【论文翻译】Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild
Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild
野外目标的小样本目标检测与视点估计
论文地址:https://arxiv.org/pdf/2007.12107v1.pdf
代码地址:GitHub - YoungXIAO13/FewShotDetection: (ECCV 2020) PyTorch implementation of paper "Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild"
摘要
Detecting objects and estimating their viewpoint in images are key tasks of 3D scene understanding. Recent approaches have achieved excellent results on very large benchmarks for object detection and viewpoint estimation. However, performances are still lagging behind for novel object categories with few samples. In this paper, we tackle the problems of few-shot object detection and few-shot viewpoint estimation. We propose a meta-learning framework that can be applied to both tasks, possibly including 3D data. Our models improve the results on objects of novel classes by leveraging on rich feature information originating from base classes with many samples. A simple joint feature embedding module is proposed to make the most of this feature sharing. Despite its simplicity, our method outperforms state-ofthe-art methods by a large margin on a range of datasets, including PASCAL VOC and MS COCO for few-shot object detection, and Pascal3D+ and ObjectNet3D for few-shot viewpoint estimation. And for the first time, we tackle the combination of both few-shot tasks, on ObjectNet3D, showing promising results. Our code and data are available at http://imagine.enpc.fr/~xiaoy/FSDetView/.
在图像中检测物体并估计其视点是三维场景理解的关键任务。最近的方法在目标检测和视点估计的大型基准上取得了优异的结果。然而,对于样本较少的新目标类别,性能仍然落后。本文主要研究少样本目标检测和少样本视点估计问题。我们提出了一个元学习框架,可以应用于这两项任务,可能包括3D数据。我们的模型通过利用来自多个样本基类的丰富特征信息,改进了新类目标的结果。提出了一个简单的联合特征嵌入模块来充分利用这种特征共享。尽管简单,但我们的方法在一系列数据集上都比最先进的方法有很大优势,包括PASCAL VOC和MS COCO用于少样本目标检测,Pascal3D+和ObjectNet3D用于少样本视点估计。这是我们第一次在ObjectNet3D上处理这两种少样本任务的组合,显示了有希望的结果。我们的代码和数据可在http://imagine.enpc.fr/~xiaoy/FSDetView/。
1 介绍
Detecting objects in 2D images and estimate their 3D pose, as shown in Fig. 1, is extremely useful for tasks such as 3D scene understanding, augmented reality and robot manipulation. With the emergence of large databases annotated with object bounding boxes and viewpoints, deep-learning-based methods have achieved very good results on both tasks. However these methods, that rely on rich labeled data, usually fail to generalize to novel object categories when only a few annotated samples are available. Transferring the knowledge learned from large base categories with abundant annotated images to novel categories with scarce annotated samples is a few-shot learning problem.
如图1所示,在2D图像中检测目标并估计其3D姿势对于3D场景理解、增强现实和机器人操作等任务非常有用。随着带有目标边界框和视点注释的大型数据库的出现,基于深度学习的方法在这两项任务上都取得了很好的效果。然而,这些方法依赖于丰富的标记数据,当只有少数注释样本可用时,通常无法推广到新的目标类别。将从具有丰富注释图像的大型基础类别中学习到的知识转移到具有稀少注释样本的新类别中是一个简单的少样本学习问题。

Fig. 1. Few-shot object detection and viewpoint estimation. Starting with images labeled with bounding boxes and viewpoints of objects from base classes, and given only a few similarly labeled images for new categories (top), we predict in a query image the 2D location of objects of new categories, as well as their 3D poses, leveraging on just a few arbitrary 3D class models (bottom).
图1 少样本目标检测和视点估计。从使用边界框和基类中对象的视点标记的图像开始,并且只为新类别提供了几个类似标记的图像(上图),我们在查询图像中预测新类别目标的二维位置,以及它们的三维姿势,仅利用几个任意的三维类模型(下图)。
To address few-shot detection, some approaches simultaneously tackle fewshot classification and few-shot localization by disentangling the learning of category-agnostic and category-specific network parameters [59]. Others attach a reweighting module to existing object detection networks [23, 64]. Though these methods have made significant progress, current few-shot detection evaluation protocols suffer from statistical unreliability and the prediction depends heavily on the choice of support data, which makes direct comparison difficult [57].
为了解决少样本检测问题,一些方法通过分离类别不可知和类别特定网络参数的学习,同时解决了少样本分类和定位问题[59]。其他人则将重新称重模块连接到现有的目标检测网络[23,64]。尽管这些方法已经取得了重大进展,但目前少样本检测评估协议存在统计不可靠性,预测严重依赖于支持数据的选择,这使得直接比较困难[57]。
In parallel to the endeavours made in few-shot object detection, recent work proposes to perform category-agnostic viewpoint estimation that can be directly applied to novel object categories without retraining [65, 63]. However, these methods either require the testing categories to be similar to the training ones [65], or assume the exact CAD model to be provided for each object during inference [63]. Differently, the meta-learning-based method MetaView [53] introduces the category-level few-shot viewpoint estimation problem and addresses it by learning to estimate category-specific keypoints, requiring extra annotations. In any case, precisely annotating the 3D pose of objects in images is far more tedious than annotating their 2D bounding boxes, which makes few-shot viewpoint estimation a non-trivial yet largely under-explored problem.
在研究少样本目标检测的同时,最近的工作建议执行类别不可知的视点估计,该估计可以直接应用于新的目标类别,而无需再训练[65,63]。然而,这些方法要么要求测试类别与训练类别相似[65],要么假设在推理过程中为每个目标提供准确的CAD模型[63]。不同的是,基于元学习的方法MetaView[53]引入了类别级别的少样本视点估计问题,并通过学习估计类别特定的关键点来解决该问题,需要额外的注释。在任何情况下,精确地标注图像中对象的三维姿势都比标注其二维边界框要繁琐得多,这使得少样本视点估计成为一个非同寻常的问题,但在很大程度上还没有得到充分的研究。
In this work, we propose a consistent framework to tackle both problems of few-shot object detection and few-shot viewpoint estimation. For this, we exploit, in a meta-learning setting, task-specific class information present in existing datasets, i.e., images with bounding boxes for object detection and, for viewpoint estimation, 3D poses in images as well as a few 3D models for the different classes. Considering that these few 3D shapes are available is a realistic assumption in most scenarios. Using this information, we obtain an embedding for each class and condition the network prediction on both the class-informative embeddings and instance-wise query image embeddings through a feature aggregation module. Despite its simplicity, this approach leads to a significant performance improvement on novel classes under the few-shot learning regime.
