【PTM】Transformer-XL:捕捉超长上下文依赖
今天学习的是谷歌大脑的同学和 CMU 的同学于 2019 年联合出品的论文《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》,目前被引次数超 200 次。
这篇论文提出的 Transformer-XL 主要是针对 Transformer 在解决长依赖问题中受到固定长度上下文的限制,如 Bert 采用的 Transformer 最大上下文为 512。
Transformer-XL 采用了一种 segment-level 的递归方法,不仅解决长以来的问题,还解决了上下文碎片问题。最终,Transformer-XL 能学习到的长依赖超过 LSTM 80%,并比原来的 Transforner 多出 4.5 倍。而且 Transformer-XL 在长短序列中都获得了不错的性能,预测速度更是比原来快了 1800 多倍。
1.Introduction
长依赖一直是序列数据中比较常见的问题,尤其是 NLP 领域。Transformer 不仅在编码能力上超越了 LSTM,而且其对长距离依赖的建模能力还比 LSTM 强。Transformer 的 Attention 机制理论上可以在任意两个词之间建立联系,但由于效率原因,在实际使用过程中每次都会限制固定长度的上下文输入,这种固定长度的上下文有两个缺点:
- 没法捕捉超出最大长度的依赖问题;
- 固定长度的输入忽略了句子的边界和语义的边界,特别是对于基于 token 的英文单词来说。
模型因缺乏必要的上下文信息而很好的预测 token,这种问题有一个专业的名词:上下文碎片(context fragmentation)。
为了解决这种问题,作者提出了 Transformer-XL(XL 表示 extra long)模型,并在两个改进方法:
- 片段级递归机制:由于隐藏层状态包含了片段的其相关信息,通过建立循环链接,重用先前片段的隐藏层状态使得建模长依赖关系成为可能(类似 RNN),同时也解决了上下文碎片的问题。
- 相对位置编码:相对编码可以在不引起 time step 混乱的情况下实现状态重用。
接下来我们看 Transformer-XL 的详细内容。
2.Transformer-XL
2.1 Vanilla Transformer
要想将 Transformer 应用到模型中,要解决的核心问题是如何训练 Transformer 使其可以将任意大小的上下文编码为固定大小的 Representation。
如果不考虑计算资源和内存的话,最简单粗暴的方法就是直接使用 Transformer 来对整个序列进行编码。但我们知道这种方法是不可能的。
还有一种可行但是比较粗糙的方法是将整个语料库分为多个大小相同的片段(segment),然后只在每个片段上训练而忽视所有的上下文信息,这种方法我们称为 Vanilla Transformer:
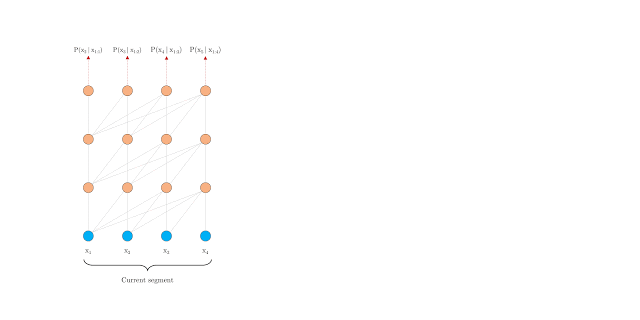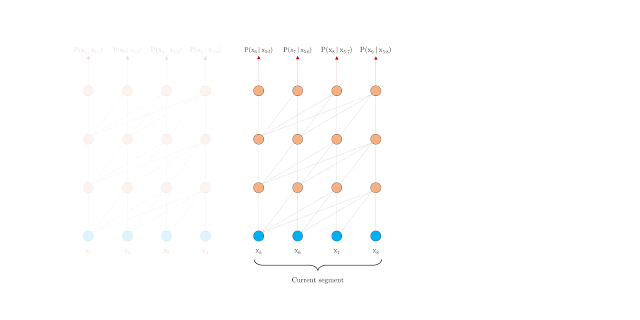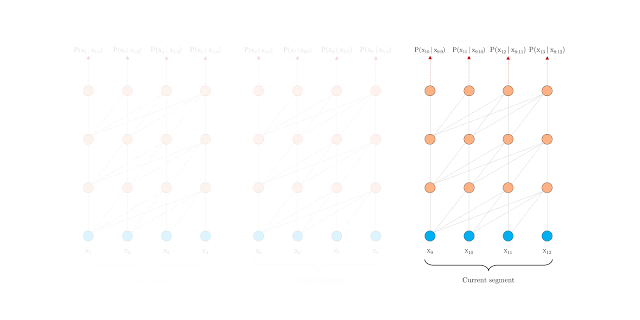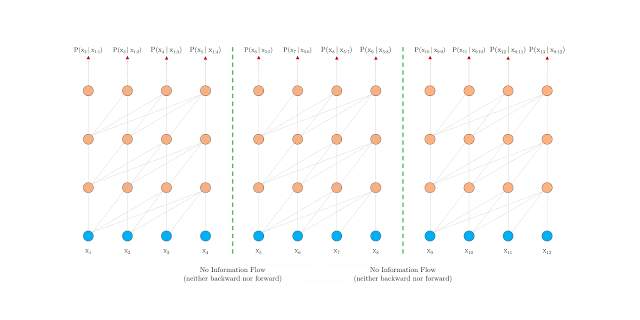
在预测过程中,Vanilla Transformer 也采用与训练相同大小的片段来预测最后一个位置,然后每次基于滑动窗口向右移动一个位置:

