LightGBM
目录
简介
有关GBDT的基础介绍
关于监督学习
关于Boosting
关于Gradint Boosting
关于决策树
关于XGBoost
LightGBM
LightGBM的优势
LightGBM与XGBoost对比
LightGBM的直方图优化
LightGBM采用带深度限制的Leaf-wise
LightGBM采用直方图作差的优化
LightGBM使用方法
参数
防止过拟合的方法
实例代码
简介
LightGBM(Light Gradient Boosting Machine)是一款常用的GBDT(Gradient Boosting Decision Tree)工具包,由微软亚洲研究院开发,速度比XGBoost快,精度也还可以。它的设计理念是:
- 单个机器在不牺牲速度的情况下,尽可能使用上更多的数据。
- 多级并行的时候,通信的代价尽可能的低,并且在计算上可以做到线性加速。
所以其使用分布式的GBDT,选择了机遇直方图的决策树算法。LightGBM是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
有关GBDT的基础介绍
关于监督学习
监督学习的组成可以分为数据(Data)、模型/函数(Model/Function)、损失函数(Loss Function)、 正则化(Regularization)。

数据中X是多维特征,Y是标注信息即标签。监督学习通常就是寻找一个从X到Y的映射,我们称之为模型/Model。一个映射好不好或者模型对不对,主要是通过损失函数来衡量。损失函数有很多种,如上图中的就是平方误差,也就是模型的输出和Y标注信息的平方误差。监督学习就是通过调整权重参数使得损失函数最小化。但是值得注意的是如果一味的追寻损失函数最小化会使得过拟合,所以通常会加一些正则项来控制模型。图中就是L1的正则化,从而将监督学习的优化目标变成了损失函数和正则项的组合函数。
关于Boosting
Light就是Boosting的一种,Boosting就是指一系列模型的线性组合来完成学习任务。

在这个学习过程当中逐步的确定每一个模型,也就是每一个子模型叠加到符合模型当中来,在这个过程当中保证损失函数随着模型的增加而逐渐减少的方法。目前主流的有两种,一种叫Adaboost,一种叫Gradient Boosting,本质上来说方法都是在训练好一个子模型后,统计一下现有的复合模型的拟合情况,从而调节接下来学习任务的一些setting,使得接下来找到了子模型。加入复合模型之后如何降低整体的目标。
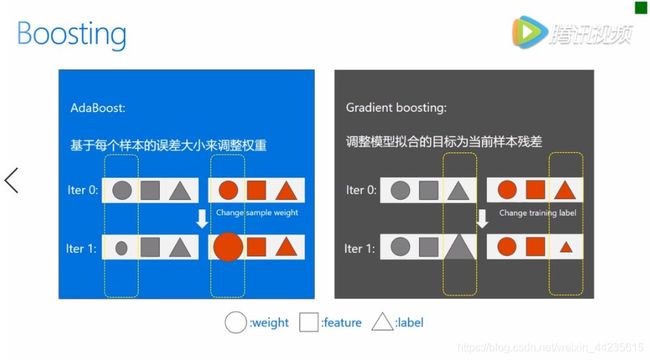
AdaBoost主要是按照当前的loss来改变样本的权重,也就是说如果这个样本在之前的学习过程当中误差比较大,那么它会获得比较大的权重;如果误差比较小,就会获得一个更小的权重,从而控制了接下来子模型的产生,Gradient Boosting则是直接去修改样本的label。实际上新的样本的label将变为原来的label和模型预测值之间的残差。从直观上来看,Gradient Boosting似乎更加针对降低训练误差的角度去完成算法设计的。
关于Gradint Boosting