在这项工作中,我们提出了一个一致的框架来解决少样本目标检测和少样本视点估计这两个问题。为此,我们在元学习环境中利用现有数据集中存在的特定于任务的类信息,即带有用于目标检测的边界框的图像,以及用于视点估计的图像中的三维姿势,以及不同类的一些三维模型。考虑到这几个3D形状在大多数情况下都是可用的,这是一个现实的假设。利用这些信息,我们为每个类获得一个嵌入,并通过特征聚合模块对类信息嵌入和实例查询图像嵌入进行网络预测。尽管这种方法很简单,但在少样本学习模式下,它可以显著提高新类别的性能。
Additionally, by combining our few-shot object detection with our few-shot viewpoint estimation, we address the realistic joint problem of learning to detect objects in images and to estimate their viewpoints from only a few shots. Indeed, compared to other viewpoint estimation methods, that only evaluate in the ideal case with ground-truth (GT) classes and ground-truth bounding boxes, we demonstrate that our few-shot viewpoint estimation method can achieve very good results even based on the predicted classes and bounding boxes.
此外,通过将我们的少样本目标检测与少样本视点估计相结合,我们解决了学习检测图像中的目标并仅从几个样本估计其视点的现实联合问题。事实上,与其他仅在理想情况下使用ground-truth (GT)类和地面真值边界框进行评估的视点估计方法相比,我们证明,即使基于预测的类和边界框,我们的少样本视点估计方法也可以获得非常好的结果。
To summarize, our contributions are:
~We define a simple yet effective unifying framework that tackles both fewshot object detection and few-shot viewpoint estimation.
~We show how to leverage just a few arbitrary 3D models of novel classes to guide and boost few-shot viewpoint estimation.
~Our approach achieves state-of-the-art performance on various benchmarks.
~We propose a few-shot learning evaluation of the new joint task of object detection and view-point estimation, and provide promising results.
总而言之,我们的贡献是:
~我们定义了一个简单但有效的统一框架,该框架既可以处理少样本目标检测,也可以处理少样本视点估计。
~我们展示了如何利用新类的一些任意3D模型来指导和提高少样本的视点估计。
~我们的方法在各种基准上实现了最先进的性能。
~我们对目标检测和视点估计这一新的联合任务提出了少样本学习评估,并提供了有希望的结果。
2 相关工作
Since there is a vast amount of literature on both object detection and viewpoint estimation, we focus here on recent works that target these tasks in the case of limited annotated samples.
由于有大量关于目标检测和视点估计的文献,我们在这里重点介绍在有限的注释样本情况下针对这些任务的最新工作。
Few-shot Learning. Few-shot learning refers to learning from a few labeled training samples per class, which is an important yet unsolved problem in computer vision [28, 16, 56]. One popular solution to this problem is meta-learning [25, 4, 2, 58, 56, 48, 21, 41, 14, 27, 22], where a meta-learner is designed to parameterize the optimization algorithm or predict the network parameters by "learning to learn". Instead of just focusing on the performance improvement on novel classes, some other work has been proposed for providing good results on both base and novel classes [16, 10, 38]. While most existing methods tackle the problem of few-shot image classification, we find that other few-shot learning tasks such as object detection and viewpoint estimation are under-explored.
很少有人尝试学习。少样本学习指的是每堂课从几个标记的训练样本中学习,这是计算机视觉中一个重要但尚未解决的问题[28,16,56]。这个问题的一个流行解决方案是元学习[25,4,2,58,56,48,21,41,14,27,22],元学习器被设计为通过“学会学习”来参数化优化算法或预测网络参数。除了关注新类的性能改进,还提出了一些其他工作,以在基础类和新类上都提供良好的结果[16,10,38]。虽然大多数现有方法都解决了少样本图像分类的问题,但我们发现其他少样本学习任务,如目标检测和视点估计,还没有得到充分的研究。
Object Detection. The general deep-learning models for object detection can be divided into two groups: proposal-based methods and direct methods without proposals. While the R-CNN series [12, 18, 11, 45, 17] and FPN [29] fall into the former line of work, the YOLO series [42, 43, 44] and SSD [31] belong to the latter. All these methods mainly focus on learning from abundant data to improve detection regarding accuracy and speed. Yet, there are also some attempts to solve the problem with limited labeled data. Chen et al. [15] proposes to transfer a pre-trained detector to the few-shot task, while Karlinsky et al. [46] exploits distance metric learning to model a multi-modal distribution of each object class.
目标检测。用于目标检测的一般深度学习模型可分为两类:基于提议的方法和无提议的直接方法。R-CNN系列[12,18,11,45,17]和FPN[29]属于前者,而YOLO系列[42,43,44]和SSD[31]属于后者。所有这些方法主要侧重于从丰富的数据中学习,以提高检测的准确性和速度。然而,也有人试图用有限的标记数据来解决这个问题。Chen等人[15]建议将预先训练好的检测器转移到少数镜头任务中,而Karlinsky等人[46]利用距离度量学习对每个对象类的多模态分布建模。
Viewpoint Estimation. Deep-learning methods for viewpoint estimation follow roughly three different paths: direct estimation of Euler angles [55, 50, 33,24, 62, 63], template-based matching [20, 32, 51], and keypoint detection relying on 3D bounding box corners [39, 52, 13, 34, 36] or semantic keypoints [35, 65].
