《Intro to Computer Systems》(csapp)LAB4(CacheLab)
通过本次实验,可算是搞清楚了高速缓存存储器的寻址逻辑。主要参考了这位老哥的博客。深入理解计算机系统-cachelab,不过他的partB做法有些麻烦,细节分析上好像也还有一些不对的地方(直接暴力分块时产生替换的位置)。课程提供的PPT也值得参考。
目录
- 高速缓存存储器
- lab4
-
- PART A
- PART B
-
- 32*32
- 64*64
- 61*67
- PART B代码
- 通关截图
高速缓存存储器
有2s组,每组有E行,每一行是一个缓存块,每一行包括1个有效位,t个标记位。有2b字节存数据以及有效位和标记位(标记位用来和给定地址的标记位对比,判断给定地址在不在该行中,如果在则命中)。

-
参数是判断高速缓存是否存在对应地址的数据的操作为:
参数S和B将m位地址分为了三段,首先通过S找到对应的组,再该组的行中找到标记位t与查询地址的标记为t相等的行,然后再该行包含的块中查找偏移地址位B的位置。即缓存命中。 -
直接映射高速缓存
在理解了组、行、标记、偏移地址概念后,直接映射就是每组只有一行,因此当两个不同地址在同一组,那么第二次访问就会导致第一次的块被替换出去。这时,每组不止一行,就可以考虑如LRU算法等进行行替换。
lab4
上面的概念至少要整明白,lab才能下手。
除了文档,课程提供的PPT也值得参考。有助于帮助解决读测试样例和输入参数的问题。
开始之前还要安装python2和valgrind工具(编译、测试结果要用到)
具体关于文档的解读开始时给出的老哥的博客。实验步骤和注意事项就不重复描述了。
PART A
该部分要模仿缓存,因此不需要存具体的数据,其中页面置换算法使用LRU。缓存可以用3维数组表示如下
uint64 ***cache; //[i][j][0] : Valid bit; [i][j][1] : Tag; [i][j][2] : LRU counter,
我实现LRU的主要逻辑如下:
- 根据地址定位到第s组,循环扫描一遍,判断Valid bit位生效的情况下,Tag位是否命中,如果命中则
hit返回,否则进行下一步。 - 再循环扫描一遍,记录第一个出现的未使用的行,同时记录最大的LRU counter。维护索引和最大count。
- 判断对应索引是否是空行,如果是,则
miss,否则是miss eviction。 - 返回0,1,2对应三种情况。
再测试样例中输入了size,我看了很多博客都没有考虑这个,确实这个题目下没有问题。但是如果size的值大于了每一行缓存的数据块(b2)的大小,那么就需要多行来存了。
代码如下:
csim.c
#include -E -b -t \n" );
printf("Options:\n");
printf(" -h Print this help message.\n");
printf(" -v Optional verbose flag.\n");
printf(" -s Number of set index bits.\n" );
printf(" -E Number of lines per set.\n" );
printf(" -b Number of block offset bits.\n" );
printf(" -t Trace file.\n\n" );
printf("Examples:\n");
printf(" linux> ./csim-ref -s 4 -E 1 -b 4 -t traces/yi.trace\n");
printf(" linux> ./csim-ref -v -s 8 -E 2 -b 4 -t traces/yi.trace\n");
}
char* read_arg(int argc, char* argv[]) {
int opt;
uint64 s, E, b;
s = E = b = 0;
char* path;
while (-1 != (opt = getopt(argc, argv, "hvs:E:b:t:"))) {
switch (opt) {
case 'h':
printHelp(); break;
case 'v':
verbose = 1; break;
case 's':
s = (uint64)atoll(optarg); break;
case 'E':
E = (uint64)atoll(optarg); break;
case 'b':
b = (uint64)atoll(optarg); break;
case 't':
path = optarg; break;
default:
printHelp(); break;
}
}
if (s == 0 || E == 0 || b == 0) {
printHelp();
exit(0);
}
set_sEb_cache(s, E, b);
return path;
}
void read_file(char *path) {
FILE * pFile;
