Java数据结构与算法(基础篇)
内含纯基础内容
我本身就是个小白,不会算法
看完之后还是受益匪浅的~
leecode也不至于下不去手了
时间复杂度与空间复杂度
如何衡量算法的优劣

时间复杂度:运行当前算法所需要的时间
空间复杂度:运行当前算法所需要的空间
代码的执行时间与每一行代码的执行次数(n)成一个正比的关系


所以我们才会忽略掉一些数据,只关注渐进的趋势
复杂度分析
时间复杂度 平方阶O(n^2)
举个例子,因此当数量级较大时,整体的增长趋势是有O(n^2)来决定的。
总结一下就是忽略掉低阶、常量、系数三部分
注:低阶是指n的一次方这种

三次方的情况

时间复杂度O(1)
只有常数,只用常数阶O(1)来标示。
但凡没有循环的都是O(1)

时间复杂度O(n)

时间复杂度 对数阶O(logN)

时间复杂度 线形对数阶O(logN)

到底哪种复杂度的更好呢
一般来说,如果复杂度涉及到O(n^2)以上了,就赶快优化
数值越大越明显O(1)最快、其次O(logN)、再次O(N)

重温斐波那契
循环解法
public int fib2(int n){
if (n<=1){
return n;
}
int sum=0;
int first=0;
int second=1;
//循环次数,假设求下标为2的数字,要加一次。为3就加两次以此类推,所以是n-1
for (int i = 0; i < n-1; i++) {
//每次相加都是前两个
sum = first + second;
//将前一个的值覆盖给后一个
first=second;
//相加的结果要给下一个second
second = sum;
}
return sum;
}
循环复杂度 O(n)
递归解法
public int fib1(int n){
if (n<=1){
return n;
}
return fib1(n-1)+fib2(n-2);
}
递归的复杂度分析

可以看到,图上有大量重复调用
深讨时间复杂度
一般我们说时间复杂度都是最坏的情况,也就是最长的时间
举个O(1)~O(n)复杂度的情况
public int function(int num,int target){
int sum=0;
for (int i = 0; i < num; i++) {
if (num==target){//如果第一轮循环直接碰到target,那么复杂度就是O(1),最好的情况
break;
}
sum += i;//如果第num轮循环直接碰到target,那么复杂度就是O(n),最坏的情况
}
return sum;
}


来个真题

递归并且累加
公式是T(n)=T(n-1)+n,只有T(0)=1
那么,将n-1、n-2、n-3…2、1 带入公式,进行递归

因为一直递归是在-1,所以总会有个尽头会变成T(1),就会有个变成常数的尽头,当T(1)就可以把0带入

数组
简介
线性表

元素通过数组下标来进行访问
并且在储存器中的位置是连续的,顺序存储

随机访问
访问快,因为有索引

增删慢,准确地说,末尾元素增删还可以,如果非末尾的地方进行增删,那么会导致插入位置之后的数据随之而移动,导致效率下降

数组优缺点
总结一下优缺点

数组长度不可变,想要存超过长度的内容就得改变长度重新new数组对象把老内容搬进去再加新内容,针对这种情况,有没有解决方法呢?有,java提供了一个ArrayList,处理灵活。ArrayList内部使用Object[]来实现的
除了那八种基本类型,其他都是引用类型
手撕动态数组ArrayList
设计接口

添加元素接口设计
考虑到数组在末尾增加的效率最高,所以add()方法的元素添加位置一定是在最末尾,并且添加时index下标自动+1
容量的size也要增加,并且一旦添加到上限了,要会自动扩容

扩容的条件


数组扩容的思路为先创建一个新的数组,再把老数组的内容搬进去,最后把新元素插入,老数组过一阵子就被GC了

注意>>1的操作来实现1.5中的那0.5
//添加元素在最末尾
public void add(E element){
//先判断长度,如果需要的情况就扩容
if (size> elements.length-1){
//需要扩容
System.out.println("扩容开始");
enSureCapacity(size++);//扩容方法
System.out.println("扩容结束");
}
}
//保证数组的容量的方法
public void enSureCapacity(int capacity) {
if (elements.length>=capacity){
return;
}
//创建新数组是原有的数组扩容1.5倍,利用左移来实现除二的效果,避免出现除不开的情况
E[] newElements = (E[]) new Object[elements.length+(elements.length>>1)];
//迁移老数组内容
for (int i = 0; i < size; i++) {
newElements[i] = elements[i];
}
elements=newElements;
}
添加元素到指定位置