接下来我们来详细介绍一下Gradient Boosting。像我刚刚提到的,完整的模型是有很多我们称为base learner子模型来组成的,学习过程当中是一个一个的去增加这些子模型,并且在过程当中希望loss能够不断减小。如果我们把复合函数F作为自变量来看,我们希望通过改变这个复合函数使得来下降,那么无疑沿着相对于F的梯度方向是一个合理的选择。换句话说,如果我们新加入的子模型使得F沿着相对于F的梯度方向变了,那么我们就得到了我们希望要的模型。在实际问题当中,比如比如说我们定义的是平方误差,也就是L2 loss,那么梯度的方向就是估计值和样本标签的残差,而我们新加入的子模型其实就应该朝着这个残差来学习,也就是我们现在上图显示的fm。

了解了Gradient Boosting的算法思想,我们很容易就明白什么是GBDT了,也就是当Gradient Boosting当中每一个base learner都是一个decision tree的时候,我们就把它叫做GBDT,上边图右边这个框里面基本上就是把之前我们说的流程用代入了一下,用GBDT我们可以用来做很多类型的task,比如说Regression分类,还有Ranking排序等等。
关于决策树
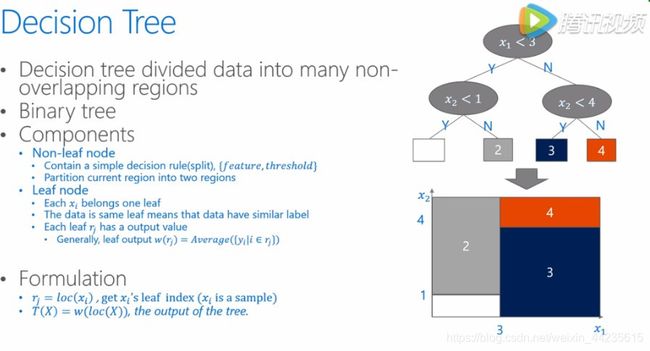
后面会遇到很多有关decision tree的细节,所以也复习一下decision tree。decision tree就是把数据的feature和value划分成很多不重叠的区域,一般来说我们都是指的二叉树,在树中分叶子节点上面是要做分割的,所以在这里会包含分割点的信息,也就是说我们会有哪一个feature,然后这个feature上我用什么样threshold,随后的将数据分为左边和右边两个部分,从而去不断地把这个树长得更深。而在叶子节点当中,包含了最终的分类信息,也就是说将归入到同一个叶子节点的数据会被合在一起,生成这个叶子节点输出。通常我们在这里会用在这个节点上所有样本的均值来作为这个节点的输出。当我们这个数已经训练完了,如果新来的数据,那么我们要给它做一个预测的输出的时候,基本上也是这样一个过程,将输入数据拿过来之后,去经过这个树的这些规则,然后我们判断一下这个样本应该落在叶子哪跟叶子节点上面,然后我们就用刚刚的叶子节点的输出,来作为对这样一个样本的判断,输出它的一个分类信息。
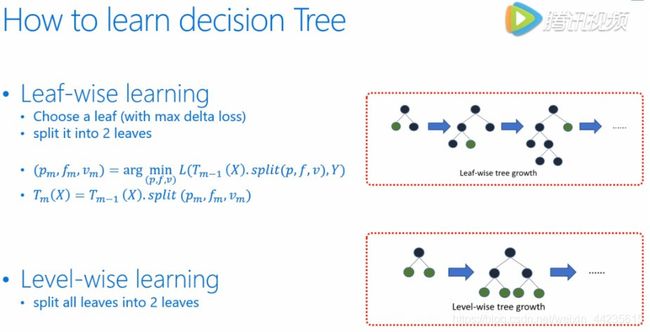
decision tree学习过程可以分为下面两种,一种我们叫做Leaf-wise learning,也就是说学习过程当中,我们需要不断的寻找分裂后收益最大的叶子节点并且对其进行进一步的分裂,从而生长这棵树。可以说这种方方法会更加快速有效的学到模型,但这种方法有一点不好,就是整个生长的过程都是顺序的多方面加速,因此有另一种方法Level-wise learning。也就是说树的生长是按层去长,不需要每次去挑选生长的节点,只需要按顺序去长就行了,这样在每一个level当中,各个节点的分裂可以变形的完成,具有天然的平行性,但是这会有很多没有必要的分裂产生,也许会有更多的计算代价。

