从零开始码出卡尔曼滤波代码-BY忠厚老实的老王
文章目录
-
- @[toc]
- tips
- 目标:生成一段随机信号,并滤波
-
- 1 生成数据,以及对应的观测的数据
- 2 滤波实现一 粗糙的实现
-
- 2.1 观测方程:当前的状态+噪声
- 2.2 预测方程实现:最粗糙的建模 当前的状态=上一步的状态+噪声
- 2.3 初始步:给一个初值(只需要做一次)
-
- 2.2.2 更新步和预测步:其实就是算矩阵形式的卡尔曼的5条公式:
- 2.4 完整代码
- 3 滤波实现二
-
- 3.0 扩展一下状态:x====>[x,x',x'']
- 3.1 观测方程:当前的状态+噪声,跟上个例子的一样
- 3.2 预测方程实现:状态扩展成[x,x',x''],当前状态是上一个状态和状态的导数(速度)以及二阶导数(加速度)的多项式
- 3.2 预测和更新:
- 4 两个传感器问题
文章目录
-
- @[toc]
- tips
- 目标:生成一段随机信号,并滤波
-
- 1 生成数据,以及对应的观测的数据
- 2 滤波实现一 粗糙的实现
-
- 2.1 观测方程:当前的状态+噪声
- 2.2 预测方程实现:最粗糙的建模 当前的状态=上一步的状态+噪声
- 2.3 初始步:给一个初值(只需要做一次)
-
- 2.2.2 更新步和预测步:其实就是算矩阵形式的卡尔曼的5条公式:
- 2.4 完整代码
- 3 滤波实现二
-
- 3.0 扩展一下状态:x====>[x,x',x'']
- 3.1 观测方程:当前的状态+噪声,跟上个例子的一样
- 3.2 预测方程实现:状态扩展成[x,x',x''],当前状态是上一个状态和状态的导数(速度)以及二阶导数(加速度)的多项式
- 3.2 预测和更新:
- 4 两个传感器问题
tips
用的融合方法被称为“并行滤波融合”(又称观测值扩维融合),是集中式融合系统中的一种方法。集中式融合系统还包含两种方法:序贯滤波融合(又称顺序滤波融合)和数据压缩滤波融合(又称观测值加权融合)。与集中式融合系统对应的还有分布式融合系统。
更多关于多传感器数据融合的内容,大家可参考韩崇昭老师的《多源信息融合》第二版。
目标:生成一段随机信号,并滤波
这里只是对数据进行滤波,并没有进行姿态什么的计算。
1 生成数据,以及对应的观测的数据
t=0.1:0.01:1;
L=length(t);
%生成真实信号x,以及观测y
%首先初始化
x=zeros(1,L);
y=x;
y2=x;
%生成信号,设x=t^2
for i=1:L
x(i)=t(i)^2;
y(i)=x(i)+normrnd(0,0.1);%正态分布,参数为期望和标准差
y2(i)=x(i)+normrnd(0,0.1);
end
