 万个事实。
- ……
3. DIPRE: Dual Iterative Pattern Expansion[4]
DIPRE是从HTML文档集合中提取结构化关系(或表格)的一种方法。 该方法在类似Web的环境下效果最好,其中的表格要提取的tuples往往会在反复出现在集合文档中一致的context内。 DIPRE利用这种集合冗余和内在的结构以提取目标关系并简化训练。
3.1. DIPRE Pipeline
DIPRE pattern由5-tuple
伪代码[2]:
收集具有关系R的一组种子tuples
迭代:
1.找到包含这些种子tuples的句子
2.查看种子tuples之间或周围的上下文,并泛化该上下文以生成patterns
3.用这些patterns找到更多种子tuples3.2 DIPRE样例

图3.1: DIPRE样例
从 5 个种子 tuples 开始,找到包含种子的实例,替换关键词,形成 pattern,迭代匹配,就为 (author, book) 抽取到了 relation pattern, x, by y, 和 x, one of y’s[2]。
3.3 DIPRE利弊
优点:
- 能够从非结构化文本中抽取出结构化的关系
- 训练成本低,每个新场景只需要少量种子tuples。
缺点:
- 依赖 HTML 标签
- 缺少对新 pattern 和 tuples 的评估
- 抽取结果噪声较多
- 抽取结果 Recall 较低
4. Snowball[5]
Snowball提出了一种从文本文档生成 patterns 并提取 tuples 的新技术。此外,Snowball还介绍了一种用于评估在提取过程的每次迭代中生成的 patterns 和 tuples 的质量的策略。 Snowball只会保留被认为“足够可靠”的 tuples 和 patterns 用于系统迭代。这些新的 patterns和 tuples 生成和过滤策略可以显着提高提取表格的质量。
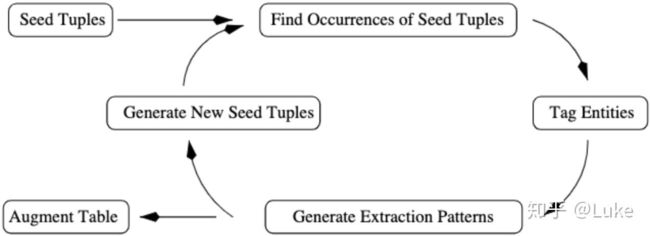
图4.1: Snowball流程
4.1. 生成Patterns
表格提取过程中的关键步骤是生成用于在文档中查找新 tuples 的 patterns。
开始阶段,Snowball给定一些种子 tuples, e.g. <o, l>。就像DIPRE一样,Snowball会在文档集合中查找 o 和 l 彼此靠近的文本段,并分析“连接” o 和 l 的文本并生成patterns。与DIPRE方法相比,Snowball的主要改进之处在于,Snowball的 patterns 包括命名实体标签。