我们下面来看一下decision tree学习的伪代码,其实就是在每一个需要分裂的点,我们去寻找最佳的分裂位置,也就是根据当前节点的数据找到当前节点最佳分裂需要用的最佳的特征值,然后进行分裂寻找。寻找这个最佳特征值的过程就是遍历所有的特征和它们可能的取值,假设在这一点把数据分成两部分后带来的损失变化,这是我们需要去计算的,有时候我们也会用information gain作为衡量准则。通过逐一的比较,找到能够让我们获得最大收益的分裂点,也就是我们这里提到的 确定哪一个leaf要进行分裂,
确定哪一个leaf要进行分裂,![]() 是哪一维特征,而
是哪一维特征,而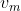 是指的这为特征当中最高的那个value,也就是我们所说的那个随后的来决定大于这个值的就放到左边,小于这个值的放到右边。而在这里FindBestSplit是计算代价最大的地方,GDBT就是不断的增加新的decision来拟合之前的残差,而每棵树的学习都包含了整个decision tree的计算流程。
是指的这为特征当中最高的那个value,也就是我们所说的那个随后的来决定大于这个值的就放到左边,小于这个值的放到右边。而在这里FindBestSplit是计算代价最大的地方,GDBT就是不断的增加新的decision来拟合之前的残差,而每棵树的学习都包含了整个decision tree的计算流程。
关于XGBoost
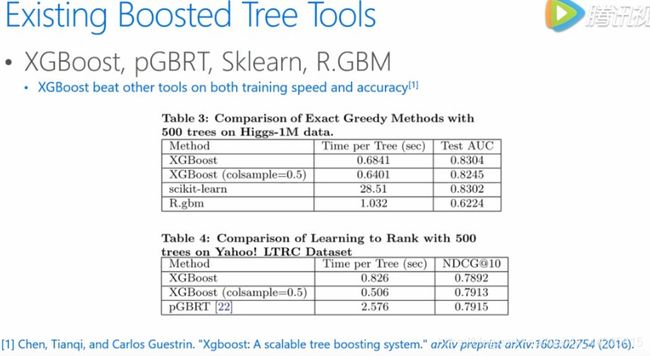
现有的GBDT工具很多,比较著名的在这边列了一些,列了一些他们的对比,相信很多人都使用过,特别是做比赛的同学,XGBoost在性能上面确实比其他的工具要好,特别在速度上的优势,并且他们提供了非常方便的接口,在python或R可能语言上面都很方便的去使用,大家可以看到,不管是从训练的时间上来说或者是最后的test来说,都是要好于他的对手。XGBoost有着优越的性能和广泛的用户。

在这里对XGBoost做一下简单的介绍,首先XGBoost是一种基于排序的方法,他会将每一个unique value用来做计算,好处是能够找到特定的feature value作为分割点,不好的地方就是这种方法的计算代价和存储代价都比较高。并且这样找到的特别精确的那个分割点,可能存在过拟合。另外它生长每棵树的方法是我们前面介绍的按层生长,按层生长会带来不少时间的好处,比如说每一层可以都一定会对所有的数据做一次操作,于是有些操作可以进行全体数据过一遍来完成,但是不好的地方就会有一些没有必要的运算,比如说有的节点其实是不需要进行分裂的。
LightGBM
LightGBM的优势
LightGBM的开源地址:LightGBM在GitHub上的开源网址

LightGBM与Gradient Boost的类似,它也是一个Gradient Boost算法的框架,其实设计的初衷就是高效与并行化。该模型由诸多的特点,首先是训练速度快,另外我们考虑到更大的模型训练的问题,所以严格控制内存的使用,我们特别的处理了类别特征,从而大大的加快了训练的速度。当然不仅仅是速度快,LightGBM有更好的模型精度,除了单机训练之外呢,LightGBM主要考虑如何能够扩展到多机并行训练,从而可以处理更大规模的数据。
LightGBM与XGBoost对比