这里有一些问题,就是插入到目标位置之后目标元素之后的元素都要往后位移一位
这个写法暂时还不考虑去扩容的问题
//添加元素在指定位置,后方元素先后移再插入
public void add(int index,E element){
//先避免数组下标越界
if (index<0||index>=size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
//将要添加的元素依次向后移动,先移动最后面的,然后移动最后面-1的元素、-2、-3……一直到目标元素的位置空出来
//必须从后往前移动,不然覆盖掉元素就不太行了
//这里是添加时没越界的情况
for (int i=size;i>index;i--){
elements[i] = elements[i - 1];//前一个元素后移一位
}
//将元素放入目标位置上
elements[index] = element;
//元素数量+1
size++;
}
删除元素方法
实际上删除元素就是把添加元素反着来
先删,其余元素依次再向前移动一位,并且配合一个缩容方法
//删除目标下标的元素
public E remove(int index){
//先避免数组下标越界
if (index<0||index>=size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
//删除数组元素,把后面的元素覆盖掉给新元素
for (int i = index; i < size ; i++) {
elements[i] = elements[i + 1];
}
//元素数-1
size--;
//处理尾位元素
elements[size] = null;
//如果删多了可以考虑是否缩容
if (size==elements.length>>1){
System.out.println("缩容开始");
enSureCapacity(elements.length>>1);//调用缩容方法
}
return elements[index];
}
来个真题Leecode移动0
点击链接查看
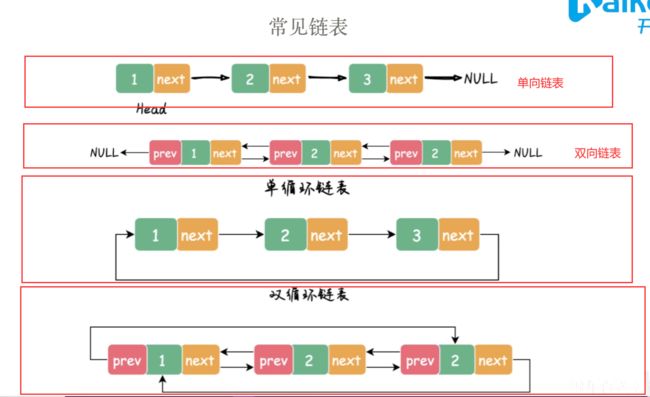
单向链表
链表的定义
链表的定义

所以链表随机增删很快,查找比较慢,因为要按个遍历
单向链表结构图
链表中每一块内存都被称为节点Node
这种是单向链表。只能发现等下一个节点,没法定位到上一个(也就是顺序访问)
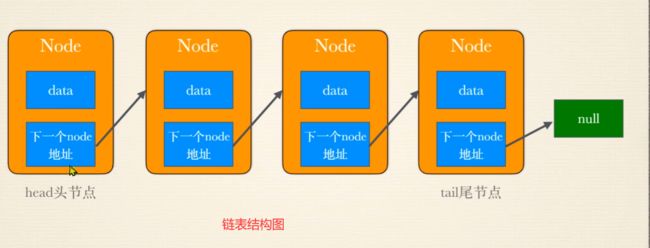

单向链表添加数据
两个节点之间先拆开,插入新的内容,重新指向
假设原来有a指向b,拆开之后加入c
就变成了,a指向c,c再指向b
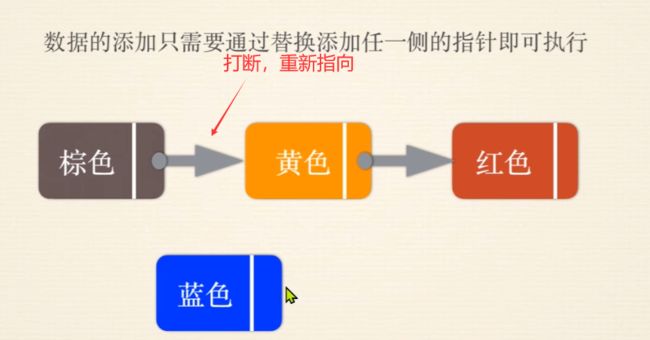