图4.2: 利用命名实体标签的patterns
定义1 Snowball的 pattern 表示为一个5-tuple
E.g. <{<the, 0.2>}, LOCATION, {<-, 0.5>, <based, 0.5>}, ORGANIZATION, {}>。此 pattern 将匹配 “the Irving- based Exxon Corporation” 之类的字符串,其中单词“ the” (left context) 在位置(Irving)之前,其后依次是字符串“-”和“ based” (middle context ) 和organization。
在字符串 S 中识别了两个实体后,Snowball通过分别分析命名实体周围的left,right和middle context,创建了三个权重向量 Ls , 和 。每个向量对出现在各自 context 中的每个单词具有非零权重,其中, 和 被限制在实体对的左侧和右侧的 单词长度的窗口内。每个向量中的单词权重是相应 context 中单词频率的函数。这些向量会被归一化。最后,将它们乘以缩放因子以表明每个向量的相对重要性。通过对英语文档的实验,我们发现middle context对tuple 元素之间关系的最有指示性。因此,我们通常会在 middle 向量中分配比 left 向量和 right 向量更高的权重。提取字符串 S 的 5-tuple 表示后,Snowball通过取相应left,right和middle 向量的内积将其与5-tuple pattern进行匹配。
定义2 两个5-tuples  (带有标签t1和t2 )和 (带有标签 )之间的的匹配度 定义为:
(带有标签t1和t2 )和 (带有标签 )之间的的匹配度 定义为: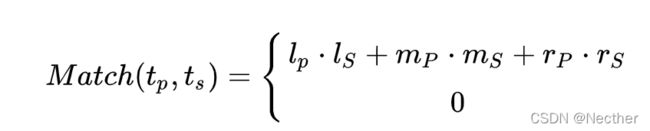
如果 tuples 周围的 context “足够相似”,则为了生成 pattern,Snowball将文档中已知元组的出现 group 起来。具体而言,Snowball为每个包含种子 tuple 的字符串生成一个5-tuple,然后用简单的 single-pass 聚类算法[8]使用上面定义的 Match 函数计算这些 5-tuples 之间的相似度和最小相似性阈值 Tsim ,进而对这些 5-tuples 做聚类。5-tuples 簇中的 left 向量由 centroid 表示。同样,我们将它们的中间 middle 和 right 向量分别表示为。这三个 centroid 与原始标签(对于 cluster 中的所有5-tuples都相同)一起形成了Snowball pattern 。
4.2. 生成Tuples
生成patterns之后(节4.1),Snowball扫描集合发现新 tuples,具体的使用patterns抽取新tuples的伪代码如下所示:

4.3. 评估Patterns和Tuples
生成好的 patterns 很难,差的 patterns 会生成很多噪声 tuples。
估算 patterns 的置信度来帮助我们甄别易于生成错误tuples的patterns,这是我们在本节中要解决的问题之一。我们可以根据其 selectivity 对 Snowball patterns加权,并作用到它们生成的tuples上。因此,不 selectivity 的 pattern 权重较低,其生成的tuples 将被丢弃。
我们只保留置信度高的 tuples。Tuples的置信度是其 selectivity 和生成它的 patterns 数量的函数。直观地讲,如果 tuples 是由几个高 selectivity 的 patterns 生成的,那么它的置信度就会很高。
Pattern 和 tuple 评估是我们系统的关键部分,它是对DIPRE方案的重大改进。作为初始filter,我们消除了所有少于 Tsup 个种子 tuples 支持的 patterns。然后,我们在图5中的算法的步骤(3)中更新每个 pattern 的置信度,该算法检查由当前 pattern 生成的每个候选 tuple 。原生Snowball只支持 single-attribute key 的方式估算关系 patterns 的置信度。
定义3 Pattern P 置信度计算公式: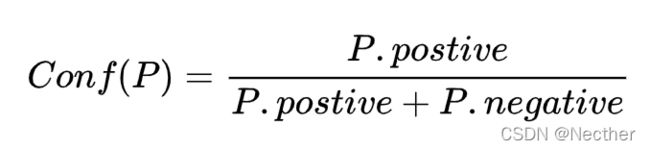
其中,  为 P 正确抽取种子集中tuple的个数, 为 P 错误抽取种子集中tuple的个数。
为 P 正确抽取种子集中tuple的个数, 为 P 错误抽取种子集中tuple的个数。
例如,考虑 pattern P = <{}, ORGANIZATION, <“,”, 1>, LOCATION, {}> 。假定此 pattern 仅与下面的三行文本匹配:
“ Exxon, Irving, said”
“ Intel, Santa Clara, cut prices”
“invest in Microsoft, New York-based analyst Jane Smith said”
易得,前2个字符串为positive,第3个字符串为negative,所以 pattern P 的置信度 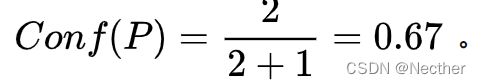 。
。
另外一种常用 pattern 置信度计算公式是 RlogF ,该方法同时考虑了 pattern 的 coverage 和 selectivity。
定义4 Pattern P 的 RlogF 置信度计算公式
由于 pattern 的置信度定义在[0,1]之间,所以对于 ,采用除以所有 pattern 中最大的置信度值进行归一化。直观上看,RlogF 是一种加权置信度,pattern 抽取越准确, 部分分值越高,即 selectivity 好;pattern 抽取的正确结果越多, 部分分值越高,即 coverage 好[9]。
迭代过程中,pattern置信度的更新公式为:
其中,Confnew(p) 为更新后置信度, 为上一轮迭代置信度, Conf(p) 为本轮迭代置信度, Wupdt 为学习率。