%%%%%%%%%%%信号生成完毕%%%%
plot(t,x,t,y,'LineWidth',2);
真实数据和观测数据的图示:
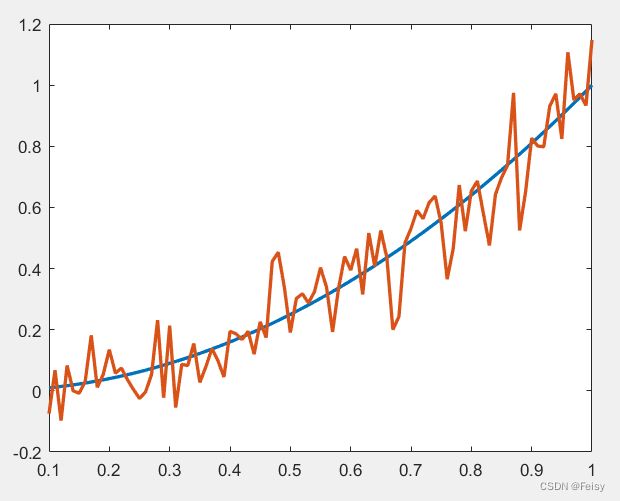
实际的时候,我们不知道蓝色代表的真实值,只有红色的观测值
2 滤波实现一 粗糙的实现
2.1 观测方程:当前的状态+噪声
%观测方程好写Y(K)=X(K)+R,R~N(0,1)
2.2 预测方程实现:最粗糙的建模 当前的状态=上一步的状态+噪声
%%%预测方程观测方程怎么写%%%
%预测方程不好写,因为根据上面图示的观测数据,感觉像是线性增长的,所以我们猜是线性增长
%在这里,可以猜一猜是线性增长,但是大多数问题,信号是杂乱无章的,怎么办?方法是尝试各种模型
%模型一,最粗糙的建模
%状态和观测方程
%X(K)=f * X(K-1)+Q
%Y(K)=h *X(K)+R
%猜R,Q~N(0,1); 作
%卡尔曼滤波的前提是:状态和观测都是线性变化的,这里的f,h设为1
F1=1;
H1=1;
%猜R,Q~N(0,1),期望为0,方差是1的正态分布,Q,R是贝叶斯滤波的难点,没什么规律,只能靠自己观察总结
Q1=1;
R1=1;
2.3 初始步:给一个初值(只需要做一次)
%初始化x(k)+
Xplus1=zeros(1,L);%plus + 的英语 minus -的英语
%我们会经常用到Xplus,Xminus,Pplus,Pminus
%设置一个初值,假设Xplus1(1)~N(0.01,0.01^2)
Xplus1(1)=0.01;%一开始的状态
Pplus1=0.01^2; %预测方差的初值
2.2.2 更新步和预测步:其实就是算矩阵形式的卡尔曼的5条公式:

%X(K)minus=F*X(K-1)plus
%P(K)minus=F*P(K-1)plus*F'+Q
%K=P(K)minus*H'*inv(H*P(K)minus*H'+R)
%X(K)plus=X(K)minus+K*(y(k)-H*X(K)minus)
%P(K)plus=(I-K*H)*P(K)minus
for i=2:L
%%%%预测步%%%%%%
Xminus1=F1*Xplus1(i-1);
Pminus1=F1*Pplus1*F1'+Q1;
%%%%%更新步%%%%%
K1=(Pminus1*H1')*inv(H1*Pminus1*H1'+R1);
Xplus1(i)=Xminus1+K1*(y(i)-H1*Xminus1);%计算本步的状态,并存起来
Pplus1=(1-K1*H1)*Pminus1;%多维的话,1要用单位矩阵I替换
end
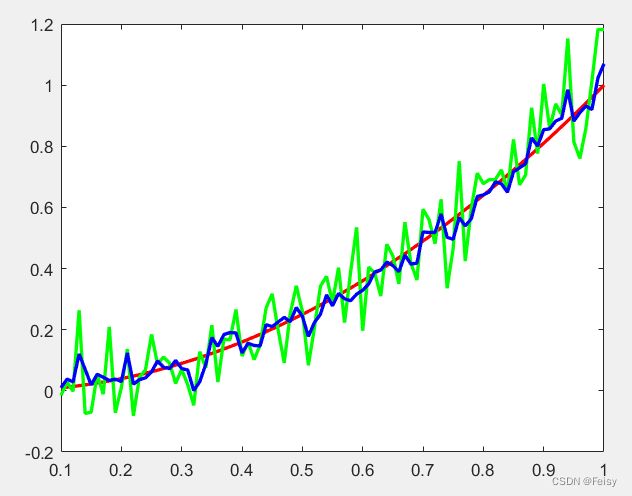