单向链表优缺点

常见链表类型
手撕双向链表LinkedList(单向链表版)
链表继承结构的设计

接口定义
后续实现这个List接口的LinkedList(单向链表版本就需要全部实现接口的内容)

public interface CCList<E> {
public int size();
public int indexOf(E element); //查看元素的位置
public boolean contains(E element); //是否包含某个元素
public E get(int index); //返回index位置对应的元素
public E set(int index, E element); //设置index位置的元素
public void clear(); //清除所有元素
public void add(E element); //添加元素到最后面
public void add(int index, E element); //往index位置添加元素
public E remove(int index); //删除index位置对应的元素
public boolean isEmpty();//是否为空
}
用抽象类来实现接口来写一些公共的代码,为后续LinkedList继承做铺垫
这里公共的代码也包含了ArrayList中的内容,类似contains方法,size方法,这些都是通用的就没必要再写一遍
public abstract class abstractCcLinkedList<E> implements CCList{//这里都是一些通用方法
//protect代表子类可以访问到
protected final static int ELEMENT_NOT_FOUND = -1;
protected final static int size = 0;
//元素的数量
public int size(){
return 0;
}
//判断包含某个元素
public boolean contains(E elements){
//就是查找元素是否存在
return indexOf(elements) != ELEMENT_NOT_FOUND;
}
//判断当前数组是否为空
public boolean isEmpty(){
//直接返回判断值,真nb
return size == 0;
}
//添加元素在最末尾
public void add(E element){ }
}
返回节点方法get
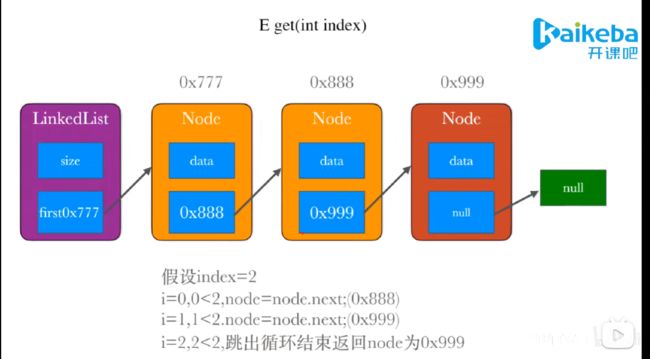
public Object get(int index) {//从头到尾遍历出来
//下标越界处理
checkIndex(index);
//拿到第一个节点后进行遍历,这个first是之前定义好的
Node<E> node= first;
for (int i = 0; i < index; i++) {//遍历到第index个就可以了,把节点的位置指向改好就好了
node = node.next;
}
return node;
}
private void checkIndex(int index) {
//先避免数组下标越界
if (index<0||index>=size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
}
设置目标节点位置元素方法set
set方法
注意size与index的关系,假设一共有三个元素size为3,那么index就是0、1、2
所以index的最大值+1就是size
@Override//设置目标位置的值,并且返回原来被替换之前的值
public Object set(int index, Object element) {
//先查看下标是否越界
checkIndex(index);
//保存老元素用
Object oldElement = new Object();
//获取当前位置节点,并修改目标节点内元素
//node方法是通过下标获取节点
Node<E> node = node(index);
oldElement = node.element;
//新元素覆盖
node.element = (E) element;
//返回老元素
return oldElement;
}
清空元素clear

只要把头结点的指针指向null,其余的结点就自动迷失在内存了,没有引用就等待GC回收掉就万事大吉了
思路:
头结点Node的next改为为null,element元素也改null,size也改0就ok了
@Override//清除所有元素,所有值赋null,无引用的情况下就可以等待GC回收掉
public void clear() {
//first为头节点
first.element = null;
first.next = null;
//链表元素数清零
size = 0;
}
查找元素indexOf
查找元素位置并且返回下标值
@Override
public int indexOf(Object element) {
Node node = first;
if (element==null){//查找有null的情况
for (int i = 0; i < size; i++) {
if (node.element == null) {
return i;
}
//遍历时位移,指向下一个
node=node.next;
}
}else {//不为null时
for (int i = 0; i < size; i++) {
if (node.element==element){
return i;
}
//遍历时位移,指向下一个
node=node.next;
}
}//剩下的情况都是没找到,返回元素没找到的常量值
return ELEMENT_NOT_FOUND;
}
添加节点add元素
错误示范
上来就直接打断重新指向这是绝对错误的!一打断后面的链表就迷失了