视点估计。视点估计的深度学习方法大致遵循三种不同的路径:直接估计欧拉角[55,50,33,24,62,63],基于模板的匹配[20,32,51],以及依赖3D边界框角[39,52,13,34,36]或语义关键点[35,65]的关键点检测。
Most of the existing viewpoint estimation methods are designed for known object categories or instances; very little work reports performance on unseen classes [54, 65, 36, 53, 63]. Zhou et al. [65] propose a category-agnostic method to learn general keypoints for both seen and unseen objects, while Xiao et al. [63] show that better results can be obtained when exact 3D models of the objects are additionally provided. In contrast to these category-agnostic methods, Tseng et al. [53] specifically address the few-shot scenario by training a category-specific viewpoint estimation network for novel classes with limited samples.
现有的大多数视点估计方法都是针对已知的目标类别或实例设计的;很少有工作报告未知类别的表现[54,65,36,53,63]。Zhou等人[65]提出了一种类别不可知的方法来学习可见和不可见目标的一般关键点,而Xiao等人[63]表明,如果额外提供目标的精确3D模型,可以获得更好的结果。与这些类别不可知的方法不同,Tseng等人[53]通过为样本有限的新类别训练特定于类别的视点估计网络,专门解决了少样本场景。
Instead of using exact 3D object models as [63], we propose a meta-learning approach to extract a class-informative canonical shape feature vector for each novel class from a few labeled samples, with random object models. Besides, our network can be applied to both base and novel classes without changing the network architecture, while [53] requires a separate meta-training procedure for each class and needs keypoint annotations in addition to the viewpoint.
我们提出了一种元学习方法,用随机目标模型从几个标记样本中为每个新类提取类信息规范形状特征向量,而不是像[63]那样使用精确的三维目标模型。此外,我们的网络可以在不改变网络结构的情况下应用于基本类和新类,而[53]要求每个类都有单独的元训练过程,并且除了视点之外还需要关键点注释。
3 方法
In this section, we first introduce the setup for few-shot object detection and few-shot viewpoint estimation (Sect. 3.1). Then we describe our common network architecture for these two tasks (Sect. 3.2) and the learning procedure (Sect. 3.3).
在本节中,我们首先介绍少样本目标检测和少样本视点估计的设置(第3.1节)。然后,我们描述了这两项任务(第3.2节)和学习过程(第3.3节)的通用网络架构。
3.1 Few-shot Learning Setup
We have training samples ![]() for our two tasks, and a few 3D shapes.
for our two tasks, and a few 3D shapes.
- For object detection, x is an image, ![]() indicates theclass label clsi and bounding box boxi of each object i in the image.
indicates theclass label clsi and bounding box boxi of each object i in the image.
- For viewpoint estimation, x = (cls; box; img) represents an object of class cls(x) pictured in bounding box box(x) of an image img(x), y = ang =(azi; ele; inp) is the 3D pose (viewpoint) of the object, given by Euler angles.-
我们有两个任务的训练样本![]() 和一些3D形状。
和一些3D形状。
-对于目标检测,x是一个图像,![]() 表示图像中每个目标i的类标签clsi和边界框boxi。
表示图像中每个目标i的类标签clsi和边界框boxi。
-对于视点估计,x=(cls,box,img)表示图像的边框框(x)中所示的类别cls(x)的目标,y=ang=(azi,ele,inp)是目标的三维姿势(视点),由欧拉角给出
For each class![]() , we consider a set Zc of class data(see Fig. 2) to learn from using meta-learning:
, we consider a set Zc of class data(see Fig. 2) to learn from using meta-learning:
- For object detection, ![]() is made of images x plus an extra channel with a binary mask for bounding box boxi of
is made of images x plus an extra channel with a binary mask for bounding box boxi of ![]() .
.
- For viewpoint estimation, Zc is an additional set of 3D models of class c.
对于每个类![]() ,我们考虑一组Zc类数据(见图2)来使用元学习进行学习:
,我们考虑一组Zc类数据(见图2)来使用元学习进行学习:
-对于目标检测,![]() 由图像x加上一个额外通道组成,该通道带有一个二进制掩码,用于
由图像x加上一个额外通道组成,该通道带有一个二进制掩码,用于![]() 的包围框boxi。
的包围框boxi。
-对于视点估计,Zc是一组附加的类c的3D模型。
At each training iteration, class data zc is randomly sampled in Zc for each c ∈ C.
In the few-shot setting, we have a partition of the classes C = Cbase ∪ Cnovel with many samples for base classes in Cbase and only a few samples (including shapes) for novel classes in Cnovel. The goal is to transfer the knowledge learned on base classes with abundant samples to little-represented novel classes.
在每个训练迭代中,类数据zc在zc中为每个c∈ C随机抽样
在少样本设置中,我们对类C=Cbase∪Cnovel进行了划分,其中Cbase中的基类有许多样本,Cnovel中的新类只有少数样本(包括形状)。目标是将在具有大量样本的基类上学习到的知识转移到代表性较小的新类。

3.2 Network Description
Our general approach has three steps that are visualized in Fig 3. First, query data x and class-informative data zc pass respectively through the query encoder Fqry and the class encoder Fcls to generate corresponding feature vectors. Next, a feature aggregation module A combines the query features with the class features. Finally, the output of the network is obtained by passing the aggregated features through a task-specific predictor P:
- For object detection, the predictor estimates a classification score and an object location for each region of interest (RoI) and each class.
- For viewpoint estimation, the predictor selects quantized angles by classification, that are refined using regressed angular offsets.
我们的一般方法有三个步骤,如图3所示。首先,查询数据x和类信息数据zc分别通过查询编码器Fqry和类编码器Fcls生成相应的特征向量。接下来,特征聚合模块a将查询特征与类特征相结合。最后,通过将聚合的特征传递给特定于任务的预测器P,获得网络的输出:
-对于目标检测,预测器估计每个感兴趣区域(RoI)和每个类别的分类分数和目标位置。
-对于视点估计,预测器通过分类选择量化的角度,这些角度使用回归的角度偏移进行细化。

Fig. 3. Method overview.
(a) For object detection, we sample for each class c one image x in the training set containing an object j of class c, to which we add an extra channel for the binary mask maskj of the ground-truth bounding box boxj of object j. Each corresponding vector of class featuresis then combined with each vector of query features
associated to one of the region of interest i in the query image, via an aggregation module. Finally, the aggregated features
pass through a predictor that estimates a class probability
and regresses a bounding box
.
