论文阅读:RepPoints: Point Set Representation for Object Detection
文章目录
- 1、论文总述
- 2、Bounding boxes for the object detection流行的2个原因和它的缺点
- 3、为什么 the deformable convolution and deformable RoI pooling不能学到更精确的几何定位特征
- 4、Converting RepPoints to bounding box时的三种方式
- 5、关键点是自动学得的
- 6、 Center point based initial object representation的好处、缺点与改进
- 7、Utilization of RepPoints(RepPoints学得过程)
- 8、The head architecture of RPDet
- 9、正负样本的分配(两个阶段不一样)
- 10、Ablation of the supervision sources
- 11、 Comparison of the proposed method (RPDet) with other methods
- 参考文献
1、论文总述
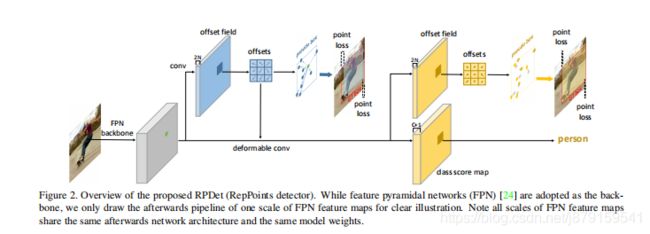
这篇论文是清北和微软研究院联合出的关于anchor free的目标检测的文章,感觉质量很高,不同于其他的anchor free算法(如CornerNet),文章说它是 Top_down方式的检测,而CornerNet是 bottom_up的检测,即先检测出关键点(角点),然后对他们进行分组(一个目标的分成一组),算法某种意义上说是DCN(Deformable Convolutional Networks ,可变形卷积网络)的改进,因为可变形卷积主要是可以更好地提取目标面部特征进行识别,但是它不能很好的提取目标的几何特征进行定位,这也是文章中强调的一点,因此RepPoints和DCN是互补,一个更好地定位,另一个更好地识别。
论文算法具体思路:backbone是resnet+fpn(并没有用关键点检测效果比较好的沙漏网络),首先训练时候标注是目标的中心点,根据可变形卷积以及左上角点和右下角点的smoothL1损失回归出第一阶段的关键点(一般为9个,相对于中心点的偏移offset),接着用这9个点根据转换函数产生一个box,用第一阶段的box根据标签来进行目标识别的训练;最后是第二阶段的定位损失训练,即对第一阶段得到的9个点继续回归再次得到offset,产生更加精确的定位。
【注】:识别损失会促进第一阶段的offset的偏移的训练。
监督信息还是一个框和类别标签。
两次定位损失函数应该都是smoothL1损失函数,论文中没有具体说明。
In this paper, we propose a new representation, called
RepPoints, that provides more fine-grained localization and
facilitates classification. Illustrated in Fig. 1, RepPoints is
a set of points that learns to adaptively position themselves
over an object in a manner that circumscribes the object’s
spatial extent and indicates semantically significant local
areas. The training of RepPoints is driven jointly by object localization and recognition targets, such that the RepPoints are tightly bound by the ground-truth bounding box
and guide the detector toward correct object classification.
This adaptive and differentiable representation can be coherently used across the different stages of a modern object
detector, and does not require the use of anchors to sample
over a space of bounding boxes.
有点疑惑:
In contrast, RepPoints are learned in a
top-down fashion from the input image / object features, allowing for end-to-end training and producing fine-grained
localization without additional supervision(具体这个topdown是怎么个方式我也没搞明白,为什么这里检测出来的点不用分组?难道是一个中心点后面对应了9个关键点的坐标??)
2、Bounding boxes for the object detection流行的2个原因和它的缺点
原因:
The prevalence of the bounding box representation can
partly be attributed to common metrics for object detection
performance, which account for the overlap between estimated and ground truth bounding boxes of objects. (由于目标检测性能评估的标准)
Another reason lies in its convenience for feature extraction in deep
networks, because of its regular shape and the ease of subdividing a rectangular window into a matrix of pooled cells.