正确玩法
先改成指向下一个节点,在让前一个节点指向新节点
也就是先动新增节点的指针,而不是动老节点

思路:
先找到前一个节点的地址,再找到后一个节点的地址,有了地址才能有下一步操作

@Override
public void add(int index, Object element) {//完成拆开重新指向的操作
//先看看下标是否越界
checkAddIndex(index);
//获取目标位置的前一个节点
Node pre = node(index - 1);
//获取下一个节点的地址(这里的下一个是针对没拆开时候的下一个)
Node next = pre.next;
//创建新元素,将上一个节点的next指向指到新节点上,并且将下一个节点的next指向放进去
pre.next = new Node(next, element);
//添加完毕,体量+1
size++;
}
private void checkAddIndex(int index) {
//先避免数组下标越界,因为是下标,比容量小一位,所以就是>size而不是>=size
if (index<0||index>size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
}
极端情况index=0了呢?
思路

也就是说吧老first节点指向下一个传进去就行
假设原来有ab,现在要插入c。
那么传入的那个first是就是原来a指向b的地址
最左边的first就是重新插入后a指向c的地址
运行完就变成了a指向c,c指向b
@Override
public void add(int index, Object element) {//完成拆开重新指向的操作
//先看看下标是否越界
checkAddIndex(index);
if (index==0){
//头结点first的指向改成新节点就可以了,Node构造方法里传入的first是没插入之前的first节点下一个的指向
first = new Node<>(first, element);
}else {
//获取目标位置的前一个节点
Node pre = node(index - 1);
//获取下一个节点的地址(这里的下一个是针对没拆开时候的下一个)
Node next = pre.next;
//创建新元素,将上一个节点的next指向指到新节点上,并且将下一个节点的next指向放进去
pre.next = new Node(next, element);
}
//添加完毕,体量+1
size++;
}
删除节点remove方法
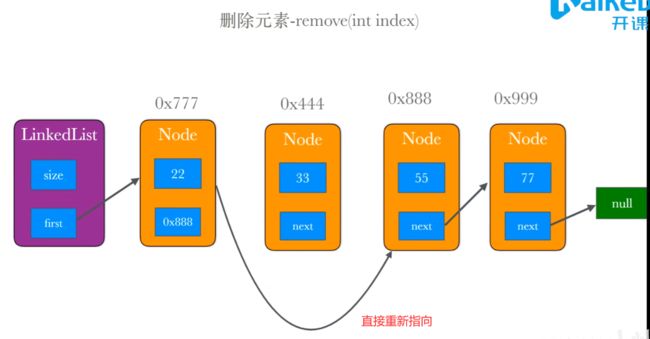

思路:
获取前一个节点
存一下老节点后面返回用
将被删除节点的下一个节点的地址赋值给前一个节点的next地址
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//获取前一个节点
Node pre = node(index - 1);
//存一下将要被删掉的值准备返回
Node oldNode = pre.next;
//将目标被删除节点的后一个节点的地址赋值给前一个节点的next
//骚操作,俩next相当于跳过了被删除节点
pre.next = pre.next.next;
//返回老节点
return oldNode.toString();
}
特殊情况,index如果为0了怎么办,也就是删除头节点之后的那个节点
思路就是把first节点的next指向第三个节点(index=1)的位置,来跳过index=0的节点来达到删除的目标
注意,这里first的地址就是index=0的位置,也就是0x777,换句话说,0x777就是first,那么想获取目标元素的下一个就是0x777的next,换算一下,把first=0x777带进去,得到的第三个节点(index=1)的位置就是first.next