plot(t,x,t,y,t,Xplus1,'LineWidth',2);
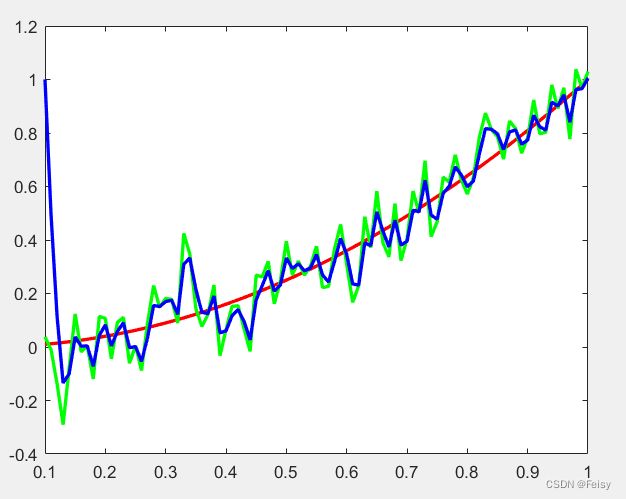
滤波效果图示:看起来滤波的效果只有一点点,原因是模型建得太粗糙了,Q太大了,这就意味着更多是相信观测值。
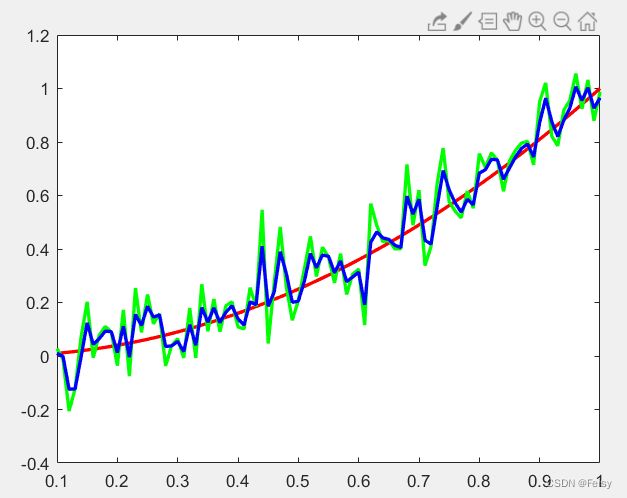
如果我们将Q的值改为0.01的效果:稍微好一点,但是还是不好,预测的模型太粗糙了。
观测一下,真实数据是时间的平方,预测模型是直接线性增长,所以在t比较小的时候,也就是
前面那一段,滤波出来的值是比较靠近真实值的。后面,t的平方快速增长,导致差异越来越大。
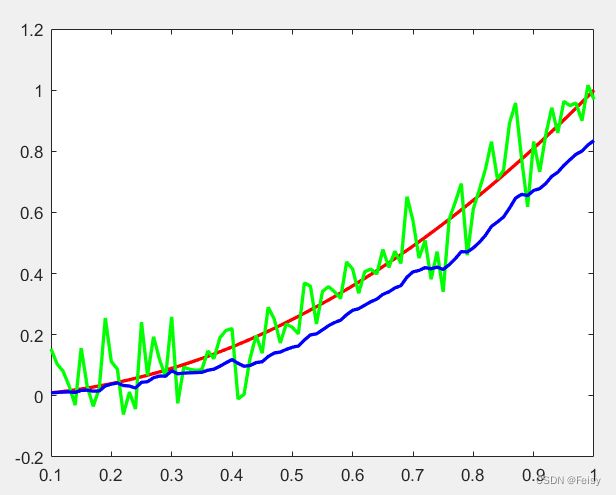
如果将R=0.01,Q=1,可以看到,滤波的值和观测的值重合了,表示完全相信观测值。

R,Q,初值改得离谱一点:
Xplus1(1)=1;%真实初值的100倍。
可见,卡尔曼对初值不敏感,跟初值是0.01差不多。
2.4 完整代码
t=0.1:0.01:1;
L=length(t);
%生成真实信号x,以及观测y
%首先初始化
x=zeros(1,L);
y=x;
y2=x;
%生成信号,设x=t^2
for i=1:L
x(i)=t(i)^2;
y(i)=x(i)+normrnd(0,0.1);%正态分布,参数为期望和标准差
y2(i)=x(i)+normrnd(0,0.1);
end
%plot(t,x,t,y,'LineWidth',2);
%%%%%%%%%%%信号生成完毕%%%%
F1=1;
H1=1;
%猜R,Q~N(0,1),期望为0,方差是1的正态分布
Q1=1;
R1=1;
Xplus1(1)=0.01;
Pplus1=0.01^2;
for i=2:L
%%%%预测步%%%%%%
Xminus1=F1*Xplus1(i-1);
Pminus1=F1*Pplus1*F1'+Q1;
%%%%%更新步%%%%%
K1=(Pminus1*H1')*inv(H1*Pminus1*H1'+R1);
Xplus1(i)=Xminus1+K1*(y(i)-H1*Xminus1);
Pplus1=(1-K1*H1)*Pminus1;
end
plot(t,x,'r',t,y,'g',t,Xplus1,'b','LineWidth',2);
3 滤波实现二
3.0 扩展一下状态:x====>[x,x’,x’']
3.1 观测方程:当前的状态+噪声,跟上个例子的一样
Y(K)=X(K)+R,R~N(0,1)
观测方程的形式是:y_k = H* y_k-1+R,这里我们观察不到x',x'',所以这两项就是0,提取出H:
H=[1 0 0]