缺点:
Though bounding boxes facilitate computation, they provide only a coarse localization of objects that does not conform to an object’s shape and pose. Features extracted from
the regular cells of a bounding box may thus be heavily
influenced by background content or uninformative foreground areas that contain little semantic information. This
may result in lower feature quality that degrades classification performance in object detection.
(定位不准,提取特征时容易被框内的不是目标的背景信息所影响)
别走,还有俩缺点:
This bounding box regression process is widely used in
existing object detection methods. It performs well in practice when the required refinement is small, but it tends to
perform poorly when there is large distance between the initial representation and the target. (回归的距离太大时表现不好,对大目标和小目标效果不一样)
Another issue lies in the scale difference between ∆x, ∆y and ∆w, ∆h, which requires tuning of their loss weights for optimal performance.(四个参数权重不一样)
3、为什么 the deformable convolution and deformable RoI pooling不能学到更精确的几何定位特征
提出问题:
RepPoints is inspired by these works, especially the topdown deformation modeling approach [4]. The main difference is that we aim at developing a flexible object representation for accurate geometric localization in addition to semantic feature extraction.
In contrast, both the deformable
convolution and deformable RoI pooling methods are designed to improve feature extraction only. The inability of deformable RoI pooling to learn accurate geometric localization is examined in Section 4 and appendix. In this sense,
we expand the usage of adaptive sample points in previous
geometric modeling methods [18, 4] to include finer localization of objects.(改进了DCN来更好地定位)
进一步提出问题:
As mentioned in Section 2, deformable RoI pooling plays a different role
in object detection compared to the proposed RepPoints.
Basically, RepPoints is a geometric representation of objects, reflecting more accurate semantic localization, while
deformable RoI pooling is geared towards learning stronger
appearance features of objects. In fact, deformable RoI
pooling cannot learn sample points representing accurate
localization of objects (please see the appendix for a proof).
We also note that deformable RoI pooling can be complementary to RepPoints, as indicated in Table 6.(两者互补,各有各的优势)
两者互补的数据证明:
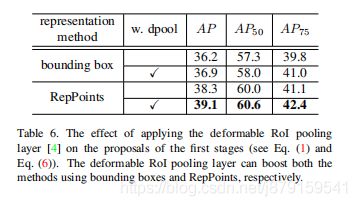
deformable RoI pooling cannot learn the geometric representation of objects的证明:(在附录)

4、Converting RepPoints to bounding box时的三种方式
• T = T1: Min-max function. Min-max operation over
both axes are performed over the RepPoints to determine Bp, equivalent to the bounding box over the sample points.(默认用这个)
• T = T2: Partial min-max function. Min-max operation over a subset of the sample points is performed over both axes to obtain the rectangular box Bp.
• T = T3: Moment-based function. The mean value
and the standard deviation of the RepPoints is used to
compute the center point and scale of the rectangular box Bp, where the scale is multiplied by globallyshared learnable multipliers λx and λy. (三种方式效果差不多,下图是实验证明)
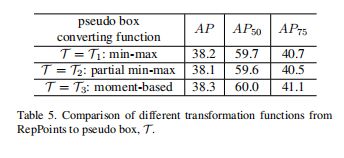
5、关键点是自动学得的
In our system, we use the
smooth l1 distance between the top-left and bottom-right
points to represent the localization loss. This smooth l1 distance does not require the tuning of different loss weights
as done in computing the distance between bounding box
regression vectors (i.e., for ∆x, ∆y and ∆w, ∆h).
Figure 4 indicates that when the training is driven by this combination of object localization and object recognition losses, the
extreme points and semantic key points of objects are automatically learned

6、 Center point based initial object representation的好处、缺点与改进
好处:
An important benefit of the center point representation
lies in its much tighter hypothesis space compared to the
anchor based counterparts.