最终代码
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//避免下标越界
checkIndex(index);
if (index == 0) {
//删除下标为0的特殊情况,
//first的下一个节点指向原来的第三个节点(next)
first = first.next;
}else {
//下标不为0了
//获取前一个节点
Node pre = node(index - 1);
//存一下将要被删掉的值准备返回
Node oldNode = pre.next;
//将目标被删除节点的后一个节点的地址赋值给前一个节点的next
//骚操作,俩next相当于跳过了被删除节点
pre.next = pre.next.next;
//容量缩减
size--;
//返回老节点
return oldNode.toString();
}
return null;
}
总结
public class CcLinkedList<E> extends abstractCcLinkedList{
private Node<E> first;
//定义一个内部类来储存节点信息
private class Node<E>{
Node<E> next;//下一个节点的地址
E element;//节点内部存储的信息
public Node(Node next, Object element) {
this.next = next;
this.element = (E) element;
}
}
private Node node(int index) {
checkIndex(index);
//拿到first
Node node = first;
//遍历到index位置
for (int i = 0; i <index ; i++) {
node = node.next;
}
return node;
}
@Override
public int indexOf(Object element) {
Node node = first;
if (element==null){//查找有null的情况
for (int i = 0; i < size; i++) {
if (node.element == null) {
return i;
}
//遍历时位移,指向下一个
node=node.next;
}
}else {//不为null时
for (int i = 0; i < size; i++) {
if (node.element==element){
return i;
}
//遍历时位移,指向下一个
node=node.next;
}
}//剩下的情况都是没找到,返回元素没找到的常量值
return ELEMENT_NOT_FOUND;
}
@Override//获取下标位置的元素
public Object get(int index) {//从头到尾遍历出来
//下标越界处理
checkIndex(index);
//拿到第一个节点后进行遍历,这个first是之前定义好的
Node<E> node= first;
for (int i = 0; i < index; i++) {//遍历到第index个就可以了,把节点的位置指向改好就好了
node = node.next;
}
return node;
}
//检查下标越界情况
private void checkIndex(int index) {
//先避免数组下标越界
if (index<0||index>=size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
}
@Override//设置目标位置的值,并且返回原来被替换之前的值
public Object set(int index, Object element) {
//先查看下标是否越界
checkIndex(index);
//保存老元素用
Object oldElement = new Object();
//获取当前位置节点,并修改目标节点内元素
//node方法是通过下标获取节点
Node<E> node = node(index);
oldElement = node.element;
//新元素覆盖
node.element = (E) element;
//返回老元素
return oldElement;
}
@Override//清除所有元素,所有值赋null,无引用的情况下就可以等待GC回收掉
public void clear() {
//first为头节点
first.element = null;
first.next = null;
//链表元素数清零
size = 0;
}
@Override
public void add(int index, Object element) {//完成拆开重新指向的操作
//先看看下标是否越界
checkAddIndex(index);
if (index==0){
//头结点first的指向改成新节点就可以了,Node构造方法里传入的first是没插入之前的first节点下一个的指向
first = new Node<>(first, element);
}else {
//获取目标位置的前一个节点
Node pre = node(index - 1);
//获取下一个节点的地址(这里的下一个是针对没拆开时候的下一个)
Node next = pre.next;
//创建新元素,将上一个节点的next指向指到新节点上,并且将下一个节点的next指向放进去
pre.next = new Node(next, element);
}
//添加完毕,体量+1
size++;
}
private void checkAddIndex(int index) {
//先避免数组下标越界,因为是下标,比容量小一位,所以就是>size而不是>=size
if (index<0||index>size){
throw new IndexOutOfBoundsException("当前下标越界允许范围0~"+(size-1));
}
}
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//避免下标越界
checkIndex(index);
if (index == 0) {
//删除下标为0的特殊情况,
//first的下一个节点指向原来的第三个节点(next)
first = first.next;
}else {
//下标不为0了
//获取前一个节点
Node pre = node(index - 1);
//存一下将要被删掉的值准备返回
Node oldNode = pre.next;
//将目标被删除节点的后一个节点的地址赋值给前一个节点的next
//骚操作,俩next相当于跳过了被删除节点
pre.next = pre.next.next;
//容量缩减
size--;
//返回老节点
return oldNode.toString();
}
return null;
}
}
刷个真题Leecode删除链表中的节点
直接点击链接食用就好
删除节点
删除重复节点
双向链表
性能提升很多,比如我想找3,就可以从4倒推往前找
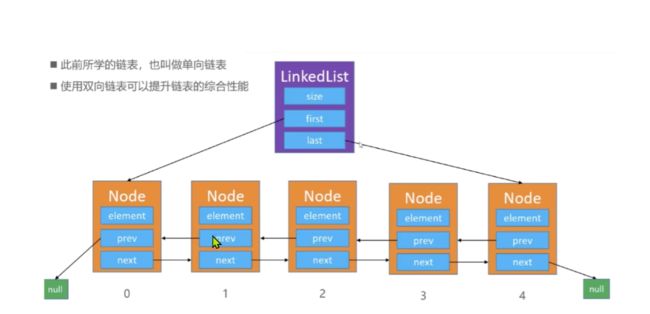
添加操作