这个表格给出的LightGBM和XGBoost之间更加细致的性能对比,包括了树的生长方式,LightGBM是直接去选择获得最大收益的节点,而XGBoost是通过按层生长的方式,这样LightGBM可以在更小的计算代价上面建立我们需要的决策树。当然,这样的算法下面我们也需要控制树的深度和每个叶子节点的最小的数据量,从而减小过拟合。分裂点搜寻的方法XGBoost是预排序的方法,而LightGBM用了Histogram的方法将特征值分为很多小桶,这样其实带来了包括存储代价和计算代价等等方面的缩小,从而得到了更好的性能。另外,数据结构的变化也使得细节处理方面效率有所不同,比如说对缓存的利用,LightGBM有更高效的使用,从而使得它有了比较好的一个加速性能,而对于特别是类别的那个特征处理也会使得LightGBM在特定的数据上有非常大的提升。

这里是一些数据集上的实验对比,左边分别对比的这些应用上的准确率和内存的使用情况,在Higgs和Expo都是分类数据,Yahoo LTR和MSLTR都是排序数据,这些数据上LightGBM都有更好的准确率和更小的内存使用量。右边呢是一个计算速度的对比,完成相同的训练量,XGBoost所需要的时间通常是LightGBM数倍之长。
LightGBM的直方图优化
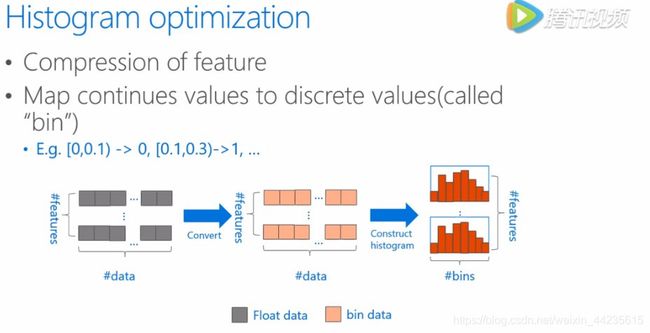
直方图优化(Histogram Optimization),XGBoost的算法采用的预排序的方法,计算过程当中则是按照feature value的排序逐个数据样本来计算当前feature value的分裂收益,这样的算法能够精确的找到最佳的分裂值,但是代价非常大,同时也不一定有好的推广性。所以在LightGBM当中,并没有沿用传统的预排序的思路,而是将这些连续的或者精确的每一个feature value划分到一系列的离散中去,也就是我们所说的桶里面。
这个图里面描述的是这样一个过程,以浮点型的这样一个特征来举例,一个区间的值会被作为一个桶,比如说这样0~0.1范围内,我们叫做第零个桶,0.1~0.3范围内,叫第一个桶,有了分桶的信息,我们建立起来的就是基于分桶的一个直方图的统计,之后的计算都会基于这些以分桶为精度单位的直方图来做。这样一来,数据的表达变得更加简化,减少了内存的使用,而且直方图带来了一定的正则化的效果,使得做出的模型不容易过拟合,获得更好的推广性。

这是做过直方图优化之后的寻找最佳分裂点的求解函数的细节,可以看到这是按照bin来索引Histogram的,所以不需要按照每一个feature来排序,也不需要去一一的对比所有不同的feature的值,大大的减少了运算量。

当我们用feature的bin来描述数据的特征的时候,带来的变化首先LightGBM不需要向预排序算法那样去存储每一个feature排序或对应的data的序列,也就是最左侧表在基于Histigram的一个算法当中是不需要的,也就是这个代价就变成了零。另外,因为用bin来表示feature,那么一般bin的个数都会控制在比较小的范围内,其实我们就可以用更少的Byte来存储,比如说这里是用Byte来存,而原先的feature value可能是float,就会用四个Byte来存。所以总体上来看,把内存的使用量往往会降降低到原来的1/8。
LightGBM采用带深度限制的Leaf-wise

