基于模型的强化学习笔记


[6] [model-based] Survey on MBRL - 知乎 (zhihu.com)
关于环境模型(world model)的学习 - 知乎
论文地址
1.Overview of Model-based RL
具有高样本复杂度的RL算法很难直接应用于现实世界的任务中,因为在这些任务中,试错代价很高。深度强化学习研究的一个主要重点是提高样本效率,基于模型的强化学习(MBRL)是最重要的方向。
看了老师推荐的书马尔可夫决策过程
在MBRL中,环境模型(或简称为模型)指的是学习代理与之交互的环境动态的抽象。
经验数据:智能体只能使用从与真实环境的交互中采样的数据
仿真数据:有了环境模型,智能体就有了想象的能力。它可以与模型进行交互,以便对交互数据进行采样
利用经验数据
1.MBRL方法使智能体能够充分利用学习模型中的经验数据
MBRL显式地学习一个模型。与off-policy算法相比,MBRL重构了状态转移的动态过程,而策略外RL只是简单地使用重放缓冲区来更稳健地估计值。虽然价值函数或批评的计算涉及到转移动力学的信息,但MBRL中的学习模型与策略解耦,因此可以用于评估其他策略,价值函数与抽样策略绑定。
2.off-policy算法:使用回放缓冲区来记录旧数据
3.actor-critic 算法:学习一个批评者来促进策略更新

不同类型的RL结构
on-policy:代理使用最新的数据来更新策略
off-policy:代理在重放缓冲区中收集历史数据,学习策略
actor-critic :代理人学习批评家,批评家是长期回报的价值函数,然后学习批评家辅助的政策(行动者)。
对于模型学习,我们从经典的表格表示模型开始,然后对近似模型如使用神经网络,我们回顾了理论和关键挑战时,面对复杂的环境,以及减少模型误差的进展。对于模型的使用,我们将文献分为两部分,即用于轨迹采样的黑箱模型rollout和用于梯度传播的白箱模型。将模型使用作为模型学习的后续任务,我们还讨论了在模型学习和模型使用之间建立桥梁的尝试,即价值意识模型学习和政策意识模型学习。此外,我们简要回顾了基于模型的方法在其他形式的强化学习中的组合,包括离线强化学习、目标条件强化学习、多智能体强化学习和元强化学习。我们还讨论了MBRL在现实任务中的适用性和优势。最后,我们对MBRL的研究前景和未来发展趋势进行了展望
2.模型学习
2.1表格设置中的模型学习
表格设置下的最大似然估计(maximum likelihood estimation, MLE)ˆM和ˆR分别是真实的转场∗和真实的奖励函数∗的无偏估计,因此当样本接近无穷大时,它们会收敛为M∗和R∗。


R-MAX 是联合模型学习和探索的代表性算法。在R-MAX中,状态转移到自身,即时奖励默认设置为最大值,但只有当一个状态-动作对被访问的次数足够多,即大于K时,将转移概率和奖励赋给它们的平均值。


2.2通过预测损失进行模型学习
虽然表格式MDPs设置下的计数方法和模型学习理论很清楚,但对于大规模MDPs以及具有连续状态空间和动作空间的MDPs,使用表格表示是不可行的。一般情况下都采用近似函数。近似函数可以由机器学习模型实现,如线性模型、神经网络、决策树模型等.重点研究了神经网络模型。
2.2.1预测模型的损失

metric by value 度量价值
2.2.2模型属性
定理1和定理2所采用的预测损失最小化了状态-动作数据每一点上的模型误差。虽然预测损失最小化可以通过监督学习直接解决,但过渡的长期影响很难捕捉,导致水平平方复合误差问题。
仿真引理simulation lemma

仿真引理表明,模型误差对应的值损失在有效视界1 1−γ上具有二次系数。这意味着,随着视界的增长,价值损失以二次曲线的速度增长。
仿真引理也表明,与模型误差相比,奖励误差并不严重。
simulation lemma II
省略了奖励函数错误,因为它不是必要的