手撕双向链表
添加方法add

清空方法clear
先看看单向链表版本的clear
@Override//清除所有元素,所有值赋null,无引用的情况下就可以等待GC回收掉
public void clear() {
//first为头节点
first.element = null;
first.next = null;
//链表元素数清零
size = 0;
}
双向链表的话,因为有pre和next两个指针,也就是要把链表最后的节点last给变成null,防止pre起效倒着走还能用的情况,把两个方向全都断掉也就好用了
@Override//清除所有元素,所有值赋null,无引用的情况下就可以等待GC回收掉
public void clear() {
//first为头节点
first=null;
last = null;
//链表元素数清零
size = 0;
}
获取节点node(index)
因为链表可以从两端获取,所以以中间为分界点。
下标比中间小就从头开始找
下标比中间大就从尾开始找
//获取节点
private Node node(int index) {
//先看越界没有
checkIndex(index);
//判断一下index是在链表的前半部分还是后半部分size>>1左移一位完成除二操作
if (index<size>>1){
//保存一份出来,不可以直接操作first
Node node = first;
//位于前半部分,从头遍历
for (int i = 0; i <index ; i++) {
node = node.next;
}
return node;
}else {//位于后半部分,从尾遍历
//保存一份出来,不可以直接操作last
Node node = last;
for (int i = size-1; i >index ; i--) {
node = node.pre;
}
return node;
}
}
添加方法add
在两端添加元素
因为涉及到pre和next两个节点的操作所以动的东西比较多

这种情况是非两端添加的情况,不涉及极端情况
//先拿到新增位置的下一个节点
Node<E> next = node(index);
//还没拆开之前的pre
Node<E> pre = next.pre;
//创建新节点,传入元素以及前后节点
Node<E> node = new Node<E>(element, pre, next);
//更改老的前后节点指向
pre.next = node;
next.pre = node;
开始位置添加节点

//提取出来公共部分的代码
//先拿到新增位置的下一个节点
Node<E> next = node(index);
//还没拆开之前的pre
Node<E> pre = next.pre;
//创建新节点,传入元素以及前后节点
Node<E> node = new Node<E>(element, pre, next);
next.pre = node;
if (index==0){//往头节点插入
first=node;
}else {
//更改老的前后节点指向
pre.next = node;
}
size++;
在最后添加节点

注意下面这个图,如果第一次添加那么就让first和last就都指向同一个节点就可以了
因为last有指向Node,所以为了避免麻烦,直接让first指向last就可以了

总结
@Override
public void add(int index, Object element) {//完成拆开重新指向的操作
//先看看下标是否越界
checkAddIndex(index);
//提取出来公共部分的代码
//先拿到新增位置的下一个节点
Node<E> next = node(index);
//还没拆开之前的pre
Node<E> pre = next.pre;
//创建新节点,传入元素以及前后节点
Node<E> node = new Node<E>(element, pre, next);
next.pre = node;
if (index==0){//往头节点插入,直接赋值
first=node;
}else if (index==size){//末尾插入,直接赋值
//存一下老节点
Node<E> oldLastNode = last;
//创建新增的尾结点,构造方法传入
last = new Node<>(element, oldLastNode, null);
if (oldLastNode==null){
//链表中一个节点都没有的情况
first = last;
}else {
//至少有一个的情况,就直接改指向指向我们新建的节点
oldLastNode.next = last;
}
} else {//两种极端情况都不存在,那么只有一种可能就是在中间插入
//更改老的前后节点指向
pre.next = node;
}
size++;
}
删除方法remove
删除中间节点
直接跳过目标节点然后再重新连接就好了
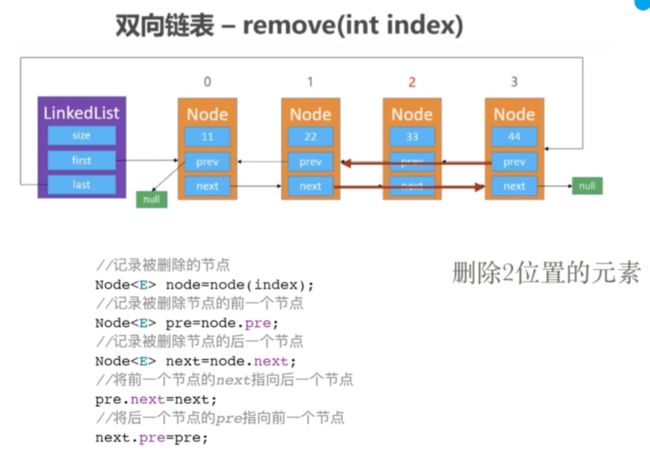
分层结构上和add方法差不多,也是排除掉两边的极端情况,最后就是删除中间的操作
删除首节点和尾节点
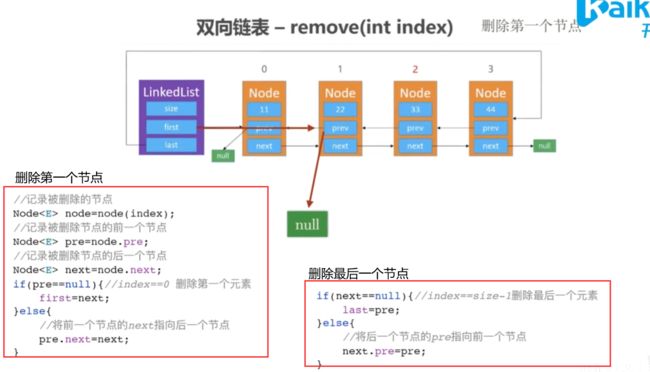
总结
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//避免下标越界
checkIndex(index);
//提取出公共代码部分
//备份被删除节点以及其前后节点
Node<E> node = node(index);
Node<E> preNode = node.pre;
Node<E> nextNode = node.next;
if (preNode == null) {
//头节点的特殊情况,删除第一个节点,直接改指向
first = nextNode;
}else if (nextNode == null){//表示尾结点,直接赋值null
last = preNode;
}else {//删除中间元素
//跳过被删除节点指向
preNode.next = nextNode;
nextNode.pre = preNode;
}
//容量缩减
size--;
return null;
}
对比一下双向链表和各种数据结构
时间复杂度比较