即便使用了带有深度限制的Leaf-wise的长树方法来提高模型的精度,Leaf-wise是一种比较于level-wise生长,更高效的长树方法,像叶子数量一样的时候,Leaf-wise可以降低更多的训练误差,得到更好的精度,但单纯的使用Leaf-wise的生长可能会长出比较深的树,在小数据集上可能造成过拟合,因此LightGBM在Leaf-wise之上多加了一个深度的限制。
LightGBM采用直方图作差的优化

LightGBM还使用了直方图做差的优化达到了两倍的加速。可以观察到一个叶子节点上的直方图可以由它的父亲节点的直方图减去它兄弟节点的直方图来得到。根据这一点,LightGBM可以构造出来计算数据量比较小的叶子节点上的直方图,然后用直方图做差得到数据量较大的叶子节点上的直方图,达到加速的效果。
LightGBM使用方法
参数
boosting_type (string__, optional (default="gbdt")) – ‘gbdt’, traditional Gradient Boosting Decision Tree. ‘dart’, Dropouts meet Multiple Additive Regression Trees. ‘goss’, Gradient-based One-Side Sampling. ‘rf’, Random Forest.
默认的就挺好
num_leaves (int__, optional (default=31)) – Maximum tree leaves for base learners.
每个基学习器的最大叶子节点。LightGBM 使用的是 leaf-wise 的算法,因此在调节树的复杂程度时使用的是 num_leaves,它的值的设置应该小于 2^(max_depth)
max_depth (int__, optional (default=-1)) – Maximum tree depth for base learners, -1 means no limit.
每个基学习器的最大深度。当模型过拟合,首先降低max_depth
learning_rate (float__, optional (default=0.1)) – Boosting learning rate.
梯度下降的步长。常用 0.1, 0.001, 0.003
n_estimators (int__, optional (default=10)) – Number of boosted trees to fit.
基学习器的数量
max_bin (int__, optional (default=255)) – Number of bucketed bins for feature values.
存储feature的bin的最大数量,对应的是直方图的组数k
subsample_for_bin (int__, optional (default=50000)) – Number of samples for constructing bins.
用来构建直方图的数据的样本数量
objective (string__, callable or None__, optional (default=None)) – Specify the learning task and the corresponding learning objective or a custom objective function to be used (see note below). default: ‘regression’ for LGBMRegressor, ‘binary’ or ‘multiclass’ for LGBMClassifier, ‘lambdarank’ for LGBMRanker.
min_split_gain(= min_gain_to_split) (float__, optional (default=0.)) – Minimum loss reduction required to make a further partition on a leaf node of the tree.
最小切分的信息增益值
min_child_weight(= min_sum_hessian_in_leaf) (float__, optional (default=1e-3)) – Minimum sum of instance weight(hessian) needed in a child(leaf).
决定最小叶子节点样本权重和(hessian)的最小阈值,若是基学习器切分后得到的叶节点中样本权重和低于该阈值则不会进一步切分,在线性模型中该阈值就对应每个节点的最小样本数。当它的值较大时,可以避免模型学习到局部的特殊样本,防止模型过拟合。但如果这个值过高,又会导致欠拟合
min_child_samples(= min_data_in_leaf) (int__, optional (default=20)) – Minimum number of data need in a child(leaf).
一个叶子节点中最小的数据量,调大可以防止过拟合
subsample (= bagging_fraction)(float__, optional (default=1.)) – Subsample ratio of the training instance.
这个参数控制对于每棵树,在非重复采样的情况下随机采样的比例。减小这个参数的值算法会更加保守,避免过拟合,加快运算速度。但是这个值设置的过小,它可能会导致欠拟合
subsample_freq(= bagging_freq) (int__, optional (default=1)) – Frequence of subsample, <=0 means no enable.
bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
colsample_bytree(= feature_fraction) (float__, optional (default=1.)) – Subsample ratio of columns when constructing each tree.
用来控制每棵随机采样的列数的占比(每一列是一个特征)。 调小可以防止过拟合,加快运算速度。典型值:0.5-1范围: (0,1]。一般设置成0.8左右。
reg_alpha(= lambda_l1)(float__, optional (default=0.)) – L1 regularization term on weights.
L1 正则化项的权重系数,越大模型越保守。防止过拟合,提高泛化能力
reg_lambda(= lambda_l2) (float__, optional (default=0.)) – L2 regularization term on weights.
L2 正则化项的权重系数,越大模型越保守。防止过拟合,提高泛化能力
random_state (int or None__, optional (default=None)) – Random number seed. Will use default seeds in c++ code if set to None.
计算机不能产生绝对的随机数,只能产生伪随机数。伪就是有规律的意思。如果每次使用一样的 随机种子,生成的随机数列就是一样的了
n_jobs (int__, optional (default=-1)) – Number of parallel threads.
多线程,表示可以在机器的多个核上并行的构造树以及计算预测值。不过受限于通信成本,可能效率并不会说分为k个线程就得到k倍的提升,不过整体而言相对需要构造大量的树或者构建一棵复杂的树而言还是高效的
silent (bool__, optional (default=True)) – Whether to print messages while running boosting.
在运行过程中是否打印流程
防止过拟合的方法