char operation;
uint64 address;
uint64 size;
pFile = fopen(path, "r");
while (fscanf(pFile, " %c %lx,%lu", &operation, &address, &size) > 0) {
if (operation == 'I') continue;
if (verbose == 1) {
if (operation == 'M')
printf("%c %lx,%lu %s %s\n", operation, address, size, ans[LRU(address)], ans[LRU(address)]);
else
printf("%c %lx,%lu %s\n", operation, address, size, ans[LRU(address)]);
} else {
if (operation == 'M')
LRU(address);
LRU(address);
}
}
fclose(pFile);
}
int main(int argc, char* argv[]) {
char *path = read_arg(argc, argv);
read_file(path);
printSummary(_hits, _misses, _evictions);
free_cache();
return 0;
}
PART B
直接通过实例进行分析
32*32
linux> make
linux> ./test-trans -M 32 -N 32(s = 5, E = 1, b = 5) E=1,因此每一个组只有一行。
32*32数组中元素(对应位置的值表示所属于的组号)如下因为int占据32位,b=5(25=32),因此每一行存连续8个int(考虑8*8分块来求解,后面给出原因)

关于其中8*8分块的原因。(A转置得到B)
- 横向为8,是因为每个数组包含连续的8位,因此希望这连续8位只有第一位miss替换后面7位命中是最好情况。
- 纵向为8,转置以后,需要维持把A连续取得8位都赋值进B数组,让B也只有第一位miss替换后面7位命中是最好情况。
那么对角线上的块还会出现一些问题,以其中一个元素为例子,因为对角线上的块操作的是相同的组,就会有A和B的交替操作就会产生一些冲突,互相miss替换缓存。
为了方便快捷的解决这个问题,我直接一次开了一个8*8数组,用来一次性从A取出来8*8的块,再一次性把8*8的块赋值回B,从而避免该问题。(但是我考虑到一个问题是万一自己设出来的变量又有缓冲命中不命中问题该怎么办,但是由于该提只是模拟考虑对AB矩阵地址的缓存问题,所以不会遇到问题,我看其他博主貌似也没有考虑到自己生成的变量的缓存是否产生影响)
/*
* You can define additional transpose functions below. We've defined
* a simple one below to help you get started.
*/
void transpose_32_32(int M, int N, int A[N][M], int B[M][N]) {
int tmp[8][8];
for (int i = 0 ; i < M; i += 8)
for (int j = 0; j < N; j += 8) {
for (int x = 0; x < 8; x++)
for (int y = 0; y < 8; y++)
tmp[x][y] = A[x + i][j + y];
for (int y = 0; y < 8; y++)
for (int x = 0; x < 8; x++)
B[j + y][x + i] = tmp[x][y];
}
}
64*64
同理32*32
61*67
这个大小就很迷了,我考虑了很久怎么写判断逻辑。但是感觉没什么好的办法,最终看了别人的实现,然后惊了,竟然直接暴力分块,看结果。当遇到有些产生冲突的分块也不考虑,最终都能全部通过。
PART B代码
trans.c
/*
* trans.c - Matrix transpose B = A^T
*
* Each transpose function must have a prototype of the form:
* void trans(int M, int N, int A[N][M], int B[M][N]);
*
* A transpose function is evaluated by counting the number of misses
* on a 1KB direct mapped cache with a block size of 32 bytes.
*/
#include 通关截图
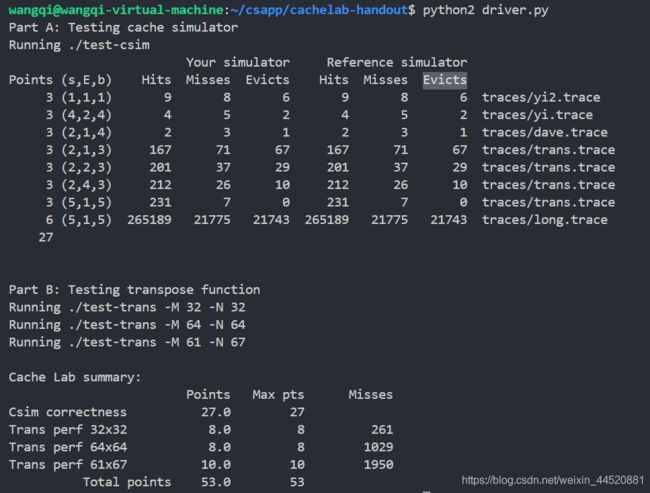
本次LAB难度不如上次,主要是通过本次实验可算是搞明白了缓存。博客内容整理的仓促写简略,个人任务如果对缓存理解了,那本次实验没有难度。主要是懒的总结赶紧开始下次LAB。