(b) For few-shot viewpoint estimation, class information is extracted from a few point clouds with coordinates in normalized object canonical space, and the output of the network is the 3D pose represented by three Euler angles图3 方法概述。
(a) 对于目标检测,我们在包含c类目标j的训练集中为每个c类目标采样一个图像x,在此基础上,我们为目标j的ground-truth边界框boxj的二元掩码maskj添加了一个额外通道。然后,通过聚合模块,将类别特征(b) 对于少样本视点估计,从标准化对象规范空间中具有坐标的几个点云中提取类别信息,网络的输出是由三个欧拉角表示的三维姿态
Few-shot object detection. We adopt the widely-used Faster R-CNN [45] approach in our few-shot object detection network (see Fig. 3(a)). The query encoder Fqry includes the backbone, the region proposal network (RPN) and the proposal-level feature alignment module. In parallel, the class encoder Fcls is here simply the backbone sharing the same weights as Fqry, that extracts the class features from RGB images sampled in each class, with an extra channel for a binary mask of the object bounding box [23, 64]. Each extracted vector of query features is aggregated with each extracted vector of class features before being processed for class classification and bounding box regression:
少样本目标检测。在我们的少样本目标检测网络中,我们采用了广泛使用的Faster R-CNN[45]方法(见图3(a))。查询编码器Fqry包括主干网、区域建议网络(RPN)和建议级特征对齐模块。同时,类编码器Fcls在这里只是与Fqry共享相同权重的主干,它从每个类中采样的RGB图像中提取类特征,并为对象边界框的二进制掩码提供额外通道[23,64]。查询特征的每个提取向量与类特征的每个提取向量聚合,然后再进行类分类和边界框回归处理:
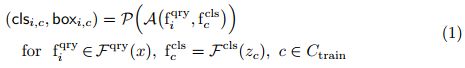
where Ctrain is the set of all training classes, and where ![]() are the predicted classification scores and object locations for the ith RoI in query image x and for class c. The prediction branch in Faster R-CNN is class-specific: the network outputs Ntrain =|Ctrain| classification scores and Ntrain box regressions for each RoI. The final predictions are obtained by concatenating all the classwise network outputs.
are the predicted classification scores and object locations for the ith RoI in query image x and for class c. The prediction branch in Faster R-CNN is class-specific: the network outputs Ntrain =|Ctrain| classification scores and Ntrain box regressions for each RoI. The final predictions are obtained by concatenating all the classwise network outputs.
其中Ctrain是所有培训课程的集合,而![]() 是查询图像x中第i个RoI和c类的预测分类分数和目标位置。快速R-CNN中的预测分支是特定于类的:网络为每个RoI输出Ntrain=|Ctrain|分类分数和Ntrain盒回归。最终的预测是通过连接所有的类网络输出得到的。
是查询图像x中第i个RoI和c类的预测分类分数和目标位置。快速R-CNN中的预测分支是特定于类的:网络为每个RoI输出Ntrain=|Ctrain|分类分数和Ntrain盒回归。最终的预测是通过连接所有的类网络输出得到的。
Few-shot viewpoint estimation. For few-shot viewpoint estimation, we rely on the recently proposed PoseFromShape [63] architecture to implement our network. To create class data zc, we transform the 3D models in the dataset into point clouds by uniformly sampling points on the surface, with coordinates in the normalized object canonical space. The query encoder Fqry and class encoder Fcls (cf. Fig. 3(b)) correspond respectively to the image encoder ResNet-18 [19] and shape encoder PointNet [37] in PoseFromShape. By aggregating the query features and class features, we estimate the three Euler angles using a three-layer fully-connected (FC) sub-network as the predictor:
少样本视点估计。对于少样本视点估计,我们依靠最近提出的PoseFromShape[63]体系结构来实现我们的网络。为了创建类数据zc,我们通过对曲面上的点进行均匀采样,将数据集中的三维模型转换为点云,坐标位于标准化对象规范空间中。查询编码器Fqry和类编码器Fcls(参见图3(b))分别对应于PoseFromShape中的图像编码器ResNet-18[19]和形状编码器PointNet[37]。通过聚合查询特征和类特征,我们使用一个三层完全连接(FC)子网络作为预测器来估计三个欧拉角:

where crop(img(x); box(x)) indicates that the query features are extracted from the image patch after cropping the object. Unlike the object detection making a prediction for each class and aggregating them together to obtain the final outputs, here we only make the viewpoint prediction for the object class cls(x) by passing the corresponding class data through the network. We also use the mixed classification-and-regression viewpoint estimator of [63]: the output consists of angular bin classification scores and within-bin offsets for three Euler angles: azimuth (azi), elevation (ele), and in-plane rotation (inp).
其中作物(img(x),box(x))表示在裁剪目标后从图像面片中提取查询特征。与目标检测不同的是,对每个类进行预测并将它们聚合在一起以获得最终输出,这里我们只通过通过网络传递相应的类数据来对目标类cls(x)进行视点预测。我们还使用了[63]中的混合分类和回归视点估计器:输出包括三个欧拉角的角度仓位分类分数和仓位内偏移:方位角(azi)、仰角(ele)和平面内旋转(inp)。
Feature aggregation. In recent few-shot object detection methods such as MetaYOLO [23] and Meta R-CNN [64], feature are aggregated by reweighting the query features fqry according to the output fcls of the class encoder Fcls:
功能聚合。在最近的少样本目标检测方法中,如MetaYOLO[23]和Meta R-CNN[64],通过根据类编码器fcls的输出fcls重新加权查询特征fqry来聚合特征:
![]()
where ⊗ represents channel-wise multiplication and fqry has the same number of channels as fcls. By jointly training the query encoder Fqry and the class encoder Fcls with this reweighting module, it is possible to learn to generate meaningful reweighting vectors fcls. (Fqry and Fcls actually share their weights, except the first layer [64].)