不等式右边称为 compounding error,复合误差,随着 gamma 趋近于 1 而二次增大。所以 rollout 不能很长。
为了解决这个问题,又有很多变种方法,比如 multi-step prediction,backward prediction,但是不尽如人意。
2.2.3模型变量
(确定性)多步模型

2.3减少误差的模型学习
为了解决 compounding error 问题,文章又介绍了三种方法。
2.3.1具有Lipschitz连续性约束的模型学习
为了减少复合误差,一种方法是对模型进行约束,
Wasserstein距离:

Wasserstein距离可以适当地度量两个不相交支持分布之间的相似性
generalized transition model:

n-step error:
![]()
在概率跃迁模型中引入了Lipschitz连续性

2.3.2基于分布匹配的模型学习
为了学习过渡的长期影响,一个想法是匹配真实轨迹和学习模型中铺开的轨迹之间的分布
第二种思路是基于 distribution matching 的思想,不再用 prediction loss 了,而是匹配 real trajectories 和 trajectories rolled out in learned model。更出名的是 GAIL,利用对抗的思想取模仿专家策略,判别器试图分辨一个状态动作对是否来自专家演示,一个生成器通过最大化判别器分数来模仿专家策略。当判别器最优时,最终等价于最小化 JS 散度。
![]()
![]()
Duel MDP 将环境也视为一个 agent,将![]() 看成策略,这个策略以 state,action 为输入,next-state 为输出。这里判别器区分的就是state-action-next-state 三元组
看成策略,这个策略以 state,action 为输入,next-state 为输出。这里判别器区分的就是state-action-next-state 三元组
![]()
![]()
根据 distribution Matching 的思想,同样可以推导出一个 error bound。

2.3.3鲁棒模型学习
第三种方法是为了在上述基础上解决 policy 项的二次 error bound,思路是在一个 policy distribution上训练。仿真引理III中,复合误差减小,但策略在π上的分歧项仍然很大。
![]()
2.4复杂环境动力学模型学习
部分可观测性。
表示学习。
POMDP belief estimation 和 representation learning,感觉二者某种意义上还挺像的,注明的比如 Dreamer,DreamerV2。
3.模型的使用和与模型学习的集成
3.1用模型仿真进行规划
当一个模型可用时,使用该模型的最直接的想法是在其中进行规划。规划指的是将模型作为输入,产生或改进与模型环境交互的策略的任何计算过程。我们将列出将规划集成到其方法或框架中的MBRL方法。我们将根据它们采用的规划方法对这些方法进行分类。
最直接的应用model的方法就是planning,有了模型之后,我们面临一个状态时,就可以利用这个环境模型做planning,比如说planning N 步,我们希望什么样的 N step actions 使这 N 步的 return 最大。这实际上就是 Model predictive control (MPC)

