什么是基础呢?
就是要把我们大学所学的离散数学,算法与数据结构,操作系统,计算机体系结构,编译原理等课程学好。对计算机的体系,CPU本身,操作系统内核,系统平台,面向对象编程,程序的性能等要有深层次的掌握。要编写出优秀的代码同样要扎实的基础,如果数据结构和算法学的不好,怎么对程序的性能进行优化,怎样从类库中选择合适的数据结构。如果不了解操作系统,怎样能了解这些开发工具的原理,它们都是基于操作系统的。不了解汇编,编译原理,怎么知道程序运行时要多长时间要多少内存,就不能编出高效的代码。把面向对象,软件工程,设计模式这些基础学好了再去看这些就可以以不变应万变。如果自己的基础不扎实,就像在云里雾里行走一样,只能看到眼前,不能看到更远的地方。这些新鲜的技术掩盖了许多底层的原理, 要想真正的学习技术还是走下云端,扎扎实实的把基础知识学好,有了这些基础,要掌握那些新技术也就很容易了。
编程好比盖楼,根基没打好早晚有一天会垮掉的,而且盖的越高,损失也越惨重。这些底层知识和课本不是没有用也不是高深的不能学,而是我们必须掌握的基础。
第一部分 基础知识
第1章 算法在计算中的作用
1.1 算法
所谓算法就是定义良好的计算过程,它取一个或一组值作为输入,并产生出一个或一组值作为输出。
数据结构
本书包含了几种数据结构。数据结构是存储和组织数据的一种方式,以便于对数据进行访问和修改。没有哪一种数据结构可以适用于所有的用途和目的,因而,了解几种数据结构的长处和局限性是相当重要的。
NP完全问题
尽管迄今为止都没有谁能找出NP完全问题的有效解法,但也没有人能够证明NP完全问题的有效解法是不存在的。对NP完全问题有所了解是很有价值的,因为有些NP完全问题会时不时得在实际应用中冒出来。例如,如果要求你找出有关某一NP完全问题的有效算法,你很可能会花费大量时间去探寻,结果却是徒劳无益的。如果你能证明该问题是NP完全的,就可以把时间花在设计一个有效的算法上,该算法可以给出比较好的,但不一定是最佳可能的结果。
是否拥有扎实的算法知识和技术基础,是区分真正熟练的程序员与新手的一项重要特征。利用当代的计算技术,无需了解很多算法方面的东西,也可以完成一些任务。但是,有了良好的算法基础和背景的话,可以做的事就要多得多了。
第2章 算法入门
2.1 插入排序
对少量元素进行排序的有效算法: 工作机理与很多人打牌时,整理手中牌的做法类似:开始摸牌时,左手是空的,牌面朝下放在桌上。接着一次从桌上摸起一张牌,并将其插入左手牌的正确位置上。无论在什么时候,左手中的牌都是排好序的。
原地排序(sorted in place)这些数字就是在该数组中进行重新排列的。
Insertion-sort
for(j = 1; j< A.Length; j++)
{
var key = A[j];
//Insert A[j] into the sorted sequence A[1:j-1]
var i = j - 1;
while(i > 0 and A[i] > key)
{
A[i+1] = A[i];
i - -;
}
A[i+1] = key;
}
2.2 算法分析
插入排序 - O(n^2)
2.3 算法设计
2.3.1 分治法
有很多算法在结构上是递归的:为了解决一个给定的问题,算法要一次或多次地递归调用其自身来解决相关的子问题。这些算法通常采用分治策略:将原问题划分成n个规模较小而结构与原问题相似的子问题;递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治模式在每一层递归上都有三个步骤:
- 分解(Divide): 将原问题分解成一系列子问题;
- 解决 (Conquer):递归地解各子问题。若子问题足够小,则直接求解;
- 合并 (Combine): 将子问题的结果合并成原问题的解。
合并排序(merge sort)算法完全依照了上述模式,直观地操作如下:
- 分解: 将n个元素分成各含n/2个元素的子序列;
- 解决: 用合并排序法对两个子序列递归地排序;
- 合并: 合并两个已排序的子序列以得到排序结果。
MERGE(A,p,q,r)
{
var n1 = q-p+1;
var n2 = r-q;
var L[1:n1+1];
var R[1:n2+1];
for (var i = 1; i < n1; i++)
L[i] = A[p+i-1];
for(var j = 1; j < n2; j++)
R[j] = A[q+j]
i = 1; j = 1;
for (var k = p; k < r; k ++)
{
if(L[i] <= R[j])
{
A[k] = L[i];
i = i+1;
}
else
{
A[k] = R[j];
j = j+1;
}
}
}
运行时间是O(n)
可以将MERGE过程作为合并排序中的一个子程序来使用了:
MERGE-SORT(A, p, r)
{
if(p < r)
{
var q = (p+r)/2;
MERGE-SORT(A, p, q);
MERGE-SORT(A, q+1, r);
MERGE(A, p, q, r);
}
}
运行时间是O(nlogn) - 原因 - 递归树
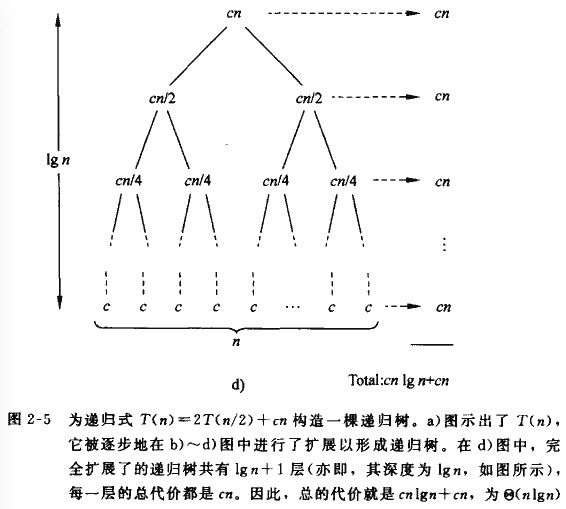
尽管合并排序的最坏情况运行时间为O(nlgn),插入排序的最坏情况运行时间为O(n^2),但插入排序中的常数因子使得它在n较小时,运行得要快一些。因此,在合并排序算法中,当子问题足够小时,采用插入排序就比较合适了。
思考题:
2-3 霍纳规则的正确性?
2-4 逆序对?
第 3 章 函数的增长
O标记。。
第 4 章 递归式
当一个算法包含对自身的递归调用时,其运行时间通常可以用递归式(recurrence)来表示。
本章介绍了三种解递归式的方法:
- 代换法(Substitution method)
- 先猜有某个界存在
- 然后再用数学归纳法证明该猜测的正确性
- 递归树法(Recursion-tree method)
- 将递归式转换成树形结构
- 树中的结点代表在不同递归层次付出的代价
- 最后,再利用对和式限界的技术来解出递归式
- 主方法(master method): T(n) = aT(n/b) + f(n)
- 其中 a>= 1, b >= 1, f(n)是给定的函数
4.1 代换法
用代换法解递归式需要两个步骤:
1)猜测解的形式
2)用数学归纳法找出使解真正有效的常数
做一个好的猜测 - 不幸的是,并不存在通用的方法来猜测递归式的正确解。这种猜测需要经验,有时甚至是创造性的。值得庆幸的是,还有一些试探法可以帮助做出好的猜测。(e.g. 递归树)
4.2 递归树方法
虽然代换法给递归式的解的正确性提供了一种简单的证明方法,到那时有的时候很难得到一个好的猜测。像我们在2.3.2节分析合并排序递归式那样,画出一个递归树是一种得到好猜测的直接方法。
在递归树中,每一个结点都代表递归函数调用集合中一个子问题的代价。我们将树中每一层内的代价相加得到一个每层代价的集合,再将每层的代价相加得到递归是所有层次的总代价。当用递归式表示分治算法的运行时间时,递归树的方法尤其有用。