表4.1: Snowball挖掘出的实际patterns样例
对 patterns 进行评分后,我们现在可以评估新的候选 tuples。
定义5 候选tuple T 置信度计算公式:

其中, p = {pi} 是生成 T 的一组 patterns, 是出现 T 且具有匹配度 的context。
Snowball会丢弃置信度低的候选 tuples。
4.4. 实验
Baseline方法只依赖 tuple 中元素同时出现的频率。

图4.3:Snowball 实验效果对比
Snowball 和 DIPRE 的 precision 都明显高于 Baseline。实际上,Baseline倾向于生成许多 tuples,从而在低 precision 的代价下产生较高的 recall。Snowball的 recall至少与大多数实验的 Baseline 一样高,且 precision 更高。Snowball 的 recall 通常高于DIPRE的 recall, precision 则二者相近。
5. Neural Snowball[10]
二十年过去了,随着互联网数据的爆炸式增长,上文中的 DIPRE 和 Snowball 方法已经力不从心。另一方面,2012年后基于深度学习的方法逐渐成为NLP的主流。那么,经典的 Bootstrapping 方法又做了哪些与时俱进的修改呢?Neural Snowball 给出了自己的答案。
我们知道,主流的关系抽取方法聚焦于具有充足训练数据的预定义关系,然而现实世界中却存在很多还没有被定义的新关系。因此,作者提出 Neural Snowball 方法尝试识别只有少量已知样本的新关系。该方法希望通过迁移已有关系上的语义知识来学习新关系,如图5.1所示。简单来说,Neural Snowball 使用关系孪生网络(Relational Siamese Networks, RSN)基于已有关系及其标注数据去学习实例(instance)之间的关系相似度度量。随后,给定新关系及其少量标注样本,用 RSN 来从无标注语料中积累可靠的实例,这些 instance 被用来训练一个可以进一步识别新关系的新事实(fact)的关系分类器。以上过程会不断的迭代进行。