这里面如果求 optimization 就是最大的问题,直接 MC 可以,通过随机取 actions 找到最大的那一组,这样效率极低。将 MC 方法替换,就有了 CEM,PETS,PlaNet等方法。
另一种方法是蒙特卡洛树搜索( MCTS),它的优化目标和 MPC 一样,但是用树搜索的方式来做优化,每一个结点都会被赋予一个评估值,可能是用近似的价值函数,也可能是用在model中rollout得到的return代表。AlphaGo,VPN,Muzero都应用了这种技术。Value prediction network (VPN)
VPN学习了一个抽象状态转移模型,以当前的抽象状态和动作为输入,推断下一个抽象状态,与典型MDP中的转移函数相同。但是,抽象状态没有对应状态的语义。抽象转换模型的目的是将抽象状态转换为可以用来做出更精确的价值和奖励预测的抽象状态。因此,给定一个动作序列,VPN可以将该动作序列传递给环境后,预测未来状态的奖励和状态值。VPN将MCTS应用到学习的模型中,以搜索具有最高引导环境返回值的操作序列。通过抽象的过渡模型,VPN可以应用于观察图像的任务,如atari游戏
MCTS 和 MPC 都是 决策时间规划decision-time planning,即当面临一个新状态时开始并完成规划,然后选择动作。除此之外的方法称为 background planning,利用模型获得的模拟数据来改进政策或价值学习,例如动态规划,表格式Dyna,优先扫描。
VIN它实现了一种动态规划方法,值迭代(VI)和神经网络
3.2增强数据用模型模拟
Data Augmentation with Model Simulation
从模型中获得的模拟经验介绍价值学习和政策学习
Dyna-style model,通过学习到的 model 来生成 simulated data,然后用这些data 来做 value learning (MVE,STEVE) 和 policy learning(ME-TRPO-----SLBO(变体),MBPO)。
价值学习
近似状态值的方法:
1.蒙特卡洛(Monte Carlo, MC)值估计
2.时域差分(TD)预测:与MC方法相比,一步TD方法不需要环境模型,是许多无模型方法的首选方法
3.Model-based V value Expansion, MVE),表明h阶TD值预测在一定条件下可以降低值估计误差
定理六:

STEVE扩展MVE:通过基于集合计算的不确定性在不同视界H之间插值,进一步改进了MVE。它根据不同深度的价值目标的不确定性对其重新加权
策略学习
1.模型集成信任区域策略优化(ME-TRPO)
该模型增强的数据也可用于无模型的RL方法,用于政策改进

2.随机下界优化(SLBO)
可以将其视为ME-TRPO的一种变体。作者抛弃了第一项w.r.t的梯度,对模型进行了近似
3. 基于模型的策略优化(MBPO)
采用了一种off-policy RL算法——Soft Actor-Critic,利用来自真实环境和学习模型的混合数据来更新策略, an off-policy RL algorithm
4.bidirectional model-based policy optimization(BMPO)
 5. Masked Model-based Actor-Critic (M2AC)
5. Masked Model-based Actor-Critic (M2AC)
通过丢弃不确定性高的样本,可以选择更长的推出长度来更好地利用模型
模型学习和无模型RL结合起来。这些方法有一个令人印象深刻的性能,以及一个理论范围。因此,动态式算法在MBRL领域引起了广泛的研究兴趣。这些方法的一个共同和重要的问题是如何处理或减轻复合误差。如何利用模型生成更可靠的数据,如何更好地利用想象数据,仍然是有待解决的问题。
3.3梯度生成与白盒模型仿真
之前的model都看成是black box了,但是很多 model 是可微分的(differentiable) 的,因此我们可以利用模型的内部结构来帮助策略的学习。这里也分成两个类别,一是 差别规划differential planning (LQR, iLQR, GPS, UPN)。另一类称为 value gradient (PILCO, SVG)。
差别规划
线性二次调节器(LQR):研究了动态是线性的,奖励是二次的MDP
迭代LQR (iLQR):非线性模型线性化
引导政策搜索(GPS)使用iLQR从白盒模型中抽取样本
通用规划网络(UPN)


CEN
价值梯度
政策梯度也可以通过白盒模型传递。学习控制的概率推理(PILCO)通过高斯过程建立动态模型
stochastic value gradient (SVG)随机策略梯度

每个状态st0都可以通过递归调用动态函数
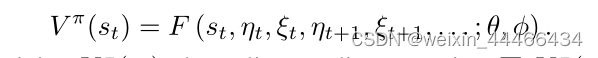
MAAC模型增强的行动者-评论家(MAAC)
3.4价值—意识和政策—意识模型学习
价值感知模型学习(value-aware model learning, VAML)框架,通过将价值函数信息纳入模型学习来解决这一问题。VAML对模型进行了优化,使使用环境与模型的一步估值差异最小化:
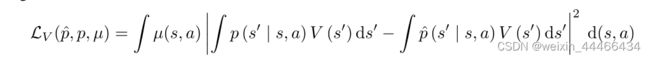
改进