缺点:
the center point based method also faces the
problem of recognition target ambiguity, caused by two different objects locating at the same position in a feature map,
which limits its prevalence in modern object detectors.(两个不同的目标的中心落在同一个cell里)
改进:
In RPDet, we show that this issue can be greatly alleviated by using the FPN structure [24]
for the following reasons: (用FPN结构来减轻这个影响)
first, objects of different scales
will be assigned to different image feature levels, which addresses objects of different scales and the same center points locations;
second, FPN has a high-resolution feature map
for small objects, which also reduces the chance of two objects having centers located at the same feature position. In fact, we observe that only 1.1% of objects in the COCO
datasets [26] suffer from the issue of center points located
at the same position when FPN is used.
7、Utilization of RepPoints(RepPoints学得过程)
Starting from the center points,
the first set of RepPoints is obtained via regressing offsets
over the center points. The learning of these RepPoints is
driven by two objectives:
1) the top-left and bottom-right
points distance loss between the induced pseudo box and the
ground-truth bounding box;
2) the object recognition loss
of the subsequent stage. As illustrated in Figure 4, extreme
.and key points are automatically learned.
The second set of
RepPoints represents the final object localization, which is
refined from the first set of RepPoints by Eq. (5). Driven by
the points distance loss alone, this second set of RepPoints
aims to learn finer object localization.
第一阶段的RepPoints是用识别和定位损失同时学到的,而第二阶段的RepPoints只有定位损失,可能也是因为定位和识别两个任务关于平移不变性的矛盾,这样第二阶段可以更好地更专注的学习定位。
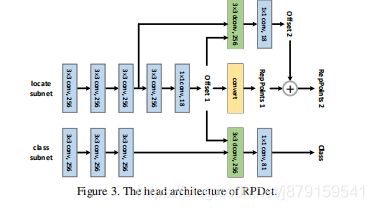
8、The head architecture of RPDet
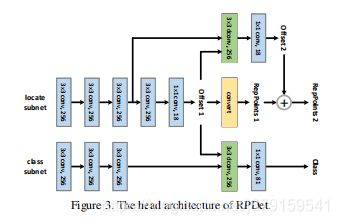
9、正负样本的分配(两个阶段不一样)
For both stages, only positive object hypothesis are assigned with localization (RepPoints) targets in training.
For the first localization stage, a
feature map bin is positive if 1) the pyramidal level of this
feature map bin equals the log scale of a ground-truth object s(B) = [log2(√wBhB/4)]; 2) the projection of this ground-truth object’s center point locate within this feature
map bin. (第一阶段需满足俩条件)
For the second localization stage, the first RepPoints is positive if its induced pseudo box has sufficient overlap with a ground-truth object that their intersectionover-union is larger than 0.5.
(以上是定位损失的正样本分配,以下是分类损失的正负样本分配)
Classification is conducted on the first set of RepPoints
only. The classification assignment criterion follows [25]
that IoU (between the induced pseudo box and ground-truth
bounding box) larger than 0.5 indicates positive, smaller
than 0.4 indicates background, and otherwise ignored. Focal loss is employed for classification training [25].
10、Ablation of the supervision sources

Table 2 also demonstrates the benefit of inluding the object recognition loss in learning RepPoints (+0.7 mAP). The
use of the object recognition loss can drive the RepPoints to
locate themselves at semantically meaningful positions on
an object, which leads to fine-grained localization and improves object feature extraction for the following recognition stage. Note that the object recognition feedback cannot
benefit object detection with the bounding box representation (see the first block in Table 2), further demonstrating
the advantage of RepPoints in flexible object representation.
RepPoints 的识别损失可以提升定位精度,而bounding box representation做不到。
11、 Comparison of the proposed method (RPDet) with other methods


参考文献
1、北大、清华、微软联合提出RepPoints,比边界框更好用的目标检测方法
2、RepPoints:可形变卷积的进阶
3、Anchor-free目标检测系列8:RepPoints:Point Set Representation for Object Detection(可变形卷积提取Offset关键点)