⊗ 表示按通道乘法,fqry的通道数与fcls相同。通过使用该重新加权模块联合训练查询编码器Fqry和类编码器FCL,可以学习生成有意义的重新加权向量FCL。(除第一层[64]外,Fqry和FCL实际上共享其权重。)
We choose to rely on a slightly more complex aggregation scheme. The fact is that feature subtraction is a different but also effective way to measure similarity between image features [1, 26]. The image embedding fqry itself, without any reweighting, contains relevant information too. Our aggregation thus concatenates the three forms of the query feature:
我们选择依赖稍微复杂一点的聚合方案。事实上,特征减法是测量图像特征之间相似性的一种不同但也是有效的方法[1,26]。嵌入fqry的图像本身也包含相关信息,无需重新加权。因此,我们的聚合将三种形式的查询功能连接起来:
![]()
where [·, ·, ·] represents channel-wise concatenation. The last part of the aggregated features in Eq. (4) is independent of the class data. As observed experimentally (Sect. 4.1), this partial disentanglement does not only improve few-shot detection performance, it also reduces the variation introduced by the randomness of support samples.
其中,[·,·,·]表示通道连接。等式(4)中聚合特征的最后一部分独立于类数据。正如实验观察到的(第4.1节),这种部分解纠缠不仅提高了少样本检测性能,还减少了由支持样本的随机性引入的变化。
3.3 Learning Procedure
The learning consists of two phases: base-class training on many samples from base classes (Ctrain = Cbase), followed by few-shot fine-tuning on a balanced small set of samples from both base and novel classes (Ctrain = Cbase ∪ Cnovel). In both phases, we optimize the network using the same loss function.
学习过程分为两个阶段:在基础课的许多样本上进行基类训练(Ctrain=Cbase),然后对来自基本类和新类(Ctrain=Cbase)的平衡小样本集进行几次微调∪ Cnovel)。在这两个阶段中,我们使用相同的损耗函数优化网络。
Detection loss function. Following Meta R-CNN [64], we optimize our fewshot object detection network using the same loss function:
检测损失函数。根据Meta R-CNN[64],我们使用相同的损失函数优化了我们的fewshot目标检测网络:

where Lrpn is applied to the output of the RPN to distinguish foreground from background and refine the proposals, Lcls is a cross-entropy loss for box classifier, Lloc is a smoothed-L1 loss for box regression, and Lmeta is a cross-entropy loss encouraging class features to be diverse for different classes [64].
其中,Lrpn应用于RPN的输出,以区分前景和背景,并细化建议,Lcls是框分类器的交叉熵损失,Lloc是边界框回归的平滑-L1损失,Lmeta是鼓励不同类别的类别特征多样化的交叉熵损失[64]。
Viewpoint loss function. For the task of viewpoint estimation, we discretize each Euler angle with a bin size of 15 degrees and use the same loss function as PoseFromShape [63] to train the network:
视点损失函数。对于视点估计任务,我们将每个Euler角离散为15度的面元大小,并使用与PoseFromShape[63]相同的损失函数来训练网络:
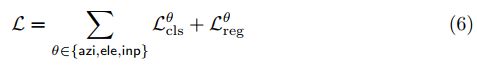
where![]() is a cross-entropy loss for angle bin classification of Euler angle θ, and
is a cross-entropy loss for angle bin classification of Euler angle θ, and ![]() is a smoothed-L1 loss for the regression of offsets relatively to bin centers. Here we remove the meta loss Lmeta used in object detection since we want the network to learn useful inter-class similarities for viewpoint estimation, instead of the inter-class differences for box classification in object detection.
is a smoothed-L1 loss for the regression of offsets relatively to bin centers. Here we remove the meta loss Lmeta used in object detection since we want the network to learn useful inter-class similarities for viewpoint estimation, instead of the inter-class differences for box classification in object detection.
其中,![]() 是欧拉角θ的角bin分类的交叉熵损失,
是欧拉角θ的角bin分类的交叉熵损失,![]() 是相对于bin中心的偏移回归的平滑-L1损失。在这里,我们删除了在目标检测中使用的元损失Lmeta,因为我们希望网络学习有用的类间相似性,用于视点估计,而不是在目标检测中用于框分类的类间差异。
是相对于bin中心的偏移回归的平滑-L1损失。在这里,我们删除了在目标检测中使用的元损失Lmeta,因为我们希望网络学习有用的类间相似性,用于视点估计,而不是在目标检测中用于框分类的类间差异。
Class data construction. For viewpoint estimation, we make use of all the 3D models available for each class (typically less than 10) during both training stages. By contrast, the class data used in object detection requires the label of object class and location, which is limited by the number of annotated samples for novel classes. Therefore, we use large number of class data for base classes in the base training stage (typically |Zc|= 200, as in Meta R-CNN [64]) and limit its size to the number of shots for both base and novel classes in the K-shot fine-tuning stage (|Zc| = K).
类别数据建设。对于视点估计,我们在两个训练阶段都使用每个类(通常少于10个)可用的所有3D模型。相比之下,用于目标检测的类数据需要目标类和位置的标签,这受到新类的注释样本数量的限制。因此,我们在基本训练阶段(通常为| Zc |=200,如Meta R-CNN[64])使用大量的基类数据,并将其大小限制为K-shot微调阶段(|Zc |=K)中的基类和新类的样本数量。
For inference, after learning is finished, we construct once and for all class features, instead of randomly sampling class data from the dataset, as done during training. For each class c, we average all corresponding class features used in the few-shot fine-tuning stage:
对于推理,在学习完成后,我们构建一次性的类特征,而不是像训练期间那样从数据集中随机抽样类数据。对于每一个c类,我们平均了在少样本微调阶段使用的所有相应的类特征:
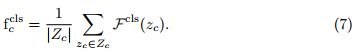
This corresponds to the offline computation of all red feature vectors in Fig. 3(a)
这对应于图3(a)中所有红色特征向量的离线计算
4 实验
In this section, we evaluate our approach and compare it with state-of-the-art methods on various benchmarks for few-shot object detection and few-shot viewpoint estimation. For a fair comparison, we use the same splits between base and novel classes [23, 53]. For all the experiments, we run 10 trials with random support data and report the average performance
在本节中,我们将对我们的方法进行评估,并将其与各种基准上的最新方法进行比较,以实现少样本目标检测和少样本视点估计。为了进行公平比较,我们在基本类和新类之间使用了相同的划分[23,53]。对于所有实验,我们使用随机支持数据进行了10次试验,并报告了平均性能。
Experimental setup. PASCAL VOC 2007 and 2012 consist of 16.5k train-val images and 5k test images covering 20 categories. Consistent with the few-shot learning setup in [23, 59, 64], we use VOC 07 and 12 train-val sets for training and VOC 07 test set for testing. 15 classes are considered as base classes, and the remaining 5 classes as novel classes. For a fair comparison, we consider the same 3 splits as in [23, 59, 64, 57], and for each run we only draw K random shots from each novel class where K ∈{1,2,3,5,10}. We report the mean Average Precision (mAP) with intersection over union (IoU) threshold at 0.5 (AP50). For MS-COCO, we set the 20 PASCAL VOC categories as novel classes and the remaining 60 categories as base classes. Following [31, 45], we report standard COCO evaluation metrics on this dataset with K ∈{10,30}.