4.其它RL形式中的基于模型的方法
4.1 Offline RL
代理能够直接从离线经验数据集学习有效的策略,而无需与环境动态进行任何交互
![]()
上述 L 函数是 offline RL 设计的重点。offline RL 的一个最大挑战就是 推断误差extrapolation error,学习到的策略和数据集中潜在的策略的不一致会导致遇到 out-of-distribution problem。model-free offline RL 会受限,使得学习到的策略过于保守。而model-based offline RL 就可以先建立一个环境模型然后在模型和数据上训练策略,以解决泛化和探索问题。问题是,往往数据集是很有限的,导致学习出的模型往往不可信。于是就产一个思路是利用学到的模型来避免 OOD 情况。(MORel, MOPO,. COMBD)。MAPLE 则是不着重于避免进入 OOD region,而是尝试 generalize。
4.2目标条件强化学习(GCRL)
处理的是agent在环境中期望实现不同目标的任务[,或通过实现一系列目标来完成复杂任务。
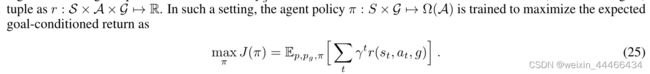
GCRL 重点在于 generated goal 的多样性,以及 goal-conditioned policy 训练的鲁棒与稳定。最经典的方法是 HER,这种方法生成 goal 也十分简单,后续有很多各种各样的生成方法,包括引入 model-based
4.3多智能体强化学习
Multi-agent reinforcement learning (MARL)
多智能体强化学习(MARL)研究一组智能体(i = 1,2,…)之间的顺序交互策略。在环境中,每个代理I都是自利的,其目标是最大化自己的收益,以期望收益为

在MARL中寻求解时的额外动态来自于多智能体博弈的非平稳性,
4.4元强化学习
使agent在目标任务中具有少量样本的不同任务之间进行泛化的方法
![]()
学习适应的基本思想已经被用来解决许多现实应用中训练和测试之间的动态差距,也被称为现实差距
Sim2Real:专注于如何将在模拟器中训练的策略转移到现实世界。在这种情况下,使用现成的模拟器可以更容易地进行模型学习。
SimGAN框架
分析模拟器和神经网络结合起来构建更真实的混合模型是很有诱惑力的,这可以无缝地利用这两个领域的创新
4.5模型学习和使用的自动化方法
自动超参数优化的MBRL方法
如何更好地将AutoML的先进技术[Hutter等人,2019]纳入MBRL是一个有前景的进一步研究方向。
5.基于模型的RL应用
MBRL能应用于现实世界,而现实世界的一个共同特点是不能容忍错误。这一特征与强化学习方法的基本机制,即试错机制相矛盾。因此,在实际应用和强化学习之间,必须有一个训练策略的运动场。操场必须具有与现实世界的高保真度和高容错能力,才能自由训练强化学习。
1.构建手工仿真器已被广泛采用
2.从数据中学习环境模型是一种更有效且更低成本的选择
优点
1.充分释放强化学习能力
2.部署前验证
最近的一项研究开始将政策外评估和基于模型的政策评估结合起来,但在模拟器/模型中运行政策可能是评估绩效的最直接方法。
3.解释决策过程
6.结论与未来发展方向
学习可泛化的model
抽象的model
利用状态和时间抽象,模型学习可以发生在低维空间中,因此成为一项容易的任务。
基于model的可泛化策略
元强化学习依赖于模型随机化,并产生一种可以推广到类似环境的元策略。元策略的泛化能力来源于模型的变化。然而,如何生成模型使训练好的元策略适应目标环境的问题在很大程度上被忽略了
基于model的多智能体RL
结合基于模型的方法来改善团队代理之间的协调和提高训练的样本效率是很有潜力的。
基础模型model
通过学习单一的政策模型,这种范式也在决策任务中发生转变