双向链表与动态数组比较

循环链表(最恶心)
单向循环链表
概述
注意,循环链表中是不允许指向有null的出现的!因为null代表着循环结束

手撕单向循环链表
主要是头和尾的节点插入问题上比较麻烦,因为涉及到指向问题
中间的节点就还好,和之前的单向链表的增删思路是完全一样的
插入方法add
插入位置为头结点的位置
如果再链表的头部插入就非常麻烦,需要先把尾结点的指向改成新节点的地址,再把新节点的next指向改为原来的头结点,最后改LinkedList对象的first指向为新节点,到这就算插入位置index==0的情况

if (index==0){
//创建新节点,再把循环链表对象的指向改为新节点,老节点被新节点重新指向
Node newNode = new Node<>(first,element);
//把新节点的next指向改为原来的头结点,修改尾结点的next指向
get(size-1).next= (Node) element;
//改LinkedList对象的指向为我们的新节点
first = newNode;
}
还有一个更极端的情况,只有一个节点的情况

if (index==0){
//创建新节点,再把循环链表对象的指向改为新节点,老节点被新节点重新指向
Node newNode = new Node<>(first,element);
//把新节点的next指向改为原来的头结点,修改尾结点的next指向,同时判断是否只有一个节点
Node last = (size == 0) ? newNode : node(size - 1);
last.next = newNode;
//改LinkedList对象的指向为我们的新节点
first = newNode;
}
插入位置为尾结点的位置
和之前的写法就一样了
}else {
//获取目标位置的前一个节点
Node pre = node(index - 1);
//获取下一个节点的地址(这里的下一个是针对没拆开时候的下一个)
Node next = pre.next;
//创建新元素,将上一个节点的next指向指到新节点上,并且将下一个节点的next指向放进去
pre.next = new Node(next, element);
}
//添加完毕,体量+1
size++;
删除方法remove

删除头节点
先把尾结点拿到
再把first的指向改为原来first的next
if (index == 0) {
//删除下标为0的特殊情况,先拿到尾结点
Node last = node(size - 1);
//再把first的指向改为原来first的next
first = first.next;
//最后改尾结点指向为原来头节点的next
last.next = first.next;
}
极特殊情况

完全版本
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//避免下标越界
checkIndex(index);
if (index == 0) {
if (size==1){
//只有一个的情况
first = null;
} else {
//删除下标为0的特殊情况,先拿到尾结点
Node last = node(size - 1);
//再把first的指向改为原来first的next
first = first.next;
//最后改尾结点指向为原来头节点的next
last.next = first.next;
}
}else {
//下标不为0了
//获取前一个节点
Node pre = node(index - 1);
//存一下将要被删掉的值准备返回
Node oldNode = pre.next;
//将目标被删除节点的后一个节点的地址赋值给前一个节点的next
//骚操作,俩next相当于跳过了被删除节点
pre.next = pre.next.next;
//容量缩减
size--;
//返回老节点
return oldNode.toString();
}
return null;
}
手撕双向循环链表