实验装置。PASCAL VOC 2007和2012由16.5k训练-val图像和5k测试图像组成,涵盖20个类别。与[23,59,64]中的少样本学习设置一致,我们使用VOC 07和12训练val集进行训练,使用VOC 07测试集进行测试。15个类被视为基类,其余5个类被视为新类。为了进行公平的比较,我们考虑了与[23,59,64,57]中相同的3次分割,对于每一次训练,我们只从每一个新类别中随机抽取K个样本,其中K ∈{1,2,3,5,10}。我们报告的平均精度(mAP)与联合交叉(IoU)阈值为0.5(AP50)。对于MS-COCO,我们将20个帕斯卡VOC类别设置为新类别,将其余60个类别设置为基类。在[31,45]之后,我们用K ∈{10,30}报告了该数据集的标准COCO评估指标。
Training details. We use the same learning scheme as [64], which uses the SGD optimizer with an initial learning rate of 10−3 and a batch size of 4. In the first training stage, we train for 20 epochs and divide the learning rate by 10 after each 5 epochs. In the second stage, we train for 5 epochs with learning rate of 10−3 and another 4 epochs with a learning rate of 10−4.
训练细节。我们使用与[64]相同的学习方案,该方案使用初始学习率为0.001的SGD优化器,批量为4个。在第一个训练阶段,我们训练20个阶段,每5个阶段后将学习率除以10。在第二阶段,我们训练了5个阶段,学习率为0.001和另外4个阶段,学习率为0.0001.
Quantitative results. The results are summarized in Table 1 and 2. Our method outperforms state-of-the-art methods in most cases for the 3 different dataset splits of PASCAL VOC, and it achieves the best results on the 20 novel classes of MS-COCO, which validates the efficacy and generality of our approach. Moreover, our improvements on the difficult COCO dataset (around 3 points in mAP) is much larger than the gap among previous methods. This demonstrates that our approach can generalize well to novel classes even in complex scenarios with ambiguities and occluded objects. By comparing results on objects of different sizes contained in COCO, we find that our approach obtains a much better improvement on medium and large objects while it struggles on small objects.
定量结果。结果总结在表1和表2中。对于PASCAL VOC的3种不同数据集分割,我们的方法在大多数情况下都优于最先进的方法,并且在20种新的MS-COCO类上取得了最佳结果,这验证了我们方法的有效性和通用性。此外,我们对困难的COCO数据集(地图中约3个点)的改进比以前的方法之间的差距要大得多。这表明,我们的方法可以很好地推广到新类,即使在具有歧义和遮挡目标的复杂场景中也是如此。通过比较COCO中不同大小目标的结果,我们发现我们的方法在中大型目标上获得了更好的改进,而在小型目标上则难以实现。

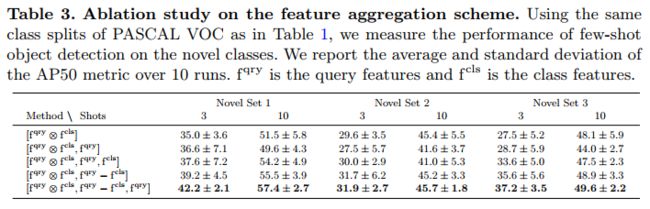
Different feature aggregations. We analyze the impact of different feature aggregation schemes. For this purpose, we evaluate K-shot object detection on PASCAL VOC with K ∈{3,10}. The results are reported in Table 3. We can see that our feature aggregation scheme ![]() yields the best precision. In particular, although the difference [fqry − fcls] could in theory be learned from the individual feature vectors [fqry- fcls], the network performs better when explicitly provided with their subtraction. Moreover, our aggregation scheme significantly reduces the variance introduced by the random sampling of few-shot support data, which is one of the main issues in few-shot learning.
yields the best precision. In particular, although the difference [fqry − fcls] could in theory be learned from the individual feature vectors [fqry- fcls], the network performs better when explicitly provided with their subtraction. Moreover, our aggregation scheme significantly reduces the variance introduced by the random sampling of few-shot support data, which is one of the main issues in few-shot learning.
不同的功能聚合。我们分析了不同特征聚合方案的影响。为此,我们使用K ∈{3,10}在PASCAL VOC上评估K-shot目标检测,结果见表3。我们可以看到,我们的功能聚合方案![]() 的精度最高。特别是,尽管理论上可以从单个特征向量[fqry,fcls]中学习差异[fqry-fcls],但当明确提供它们的减法运算时,网络的性能更好。此外,我们的聚合方案显著降低了随机抽样少样本支持数据引入的方差,这是少样本学习的主要问题之一。
的精度最高。特别是,尽管理论上可以从单个特征向量[fqry,fcls]中学习差异[fqry-fcls],但当明确提供它们的减法运算时,网络的性能更好。此外,我们的聚合方案显著降低了随机抽样少样本支持数据引入的方差,这是少样本学习的主要问题之一。
4.2 Few-Shot Viewpoint Estimation
Following the few-shot viewpoint estimation protocol proposed in [53], we evaluate our method under two settings: intra-dataset on ObjectNet3D [60] (reported in Tab. 4) and inter-dataset between ObjectNet3D and Pascal3D+ [61] (reported in Tab. 5). In both datasets, the number of available 3D models for each class vary from 2 to 16. We use the most common metrics for evaluation: Acc30, which is the percentage of estimations with a rotational error smaller than 30◦, and MedErr, which computes the median rotational error measured in degrees. Complying with previous work [65, 53], we only use the non-occluded and nontruncated objects for evaluation and assume in this subsection that the ground truth classes and bounding boxes are provided at test time.