LightGBM的算法在获得比较好的效果的同时,也比较容易出现一些过拟合的现象,因此在这里列了很多在实践当中大家可以用来调节来防止过拟合现象的一些方法,其中比较有用的其实是我们时间当中用的比较多的也是第三个和第五个啊,尤其是feature上做一些sample,可以大大的提高模型的推广性。另外,如果在多个LightGBM模型做融合的时候,可以利用类似的方法,就是让每一个GBDT做sample的方式都不同,这样融合出来的结果也会更好。
实例代码
#5折交叉验证
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
Folds=5
kf=KFold(n_splits=Folds,shuffle=True,random_state=2019)
#记录训练和预测MSE
MSE_DICT={'train_mse':[],'test_mse':[]}
#线下训练模型
for i,(train_index,test_index) in enumerate(kf.split(X)):
#LGB树模型
lgb_reg=lgb.LGBMRegressor(
learning_rate=0.1,
max_depth=-1,
n_estimators=5000,
boosting_type='gbdt',
random_state=2019,
objective='regression',
)
#切分训练集和预测集
X_train_KFold=X[train_index]
X_test_KFold=X[test_index]
y_train_KFold=y[train_index]
y_test_KFold=y[test_index]
#训练模型
lgb_reg.fit(X=X_train_KFold,
y=y_train_KFold,
eval_set=[(X_train_KFold,y_train_KFold),
(X_test_KFold,y_test_KFold)],
eval_names=['Train','Test'],
early_stopping_rounds=100,
eval_metric='MSE',
verbose=50)
#训练集和测试集预测
y_train_KFold_predict=lgb_reg.predict(
X_train_KFold,num_iteration=lgb_reg.best_iteration_)
y_test_KFold_predict=lgb_reg.predict(
X_test_KFold,num_iteration=lgb_reg.best_iteration_)
print('第{}折 训练和预测 训练MSE 预测MSE'.format(i))
train_mse=mean_squared_error(y_train_KFold_predict,y_train_KFold)
print('------\n','训练MSE\n',train_mse,'\n------')
test_mse=mean_squared_error(y_test_KFold_predict,y_test_KFold)
print('------\n','预测MSE\n',test_mse,'\n------\n')
MSE_DICT['train_mse'].append(train_mse)
MSE_DICT['test_mse'].append(test_mse)
pass
print('------\n','训练MSE\n',MSE_DICT['train_mse'],'\n',np.mean(MSE_DICT['train_mse']),'\n------')
print('------\n','预测MSE\n',MSE_DICT['test_mse'],'\n',np.mean(MSE_DICT['test_mse']),'\n------')