图5.1: Neural Snowball 基本思想
可以看到,相较 DIPRE 以及 Snowball 等传统 Bootstrapping 方法,Neural Snowball 有两点显著不同:
- Neural Snowball 的整体框架基于深度语义模型实现,而前两者均是以显示的 pattern 模板为载体,这意味着 Neural Snowball 的表达能力更强,能够处理更复杂的关系。
- 前两者仅仅使用了种子关系事实,而 Neural Snowball 则将大规模标注数据集也同时利用了起来。Nerual Snowball 的作者认为,尽管已有关系同新关系的分布可能存在明显差异,但深度学习模型依旧可以提取出高层级的抽像特征来表征未知关系。
5.1. 术语及问题定义
- 实例 x :
- 关系事实:(eh,r,et) 三元组。
- 种子集Sr :新关系 的实例集合
- 大规模标注数据Sn :N个预定义关系的标注实例集合
5.2. Neural Snowball 过程
Neural Snowball 的整体框架如图5.2所示,每轮迭代可以按照图中的红色竖线分隔为 Phase 1 和 Phase 2 两个阶段。初始阶段,每个新关系 r 需要提供一个小的种子集 作为输入。在随后的每次迭代中,会被选中的无标注实例扩充,而新的会作为下一轮迭代的输入。
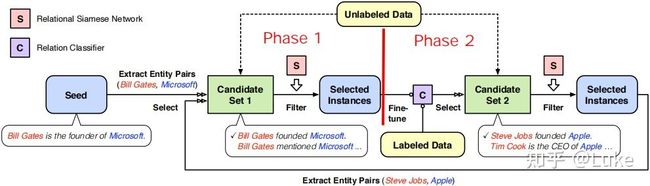
图5.2: Neural Snowball 框架
Phase 1 的目标是通过将种子集 Sr 中已有的实体对对齐无标注语料库 来扩展Sr。具体实现上,首先提取出种子集上所有的头尾实体对 ,然后在上匹配出所有包含的上下文 ,进而将 作为实例聚合成图中的 Candidate Set 。直观上看,如果不同实例间共享了同一个实体对,它们就有可能表达同一个关系 。但为了进一步减少假正例,对于每个实例 ,找到种子集中所有同 共享 的实例 ,接着用 RSN 计算 同所有 之间的相似度后取平均得到 。最后,基于做倒排+阈值过滤,将保留的高置信实例加入。
Phase 2 的目标是为关系 r 发掘新的实体对。具体实现上,首先基于 Phase 1 扩展的种子集 Sr fine-tune 关系分类器 ,然后用 在无标注预料库 上做预测,再使用阈值 过滤出高置信预测结果作为 Candidate Set 。接着,对于每个实例 ,使用 RSN 计算其与所有的 之间的相似度后取平均得到 。最后,基于做倒排+阈值过滤,将保留的高置信实例加入。
每轮迭代结束后,系统会回到 Phase 1 开启新一轮的迭代。几轮迭代后,种子集 Sr 会不断增大,分类器的效果也会不断改善直到达到峰值。
5.3. Neural 模块
通过5.2节内容不难发现,Neural Snowball 有两个关键模块:
- 关系孪生网络(Relational Siamese Network ,RSN),通过衡量候选实例与已有实例之间的相似度来从无标注数据中选择高质实例。
- 关系分类器,识别实例是否属于新关系。
关系孪生网络(Relational Siamese Network ,RSN)的输入是两个实例,输出是一个值域为 [0,1] 的实数,该值表明2个实例共享同一个关系类型的概率。图5.3展示了 RSN 的模型结构:2个共享参数的编码器 加一个距离函数。编码器为每个输入实例输出表示向量,然后用下面的公式计算2个实例间的相似度得分:
![]()
其中,用向量每个维度的差方来代替向量点积, 表示 sigmoid 函数。这个距离函数可以被当作是一个带有可训练的权重 和偏置 的加权 L2 距离。分数越高则两个实例表达相同关系的概率越大。

图5.3: RSN 模型结构
关系分类器 g(x) 由一个 neural 编码器和一个线性层组成。值得注意的是,Neural Snowball 选择为每种关系训练一个二元关系分类器,而不是将所有关系组织成一个多分类问题。至于这么做的原因,作者由如下3个观点:
- 多分类将不属于已知关系的实例都归为“na”不合适。
- 二元分类器新增关系更容易,而多分类器增加一个新关系需要重训模型,同时也要小心数据不平衡问题。
- 多个二元分类器允许一个实例属于多种关系(EPO),而多分类器认为一个实例只能属于一种关系。
出于工业界应用的考虑,笔者与作者持有些许不同意见:
- 多元二分类器需要为每个分类器单独构造负例,费时费力;而多分类器中,不同的关系可以互相作为负例(E.g. 父母 <-> 子女),效果可能会更好。
- EPO确实是多元二分类相较于多分类器最大的优势,但究竟我们自己任务上存在多少EPO,需要自行摸底,盲目追求多标签分类不一定是最优解。
- 多个二元分类器会带来额外的部署调度成本,原来只需要一个模型的算力,现在可能要 x N,因此性能敏感的应用场景可能要慎重考虑。
预训练和微调将从已标注关系数据集 Sn 上学到的高层级抽象知识快速迁移到新关系上。对于关系分类器,基于做多分类任务来预训练分类器的隐藏层表示。对于 RSN,随机采样具有相同关系和不同关系的实体对并用交叉熵损失来训练模型。
对于一个新关系 r 及其种子集 ,固定 RSN 的所有参数和关系分类器的 encoder 参数。随后,通过从 和 中分别采样正例 batch 和负例 batch 来优化关系分类器的线性层参数,损失函数如下:

其中 μ 是负采样损失的系数。这是由于实际训练的时候,负例和数量远远多于正例,所以要给负例损失一个更小的权重。具体微调的伪代码如下所示:

5.4. 实验
少样本关系学习,表5.1展示 Neural Snowball 的对比实验。可以看到:
- Neural Snowball 的所有设置及所有编码器都获得了最佳效果。
- Fine-tuning, distant supervision 及 Neural Snowball 3种方法的效果都能随着种子数的增加而有所改进,而 BERDS 和 RSN 的变化很小。

表5.1:少样本关系学习实验结果
进一步分析可以发现,Neural Snowball 的 precision 和 recall 都比较高,这意味着 Neural Snowball 不仅找到了新的高质训练实例,而且成功地提取出了新关系事实和能拓展新关系覆盖的模式。
RSN分析,如表5.2所示,尽管新关系只提供了5个种子,RSN 依旧取得了相当高的 precision。除此之外,尽管 RSN 只见过训练集数据,但它在测试集上的效果相比之下仅有些许下降,这进一步证明了 RSN 的有效性。

表5.2:5个新关系种子下的RSN Top-N Precision
Neural Snowball 过程分析,为了量化分析 Neural Snowball (NS) 的迭代过程,作者设计了一组对照实验。如图5.4所示,NS setting 指的是用 Neural Snowball 选出的实例微调分类器,而 random setting 指的是用随机选出的与 NS setting 相同数量的实例微调分类器。

图5.4:Neural Snowball 每轮的评测结果
通过观察可得:
- 随着迭代的进行,NS setting 维持着高于 random setting 的 precision,这说明 RSN 成功地提取出了高置信的实例及高质量的模式。
- NS 的 recall 增长低于预期,这意味着 RSN 可能对已有模式存在过拟合。
6. 总结
Bootstrapping 如今在工业界中依旧是快速构建大规模知识图谱的重要方法。在实际使用中,根据不同的应用场景(E.g. 短文本 VS 长文本),考虑结合基于 pattern 的方法与基于深度语义模型的方法,利用多通路在提准确的同时尽可能地保召回。
参考
- ^Knowledge extraction - Wikipedia https://en.wikipedia.org/wiki/Knowledge_extraction
- ^abcde 知识抽取-实体及关系抽取 | 徐阿衡 http://www.shuang0420.com/2018/09/15/%E7%9F%A5%E8%AF%86%E6%8A%BD%E5%8F%96-%E5%AE%9E%E4%BD%93%E5%8F%8A%E5%85%B3%E7%B3%BB%E6%8A%BD%E5%8F%96/
- ^Information extraction - Wikipedia https://en.wikipedia.org/wiki/Information_extraction#Tasks_and_subtasks
- ^abbrin s. Extracting Patterns and relations fromthe World Wide Web[J]. lecture notes in computerScience, 1998, 1590:172-183.
- ^abAgichtein E, Gravano L. Snowball : Extracting relations from large Plain-text collections[c]// acMConference on Digital Libraries. ACM, 2000:85-94.
- ^Carlson A, Betteridge J, Kisiel B, et al. Toward anarchitecture for never-Ending language learning.[c]// twenty-Fourth aaai conference on artificialIntelligence, AAAI 2010, Atlanta, Georgia, Usa, July.DBLP, 2010:529-573.
- ^Mitchell T, Fredkin E. Never-ending Languagelearning[M]// never-Ending language learning.Alphascript Publishing, 2014.
- ^William B. Frakes and Ricardo Baeza-Yates, editors.Infor-mation Retrieval: Data Structures and Algorithms. Prentice-Hall, 1992.
- ^Thelen, Michael, and Ellen Riloff. "A bootstrapping method for learning semantic lexicons using extraction pattern contexts." Proceedings of the 2002 conference on empirical methods in natural language processing (EMNLP 2002). 2002.
- ^Gao, Tianyu, et al. "Neural snowball for few-shot relation learning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.