按照[53]中提出的少样本视点估计协议,我们在两种设置下评估我们的方法:ObjectNet3D[60]上的数据集内(见表4)和ObjectNet3D和Pascal3D+[61]之间的数据集间(见表5)。在这两个数据集中,每个类别的可用3D模型数量从2个到16个不等。我们使用最常用的评估指标:Acc30,这是旋转误差小于30◦的估计百分比, 以及MedErr,它计算以度为单位的旋转误差中值。根据之前的工作[65,53],我们仅使用非遮挡和非平移目标进行评估,并在本小节中假设在测试时提供了groundtruth类和边界框。
Training details. The model is trained using the Adam optimizer with a batch size of 16. During the base-class training stage, we train for 150 epochs with a learning rate of 10−4. For few-shot fine-tuning, we train for 50 epochs with learning rate of 10−4 and another 50 epochs with a learning rate of 10−5.
训练细节。使用批量为16的Adam优化器对模型进行训练。在基础类训练阶段,我们进行了150个阶段的训练,学习率为10%−4.对于少样本微调,我们训练50个阶段,学习率为10−4和另外50个时代,学习率为10−5.
Compared methods. For few-shot viewpoint estimation, we compare our method to MetaView [53] and to two adaptations of StarMap [65]. More precisely, the authors of MetaView [53] re-implemented StarMap with one stage of ResNet-18 as the backbone, and trained the network with MAML [9] for a fair comparison in the few-shot regime (entries StarMap+M in Tab. 4-5). They also provided StarMap results by just fine-tuning it on the novel classes using the scarce labeled data (entries StarMap+F in Tab. 4-5)
比较方法。对于少样本视点估计,我们将我们的方法与MetaView[53]和StarMap[65]的两种修改进行比较。更准确地说,MetaView[53]的作者用一个阶段的ResNet-18作为主干重新实现了StarMap,并用MAML[9]对网络进行了训练,以便在少数镜头情况下进行公平比较(表4-5中的StarMap+M)。他们还提供了星图结果,只需使用稀少的标记数据对新类进行微调(表4-5中的StarMap+F)
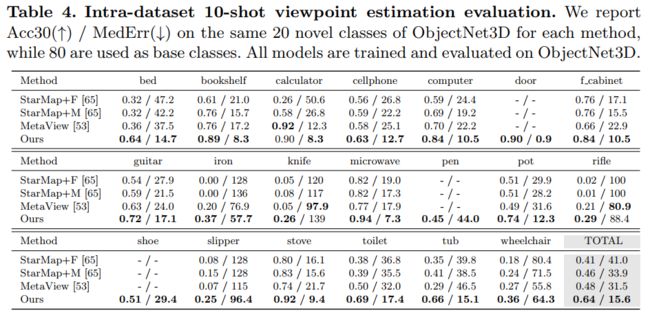

Intra-dataset evaluation. We follow the protocol of [53, 63] and split the 100 categories of ObjectNet3D into 80 base classes and 20 novel classes. As shown in Table 4, our model outperforms the recently proposed meta-learningbased method MetaView [53] by a very large margin in overall performance: +16 points in Acc30 and half MedErr (from 31:5◦ down to 15:6◦). Besides, keypoint annotations are not available for some object categories such as door, pen and shoe in ObjectNet3D. This limits the generalization of keypoint-based approaches [65, 53] as they require a set of manually labeled keypoints for network training. By contrast, our model can be trained and evaluated on all object classes of ObjectNet3D as we only rely on the shape pose. More importantly, our model can be directly deployed on different classes using the same architecture, while MetaView learns a set of separate category-specific semantic keypoint detectors for each class. This flexibility suggests that our approach is likely to exploit the similarities between different categories (e.g., bicycle and motorbike) and has more potentials for applications to robotics and augmented reality.
数据集内评估。我们遵循[53,63]的协议,将ObjectNet3D的100个类别划分为80个基类和20个新类。如表4所示,我们的模型在整体性能方面比最近提出的基于元学习的方法MetaView[53]有很大的优势:在Acc30和half MedErr中+16点(从31.5◦降到15.6◦). 此外,在ObjectNet3D中,某些目标类别(如门、笔和鞋)无法使用关键点注释。这限制了基于关键点的方法的推广[65,53],因为它们需要一组手动标记的关键点用于网络训练。相比之下,我们的模型可以在ObjectNet3D的所有目标类上进行训练和评估,因为我们只依赖于形状姿势。更重要的是,我们的模型可以使用相同的体系结构直接部署到不同的类上,而MetaView为每个类学习一组单独的特定于类别的语义关键点检测器。这种灵活性表明,我们的方法很可能利用不同类别(如自行车和摩托车)之间的相似性,并在机器人和增强现实方面具有更大的应用潜力。
As shown in Tab. 5, our approach again significantly outperforms StarMap and MetaView. Our overall improvement in inter-dataset evaluation is even larger than in intra-dataset evaluation: we gain +19 points in Acc30 and again divide MedErr by about 2 (from 51:3◦ down to 28:3◦). This indicates that our approach, by leveraging viewpoint-relevant 3D information, not only helps the network generalize to novel classes from the same domain, but also addresses the domain shift issues when trained and evaluated on different datasets.