这种方法一定程度上确保了在预测过程中尽可能大的利用上下文,缓解了上下文碎片问题,但由于每次移动,新的片段都需要重新计算一次,所以其计算代价昂贵。
2.2 Segment-Level Recurrence
为了解决固定长度上下文的带来的问题,作者建议在 Transformer 架构中引入递归机制(Recurrence Mechanism)。在训练过程中,前一段计算出来的隐藏层状态会被被固定并缓存下来,当模型处理下一个新段时作为扩展上下文而被重用:
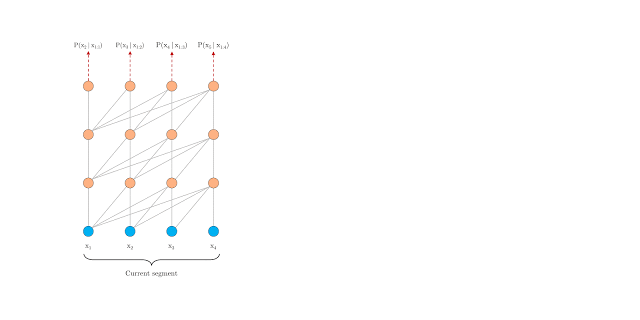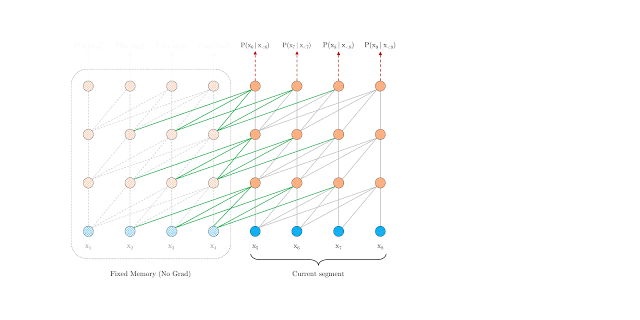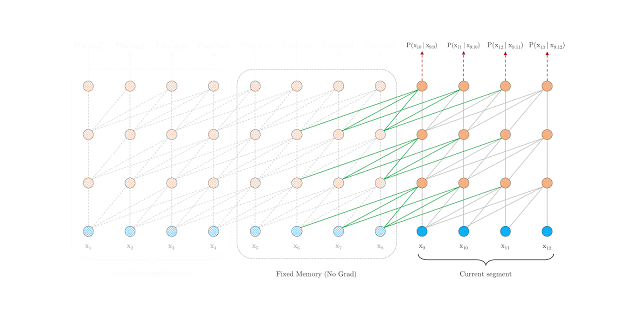
这种附加的连接可以随着网络深度的增加而增大依赖项的最大长度(想不通的可以想一下 GCN 的一阶领域)。除此之外,这种递归机制还可以解决上下文碎片问题,为新段前端的令牌提供必要的上下文信息。
又到了痛苦的时刻,我们来给出具体计算过程的数学公式:
假设现在有两个连续的分割片段 s τ = [ x τ , 1 , ⋯ , x τ , L ] s_{\tau}=\left[x_{\tau, 1}, \cdots, x_{\tau, L}\right] sτ=[xτ,1,⋯,xτ,L] 和 s τ + 1 = [ x τ + 1 , 1 , ⋯ , x τ + 1 , L ] s_{\tau+1}=\left[x_{\tau+1,1}, \cdots, x_{\tau+1, L}\right] sτ+1=[xτ+1,1,⋯,xτ+1,L],其中 x 表示 token,L 为序列长度, s τ s_{\tau} sτ 表示第 τ \tau τ 个分割片段。
假设 Transformer 有 N 层,那么每个片段 s τ s_\tau sτ 就有 N 个隐藏层状态,我们将第 τ \tau τ 个片段的第 n 个隐藏层状态表示为 h τ n h_\tau^n hτn, 那么第 τ + 1 \tau+1 τ+1 个片段的第 n 层隐藏层状态就可以通过下式得出:
h ~ τ + 1 n − 1 = [ S G ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n − 1 W q ⊤ , h ~ τ + 1 n − 1 W k ⊤ , h ~ τ + 1 n − 1 W v ⊤ h τ + 1 n = Transformer-Layer ( q τ + 1 n , k τ + 1 n , v τ + 1 n ) \widetilde{h}_{\tau+1}^{n-1}=\left[SG\left(h_{\tau}^{n-1}\right) \circ h_{\tau+1}^{n-1}\right]\\ q_{\tau+1}^{n}, k_{\tau+1}^{n}, v_{\tau+1}^{n}=h_{\tau+1}^{n-1} W_{q}^{\top}, \tilde{h}_{\tau+1}^{n-1} W_{k}^{\top}, \widetilde{h}_{\tau+1}^{n-1} W_{v}^{\top}\\ h_{\tau+1}^{n}=\text { Transformer-Layer }\left(q_{\tau+1}^{n}, k_{\tau+1}^{n}, v_{\tau+1}^{n}\right)\\ h τ+1n−1=[SG(hτn−1)∘hτ+1n−1]qτ+1n,kτ+1n,vτ+1n=hτ+1n−1Wq⊤,h~τ+1n−1Wk⊤,h τ+1n−1Wv⊤hτ+1n= Transformer-Layer (qτ+1n,kτ+1n,vτ+1n)
