随机森林的使用
bagging装袋法 通过构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估其的结果。代表模型是随机森林。
重要属性
参数 n_estimators 森林中树木的数量
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
%matplotlib inline
from sklearn.model_selection import train_test_split
wine = load_wine()
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)# 实例化
# 训练集带入实例化后的模型进行训练,使用接口fit
# 使用其他接口将测试集导入我们训练好的模型,去获取我们希望获取的结果(score,Y_test)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c))
print(f"Random Tree:{score_r}")![]()
# 交叉验证:多次训练观察模型稳定性,把数据分成n份,依次取其中的每一份做测试集,剩下的n-1做训练集
# 交叉验证中不需要在分数据集,只需要把完整的模型输入进去就可以
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10)
plt.plot(range(1,11),rfc_s,label="RandomForest")
plt.plot(range(1,11),clf_s,label="DecisionTree")
plt.legend()
plt.show()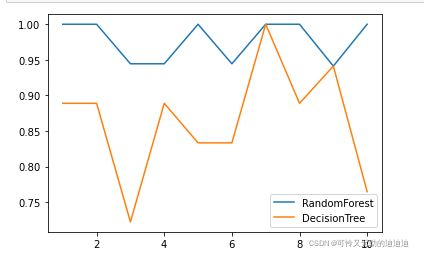
画出随机森林和决策树在十组交叉验证下的效果对比
rfc_l = []
clf_l = []
for i in range(10):
rfc = RandomForestClassifier(n_estimators=25)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
clf = DecisionTreeClassifier()
clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean()
clf_l.append(clf_s)
plt.plot(range(1,11),rfc_l,label="Random Forest")
plt.plot(range(1,11),clf_l,label="Decision Tree")
plt.legend()
plt.show()
# n_estimators的学习曲线
superpa = []
for i in range(100):
rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
superpa.append(rfc_s)
print(max(superpa),superpa.index(max(superpa)))
plt.figure(figsize=[20,5])
plt.plot(range(1,101),superpa)
plt.show()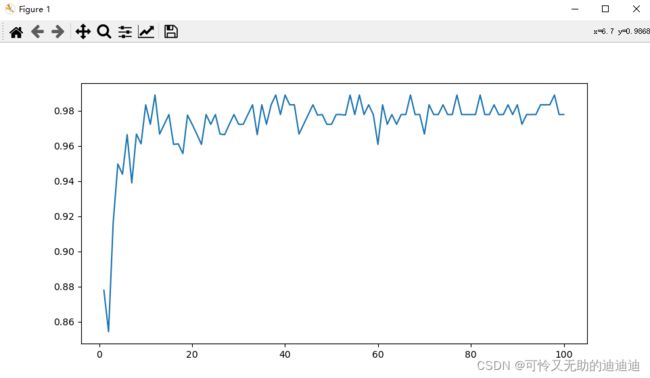 为什么随机森林比一个树计算要准确呢?
为什么随机森林比一个树计算要准确呢?
在上面的25棵树中,要有一半以上的树计(13棵)算错误才会整体的计算错误,假设1棵树计算错误的概率为0.2,那么13棵以上计算错误的概率为 e = ![]()
![]()
![]()
![]()
import numpy as np
from scipy.special import comb
np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i))for i in range(13,26)]).sum() ![]()
rfc.estimators_ 查看树的属性
袋装法有放回的取数据,大概有37%的数据没有取到,可以用这些没有取到的数据变成测试集
如果希望用袋外数据进行测试,把oob_score参数调整为True,训练完毕后,用oob_score_ 来查看袋外数据的结果
rfc = RandomForestClassifier(n_estimators=25,oob_score=True)
rfc = rfc.fit(wine.data,wine.target)
rfc.oob_score_![]()
接口
rfc = RandomForestClassifier(n_estimators=25)
rfc = rfc.fit(Xtrain,Ytrain)
rfc.score(Xtest,Ytest)rfc.feature_importances_# 所有特征当中特征重要性数值

rfc.apply(Xtest)# 返回测试集中的每一个样本在每一棵树中叶子节点的索引

rfc.predict(Xtest)# 返回对测试集预测的标签

rfc.predict_proba(Xtest)# 测试集中每一个样本对应的每一个标签的概率