如表5所示,我们的方法再次显著优于星图和元视图。我们在数据集间评估方面的整体改进甚至大于数据集内评估:我们在Acc30中获得+19分,再次将MedErr除以约2(从51.3◦ 降到28.3◦). 这表明,通过利用视点相关的3D信息,我们的方法不仅有助于网络从同一领域推广到新的类,而且还解决了在不同数据集上进行训练和评估时的领域转移问题。
Visual results. We provide in Fig. 4 visualizations of viewpoint estimation for novel objects on ObjectNet3D and Pascal3D+. We show both success (green boxes) and failure cases (red boxes) to help analyze possible error types. We visualize four categories giving the largest median errors: iron, knife, rifle and slipper for ObjectNet3D, and aeroplane, bicycle, boat and chair for Pascal3D+. The most common failure cases come from objects with similar appearances in ambiguous poses, e.g., iron and knife in ObjectNet3D, aeroplane and boat in Pascal3D+. Other failure cases include the heavy clutter cases (bicycle) and large shape variations between training objects and testing objects (chair).
视觉效果。我们在图4中提供了ObjectNet3D和Pascal3D+上新对象的视点估计可视化。我们展示了成功案例(绿色方框)和失败案例(红色方框),以帮助分析可能的错误类型。我们设想了四个中位误差最大的类别:ObjectNet3D的铁、刀、步枪和拖鞋,Pascal3D+的飞机、自行车、船和椅子。最常见的故障案例来自于在模糊姿势下具有相似外观的对象,例如ObjectNet3D中的铁和刀,Pascal3D+中的飞机和船。其他失败案例包括严重的杂乱情况(自行车)以及训练对象和测试对象(椅子)之间的巨大形状变化。

Fig. 4. Qualitative results of few-shot viewpoint estimation. We visualize results on ObjectNet3D and Pascal3D+. For each category, we show three success cases (the first six columns) and one failure case (the last two columns). CAD models are shown here only for the purpose of illustrating the estimated viewpoint.
图4 少样本视点估计的定性结果。我们在ObjectNet3D和Pascal3D+上可视化结果。对于每个类别,我们展示了三个成功案例(前六列)和一个失败案例(后两列)。此处显示的CAD模型仅用于说明估计的视点。
4.3 Evaluation of Joint Detection and Viewpoint Estimation
To further show the generality of our approach in real-world scenarios, we consider the joint problem of detecting objects from novel classes in images and estimating their viewpoints. The fact is that evaluating a viewpoint estimator on ground-truth classes and bounding boxes is a toy setting, not representative of actual needs. On the contrary, estimating viewpoints based on predicted detections is much more realistic and challenging.
为了进一步展示我们的方法在现实场景中的通用性,我们考虑了从图像中的新类中检测目标并估计其视点的联合问题。事实上,在地面真值类和边界框上评估视点估计器是一种玩具设置,不能代表实际需求。相反,基于预测检测的视角估计更现实、更具挑战性。
To experiment with this scenario, we split ObjectNet3D into 80 base classes and 20 novel classes as in Sect. 4.2, and train the object detector and viewpoint estimator based on the abundant annotated samples for base classes and scarce labeled samples for novel classes. Unfortunately, the codes of StarMap+F/M and MetaView are not available. The only available information is the results on perfect, ground-truth classes and bounding boxes available in publications. We thus have to reason relatively in terms of baselines. Concretely, we compare these results obtained on ideal input to the case where we use predicted classes and bounding boxes, in the 10-shot scenario. As an upper bound, we also consider the “all-shot” case where all training data of the novel classes are used.
为了试验这个场景,我们将ObjectNet3D拆分为80个基类和20个新类,并基于丰富的基类注释样本和稀少的新类标记样本训练目标检测器和视点估计器,如4.2所示。不幸的是,星图+F/M和元视图的代码不可用。唯一可用的信息是出版物中关于完美、基本真理类和边界框的结果。因此,我们必须根据基线进行相对的推理。具体地说,我们将这些在理想输入下获得的结果与我们在10-shot场景中使用预测类和边界框的情况进行比较。作为一个上限,我们还考虑了“all-shot”的情况,其中使用了新类的所有训练数据。
As recalled in Tab. 6, our few-shot viewpoint estimation outperforms other methods by a large margin when evaluated using ground-truth classes and bounding boxes in the 10-shot setting. When using predicted classes and bounding boxes, accuracy drops for most categories. One explanation is that viewpoint estimation becomes difficult when the objects are truncated by imperfect predicted bounding boxes, especially for tiny objects (e.g., shoes) and ambiguous objects with similar appearances in different poses (e.g., knifes, rifles). Yet, by comparing the performance gap between our method when tested using predicted classes and boxes and MetaView when tested using ground-truth classes and boxes, we find that our approach is able to reach the same viewpoint accuracy of 48%, which is a considerable achievement.
如表6中所述,当在10-shot设置中使用地面真值类和边界框进行评估时,我们的少样本视点估计比其他方法有很大的优势。当使用预测类和边界框时,大多数类别的精度都会下降。一种解释是,当对象被不完美的预测边界框截断时,视点估计变得很困难,尤其是对于小目标(例如鞋子)和在不同姿势下具有相似外观的模糊目标(例如刀子、步枪)。然而,通过比较我们的方法在使用预测类和框进行测试时的性能差距,以及在使用地面真相类和框进行测试时的MetaView,我们发现我们的方法能够达到48%的相同视点精度,这是一个相当大的成就。

5 结论
In this work, we presented an approach to few-shot object detection and viewpoint estimation that can tackle both tasks in a coherent and efficient framework. We demonstrated the benefits of this approach in terms of accuracy, and significantly improved the state of the art on several standard benchmarks for few-shot object detection and few-shot viewpoint estimation. Moreover, we showed that our few-shot viewpoint estimation model can achieve promising results on the novel objects detected by our few-shot detection model, compared to the existing methods tested with ground-truth bounding boxes.
在这项工作中,我们提出了一种少样本目标检测和视点估计的方法,可以在一个连贯有效的框架内处理这两项任务。我们展示了这种方法在准确性方面的优势,并在几个标准基准上显著提高了少样本目标检测和少镜头视点估计的技术水平。此外,我们还证明了我们的少样本视点估计模型可以在通过我们的少样本检测模型检测到的新目标上取得令人满意的结果,与使用ground-truth边界框测试的现有方法相比。