插入方法add
如果只有一个节点的情况就得我指我自己了,和之前双向链表差不多,稍微改造一下就行

删除方法remove
如果是删除第一个节点,就让first的指向改为被删除前的头节点的next

如果是最后一个节点,就要把last节点的pre指向前移,同时next的指向也要改变
话不多说上代码
@Override
public Object remove(int index) {//删除当前元素并且返回这个被删除的值
//避免下标越界
checkIndex(index);
//只有一个的情况,first和last节点直接等于null断掉就好了
if (size==1){
first = null;
last = null;
}
//提取出公共代码部分
//备份被删除节点以及其前后节点
Node<E> node = node(index);
Node<E> preNode = node.pre;
Node<E> nextNode = node.next;
if (index == 0) {//删除首节点,不可以用null来判断,因为双向循环链表不允许出现null
first = nextNode;
}else if (index==size-1) {//删末尾节点
//尾结点的last改preNode
last = preNode;
}else {//如果以上都不是,就代表是中间节点,前一个节点的next指向后一个节点,跳过被删除节点
preNode.next = nextNode;
}
//容量缩减
size--;
return null;
}
约瑟夫环问题
具体科普看这里
约瑟夫问题
刷个真题Leecode反转链表


直接点个看笔记,不多赘述了翻转链表解析
栈
概述
一般用于一端插入的情况,先进后出后进先出的情况

手撕一个栈
基于数组来实现栈,继承之前的动态数组类,一些代码就不用重复写了
为什么说是数组实现?


所以我们说栈也是数组实现的
因为继承而出现的问题
通过继承来拿到父类中的方法和属性这本没有错,也会更加方便,但是就是因为继承的关系,就导致我栈可以调用父类里的方法,例如栈能调用到父类数组的add方法。这就是不提倡的,应该是分离的关系,但是可以用接口来调用,所以我们把is a改为has a 的关联关系
这是之前的案例,通过extends来拿父类的东西,这样就会导致子类有可能调用父类的API
//基于数组实现栈,继承动态数组,少写一些通用内容
public class CcArrayStack<E> extends CcArrayList<E> {
//入栈操作,压入目标元素
public void push(E elemnt){
add(elemnt);
}
//出栈操作,弹出栈顶元素,实际上也是一种从栈中删除
public E pop(){
return remove(size - 1);
}
//返回栈顶元素
public E top(){
return get(size - 1);
}
}
更改之后
提一嘴,我们这里的add和remove方法都是默认操作数组尾部的,所以添加默认从尾添加,删除默认从尾部开始删除
间接也就完成了栈的玩法~
//基于数组实现栈,继承动态数组
public class CcArrayStack<E> extends CcArrayList<E> {
CcArrayList<E> ccArrayList = new CcArrayList();//或者List接口用多态也行,因为CcArrayList也是实现List接口了
private int stackSize = ccArrayList.size();
//入栈操作,压入目标元素
public void push(E elemnt){
ccArrayList.add(elemnt);
}
//出栈操作,弹出栈顶元素,实际上也是一种从栈中删除
public E pop(){
return ccArrayList.remove(size - 1);
}
//返回栈顶元素
public E top(){
return ccArrayList.get(size - 1);
}
}
栈的应用场景有哪些
- 表达式的转换:中缀转后缀与求值
- 递归方式就是函数自身调用自身,当递归每次调用自身时,可以看作是入栈的过程,当递归条件满足后,结束时递归再一级一级的返回,返回过程可以看作是出栈的过程。递归和栈的实现过程可以看出都是符合“先进后出,后入先出”的原则,所以递归方式其实可以转化为栈的方式来实现。
- 对于二叉树的遍历,先序、中序、后序遍历都可以用到递归方法实现,既然递归可以转化为栈,那么如何把对二叉树的遍历也改为用栈的思想来实现
栈的前后中缀表达式
前缀表达式
这个是计算机才认识的前缀表达式,利用栈来实现

中缀表达式
中缀表达式就是人们认识的表达式

后缀表达式
顺序和前缀表达式完全相反,从左往右的压栈

用栈实现计算器
思路

实现
用两个栈,一个数字栈,另一个是符号栈
遇到数字放到数字栈里,遇到符号放到符号栈里
看看大佬的吧,我实在是写不出来了…
点击这里查看
表达式转换
中缀表达式转前缀表达式
前缀表达式是从右往左扫描的
把人能看懂的中缀表达式1+2+3转换成计算机能看懂的前缀表达式++321
转换方法
结尾
到这里就算基础篇告一段落了,下面点击这里开始进阶篇