递归树最适合用来产生好的猜测,然后用代换法加以验证。但使用递归树产生好的猜测时,通常可以容忍小量的“不良量”(sloppiness),因为稍后就会证明所做的猜测。
4.3 主方法
主方法依赖于以下定理:
设a>=1和b>1为常数,设f(n)为一函数,T(n)由递归式
T(n) = aT(n/b) + f(n)
第5章 概率分析和随机算法 (probabilistic analysis & randomized algorithm)
复习概率论基本知识:附录C 计数和概率
回顾初等组合学和概率论:
C1 计数 (排列组合)
C2 (概率公理 和 概率分布)
C3 (随机变量,期望值 和 方差)
C4 (伯努利试验->几何分布和二项分布)
C5 (二项分布 及其尾部特性)
5.1 雇佣问题
问题:雇佣一名新的办公室助理
决策:任何时候,都要找到最佳人选担任这项职务。在面试完每个应聘者后,如果这个应聘者比目前的办公助理更有资格,你就会辞掉目前的办公室助理,然后聘请这个新的应聘者。
算法:
Hire-Assistant(n)
{
var best = 0;
for(int i = 0; i < n.length -1; i++)
{
Interview(n[i]);
if(n[i] better than n[best])
{
best = i;
hire[i];
}
}
}
在雇佣问题中,可以假设应聘者是以随机顺序出现的。但在许多情况下,我们对输入分布知之甚少:
在雇佣问题中,看起来应聘者好像是以随机的顺序出现的,但是我们无法知道这是否正确。因此为了设计雇佣问题的一个随机算法,必须对面试应聘者的次序有更大的控制。所以要稍微改变这个模型:假设雇佣代理有n个应聘者,而且事先给我们一份应聘者的名单,每天我们随机选择其中一个来面试。虽然我们并不了解任何关于应聘者的事项,我们已经做了一个显著的改变:我们控制了应聘者的来到过程且加强了随机次序。
更一般地,如果一个算法的行为不只是由输入决定,同时也由随机数生成器所产生的数值决定,则称这个算法是随机的。
5.1.3: UnbiasedRandom -> call -> BiasedRandom
while(true)
{
var x = BiasedRandom;
var y = BiasedRandom;
if(x != y)
{
return x;
}
}
5.2 指示器随机变量
1-> 如果事件发生
0-> 如果事件没发生
利用指示器随机变量分析雇佣问题
引理:假设应聘者以随机的次序出现,算法Hire-Assistant总的雇佣费用为O(Cln(n))
5.3 随机算法
在上一节中,说明了了解输入的分布是如何有助于分析算法平均情况行为的。但是,许多时候我们无法得到有关输入分布的信息,因而不可能进行平均情况分布。
在这些情况下,可以考虑采用随机算法:
对于诸如雇佣问题之类的问题,假设输入的所有排列都是等可能的往往是有益的。在这样的问题中,我们不是假设输入的一个分布,而是给定一个分布。特别的,在算法运行之前,我们先随机地排列应聘者,以加强所有排列都是等可能的这个特性。
对于雇佣问题,代码中唯一需要改动的地方是随机的排列应聘者数列: randomly permute the list of candidates
凭着这个简单的改变,我们建立了一个随机算法,它的性能和假设应聘者以随机次序出现所得到的结果是一致的。
随机排列数组
许多随机算法通过排列给定的输入数组来使输入随机化。(还有其他使用随机的方式??)