其中,SG 是指 Stop-Gradient,表示状态固定,虽然提供信息但不再进行反向传播; h ~ τ + 1 n − 1 \widetilde{h}_{\tau+1}^{n-1} h τ+1n−1 是一个临时符号,表示对两个连续片段第 n − 1 n-1 n−1 层隐藏层状态的拼接, q τ n , k τ n , v τ n q_\tau^n, k_\tau^n, v_\tau^n qτn,kτn,vτn 分别表示 query、key 和 value 向量;注意,仔细看下公式,query 的计算方式不变,而 key 和 value 是利用拼接后的 h ~ \widetilde{h} h 来计算。
由于这是递归机制,所以层数越高,所能依赖到的范围越大,最大可能依赖长度为 O ( N × L ) O(N\times L) O(N×L),如下图阴影部分所示:
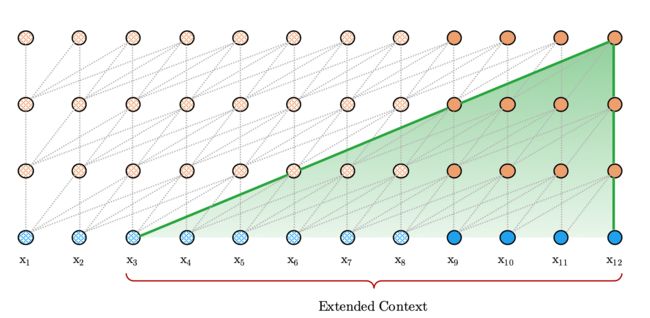
除了实现超长的上下文依赖和解决碎片问题外,递归机制的另一个好处就是显著加快了计算速度。具体来说,Vanilla Transformer 每次都需要重新计算,而现在可以重用以前的片段,只要 GPU 内存允许,我们可以尽可能多的缓存之前的片段,并重用之前的片段以作为额外的上下文。
2.3 Relative Positional Encoding
在 Vanilla Transformer 中,由于每个片段相互独立每次都会重新计算,且使用了绝对位置编码的方式,所以不会出现位置混乱的情况。但是在 Transformer-XL 中,每个片段都是用相同的位置编码会导致在重用过程中无法保证位置信息的一致性。
为了去避免这种情况,Transformer-XL 使用了相对位置信息编码的方式,从概念上来说,位置编码会为模型提供 token 相对顺序的线索。为了达到同样的目的,Transformer 在计算当前位置隐向量时,考虑和它存在依赖的 token 的相对位置。具体来说,在计算 Attention 评分时不需要知道 Query 和 key 的绝对位置,只要知道相对位置即可,并将这种相对位置关系动态的注入到每一层的 Attention 评分计算中,而不是静态地将偏差加入到初始 Embedding 中。
我们来对比一下绝对位置和相对位置:
A i , j a b s = q i ⊤ k j = ( E x i + U i ) ⊤ W q ⊤ W k ( E x j + U j ) = E x i ⊤ W q ⊤ W k E x j + E x i ⊤ W q ⊤ W k U j + U i ⊤ W q ⊤ W k E x j + U i ⊤ W q ⊤ W k U j \begin{aligned} {A}_{i, j}^{{abs}}=q_{i}^{\top} k_{j} &= (E_{x_i}+U_i)^{\top} W_q^{\top} W_k (E_{x_j}+U_j) \\ &={{E}_{x_{i}}^{\top} {W}_{q}^{\top} {W}_{k} {E}_{x_{j}}} + {{E}_{x_{i}}^{\top} {W}_{q}^{\top} {W}_{k} {U}_{j}} + {{U}_{i}^{\top} {W}_{q}^{\top} {W}_{k} {E}_{x_{j}}}+{{U}_{i}^{\top} {W}_{q}^{\top} {W}_{k} {U}_{j}}\\ \end{aligned} Ai,jabs=qi⊤kj=(Exi+Ui)⊤Wq⊤Wk(Exj+Uj)=Exi⊤Wq⊤WkExj+Exi⊤Wq⊤WkUj+Ui⊤Wq⊤WkExj+Ui⊤Wq⊤WkUj
其中, E x i E_{x_i} Exi 为 token x i x_i xi 的输入编码; U i U_i Ui 为绝对位置编码; W q , W k W_q,W_k Wq,Wk 分别为 query 和 key 矩阵。
A i , j r e l = E x i ⊤ W q ⊤ W k , E E x j ⏟ ( a ) + E x i ⊤ W q ⊤ W k , R R i − j ⏟ ( b ) + u ⊤ W k , E E x j ⏟ ( c ) + v ⊤ W k , R R i − j ⏟ ( d ) {A}_{i, j}^{{rel}}=\underbrace{{E}_{x_{i}}^{\top} {W}_{q}^{\top} {W}_{k, E} {E}_{x_{j}}}_{(a)}+\underbrace{{E}_{x_{i}}^{\top} {W}_{q}^{\top} {W}_{k, R} {R}_{i-j}}_{(b)}+\underbrace{u^{\top} {W}_{k, E} {E}_{x_{j}}}_{(c)}+\underbrace{v^{\top} {W}_{k, R} {R}_{i-j}}_{(d)}\\ Ai,jrel=(a) Exi⊤Wq⊤Wk,EExj+(b) Exi⊤Wq⊤Wk,RRi−j+(c) u⊤Wk,EExj+(d) v⊤Wk,RRi−j
其中, R i − j R_{i-j} Ri−j 是相对位置编码矩阵;由于query 向量对于所有查询位置都是相同的,所以用 u T u^T uT 代替 U i T W q T U_i^TW_q^T UiTWqT,同样的原因,我们用 v T v^T vT 代替 U i T W q T U_i^TW_q^T UiTWqT;将 W k W_k Wk 用 W k , E , W k , R W_{k,E},W_{k,R} Wk,E,Wk,R 分别代替,以细分表示基于内容的 key 向量和基于位置信息的 key 向量。
在相对位置中,每个位置都有直观的含义:
- (a)编码相邻内容的影响;
- (b)编码与相邻内容相关的位置偏差;
- ©编码全局内容偏差;
- (d)编码全局位置偏差。
Vanilla Transformer 只有前两种含义,而没有后两种含义。
最后我们来看下整体的公式:
h ~ τ + 1 n − 1 = [ S G ( h τ n − 1 ) ∘ h τ + 1 n − 1 ] q τ + 1 n , k τ + 1 n , v τ + 1 n = h τ + 1 n − 1 W q ⊤ , h ~ τ + 1 n − 1 W k ⊤ , h ~ τ + 1 n − 1 W v ⊤ A τ , i , j n = q τ , i n T k τ , j n + q τ , i n T W k , R n R i − j + u T k τ , j + v T W k , R n R i − j a τ n = Masked-Softmax ( A τ n ) v τ n o τ n = LayerNorm ( Linear ( a τ n ) + h τ n − 1 ) h τ n = Positionwise-Feed-Forward ( o τ n ) \begin{aligned} \widetilde{h}_{\tau+1}^{n-1} &=\left[SG\left(h_{\tau}^{n-1}\right) \circ h_{\tau+1}^{n-1}\right]\\ q_{\tau+1}^{n}, k_{\tau+1}^{n}, v_{\tau+1}^{n}&=h_{\tau+1}^{n-1} W_{q}^{\top}, \tilde{h}_{\tau+1}^{n-1} W_{k}^{\top}, \widetilde{h}_{\tau+1}^{n-1} W_{v}^{\top}\\ A_{\tau,i,j}^n &= {q_{\tau,i}^n}^Tk_{\tau,j}^n + {q_{\tau,i}^n}^TW_{k,R}^nR_{i-j} + {u}^Tk_{\tau,j} + {v}^TW_{k,R}^nR_{i-j} \\ a_{\tau}^n &= \text {Masked-Softmax}(A_{\tau}^n)v_{\tau}^n \\ o_{\tau}^n &= \text{LayerNorm}(\text{Linear}(a_{\tau}^n) + h_{\tau}^{n-1}) \\ h_{\tau}^n &= \text{Positionwise-Feed-Forward}(o_{\tau}^n) \\ \end{aligned} h τ+1n−1qτ+1n,kτ+1n,vτ+1nAτ,i,jnaτnoτnhτn=[SG(hτn−1)∘hτ+1n−1]=hτ+1n−1Wq⊤,h~τ+1n−1Wk⊤,h τ+1n−1Wv⊤=qτ,inTkτ,jn+qτ,inTWk,RnRi−j+uTkτ,j+vTWk,RnRi−j=Masked-Softmax(Aτn)vτn=LayerNorm(Linear(aτn)+hτn−1)=Positionwise-Feed-Forward(oτn)
3.Experiments
简单看一下实验部分。
模型在不同数据集下的表现:


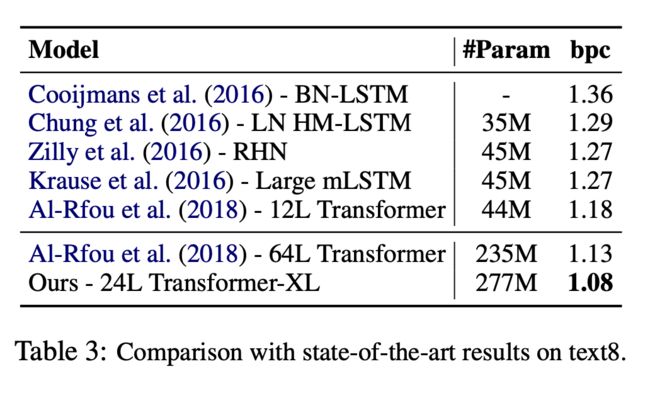
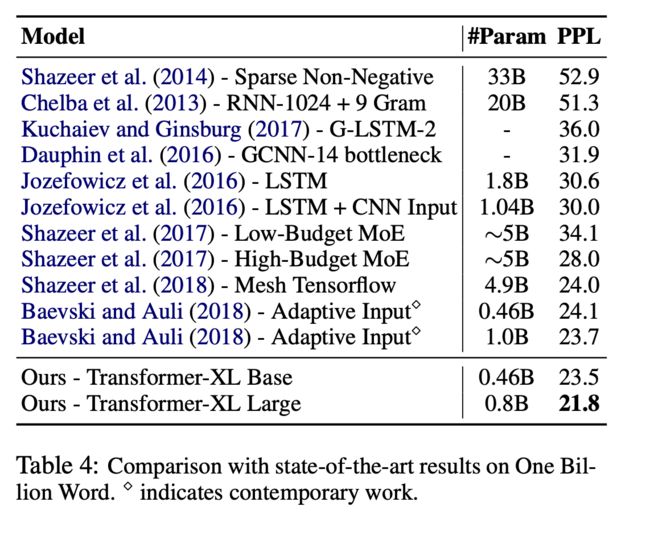


各模型的相对有效长度(最长依赖长度)

4.Conclusion
总结:Transformer-XL 从解决长距离依赖问题出来,提出了循环机制和相对位置编码这两个创新点,在解决了长依赖问题的同时也解决了上下文碎片的问题。此外,由于循环机制重用了先前隐藏层状态,其预测速度也得到了显著提升。诸多试验证明,Transformer-XL 相对 Vanilla Transformer 而言具有很好的性能。
5.Reference
- 《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
- 《Transformer-XL: Unleashing the Potential of Attention Models》
关注公众号跟踪最新内容:阿泽的学习笔记。