在这里我们讨论两种随机化的方法:
1.为数组的每个元素赋一个随机的优先级,然后依据优先级对数组A中的元素进行排序
Permute-By-Sorting(A)
{
var n = A.length;
for(int i = 0; i < n - 1; i++)
{
P[i] = Random(1,n^3);
}
Sort(A), using P as sort keys
return A;
}
其中第三行取一个1到n^3之间的随机数,是为了让P中的所有优先级尽可能是唯一的。
此过程中耗时的步骤是第四行中的排序,在第八章中将看到,如果使用基于比较的排序,排序将花费O(nlgn)的时间。这个下界可以达到,因为我们已经知道合并排序的时间代价为O(nlgn)
用这种方式我们得到了一个排序,但是还有待于进一步证明的是这个过程能产生均匀的随机排列==数字1到n的每一种排列都是等可能被产生的。
有人可能会有这样的想法:即要证明一个排列是均匀随机排列,只要证明对于每个元素,其处于每个位置的概率是1/n就足够了。(练习5.3.4证明这个弱条件实际上是不充分的)
2.产生随机排列的一个更好的办法是原地排列给定的数列。程序在O(n)时间内完成,在第i次迭代时,元素A[i]是从元素A[i]到A[n]中随机选取的。
Randomize-In-Place(A)
{
var n = A.length;
for(int i = 0; i < n-1; i++)
{
swap(A[i], A[Random(i,n)]);
}
return A;
}
随机算法通常是解决问题的最简单的也是最有效的方法。
5.4 概率分析和指示器随机变量的进一步使用
本节包含了较为高级的内容,通过4个范例来进一步解释概率分析:
- 确定在一个有k个人的房间中,某两个人生日相同的概率
- 把球随机投入盒子
- 抛硬币中出现连续正面的情况
- 在面试所有应聘者之前做出决定(雇佣问题的一个变种)
5.4.1 生日悖论 (To do)(生日攻击)- 密码学
在n个人中随机选取k个人,当k为多大时能保证k个人中有两个人的生日是相同的?
你可能会说答案是366,因为一年有365天,根据鸽笼原理(pigeon hole principle),如果有366个人,那么其中两个人必定会在同一天过生日
但其实,用统计学的方法来考虑生日问题之后,我们会惊讶地发现,所需要的人数k远远小于366. 只要k=70,随机选取70个人,这其中两个人有相同生日的可能性就是99.9%,可能性已经非常大了!在k=100时,小于366的三分之一,这个概率能达到99.99997%;而在k=200时,可能性已经时99.9999999999999999999999999998%了!啊!多么的!吃惊!
一个hash function的好坏,就在于它是否能够使输出的值尽量分散,减少输出值的碰撞(collision),这样就能避免两样东西得到同样的输出。
在安全性方面,hash function必须做到够复杂,让人不能够通过简单的几组输入输出结果猜出来这个hash function 用的是什么样的算法。
说了这么多,其实生日攻击就是写出好的hash function最大的绊脚石。如果你把hash function的每个输入值想成是n个人中的一个,再把输出值想成是每个人的生日,那么生日问题就告诉我们,只需要很少的输入值,就会有很大的可能性有至少两个输出值完全相同,也就违反了hash function的条件之一???
(注意这里并不是给定一个输出值和输入值寻找另一个能够得到相同输出值的输入值所需的次数,而是随意尝试几个输入值,能在其中得到相同输出值的总次数)
再深入一点的话,可以把hash function看作是一种mapping:输入值就是定义域,输出是值域。注意hash function不一定是一一映射的,因为定义域和值域的大小不一定相同。大多数情况,为了得到更高的效率和可操作性,hash function的值域都会远小于定义域。在这样的值域当中,碰撞就是必然的。可以想象成把复活节的彩蛋放进篮子里,各式各样的彩蛋只能放进5个有编号的不同篮子里,必定有多个彩蛋在同一个篮子里。这里彩蛋是定义域,篮子是值域。生日攻击能够奏效就是因为这个值域太小,像我们的生日问题中值域只有365,所以只要70个人就能够找到相同生日的两个人。
5.4.2 球与盒子
将相同的球随机投入到b个盒子里,每次投球都是独立的。投球的过程是一组伯努利试验,每次成功的概率为1/b,此处成功是指球落入指定的盒子中。这个模型对分析散列技术特别有用。
5.4.3 序列
设想你抛一枚均匀硬币n次,你期望看到连续正面的最长序列有多长?答案是O(lg(n))