3.2 预测方程实现:状态扩展成[x,x’,x’'],当前状态是上一个状态和状态的导数(速度)以及二阶导数(加速度)的多项式
多项式信号多求几阶导数,总会比较平缓
此时,状态是[x,x’,x’']
%
X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2
X'(K)=0*X(K-1)+X'(K-1)+X''(K-1)*dt+Q3
X''(K)=0*X(K-1)+0*X'(K-1)+X''(K-1)+Q4
将上面的表达式代入状态方程x_k = F *x_k-1+Q,提取得到F:
F= [1 dt 0.5*dt^2
0 1 dt
0 0 1 ]
协方差
Q= [Q2 0 0
0 Q3 0
0 0 Q4]
这种协方差表示噪声不相关。
3.2 预测和更新:
dt=t(2)-t(1);
F2=[1,dt,0.5*dt^2;0,1,dt;0,0,1];%%状态方程x_k = F *x_k-1+Q的F
H2=[1,0,0];%观测方程 y_k = H* y_k-1+R的H
Q2=[1, 0, 0;0, 0.01, 0;0, 0, 0.0001];
R2=3;
%%%设置初值%%%%
Xplus2=zeros(3,L);
Xplus2(1,1)=0.1^2;
Xplus2(2,1)=0;
Xplus2(3,1)=0;
Pplus2=[0.01, 0, 0;0, 0.01,0;0, 0, 0.0001];
for i=2:L
%%%预测步%%%
Xminus2=F2*Xplus2(:,i-1);
Pminus2=F2*Pplus2*F2'+Q2;
%%%更新步%%%%
K2=(Pminus2*H2')*inv(H2*Pminus2*H2'+R2);
Xplus2(:,i)=Xminus2+K2*(y(i)-H2*Xminus2);
Pplus2=(eye(3)-K2*H2)*Pminus2;
end
跟第一次建模对比,效果好很多了。

将观测噪声改大10倍:y2(i)=x(i)+normrnd(0,1);
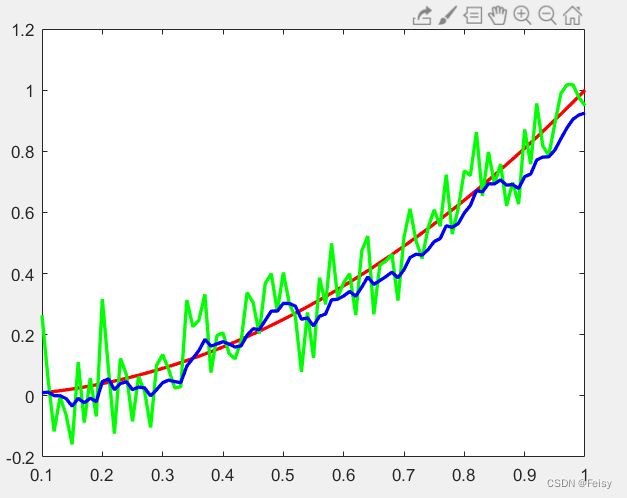
我们也可以使用傅里叶变换消除噪声,再傅里叶逆变换回来,可能可以达到同样的效果,但是,贝叶斯滤波有它的优点,可以进行在线滤波,实时滤波 ,因为贝叶斯滤波是递推的,而傅里叶则不行。
##3.3 完整代码
t=0.1:0.01:1;
L=length(t);
%生成真实信号x,以及观测y
%首先初始化
x=zeros(1,L);
y=x;
y2=x;
%生成信号,设x=t^2
for i=1:L
x(i)=t(i)^2;
y(i)=x(i)+normrnd(0,0.1);%正态分布,参数为期望和标准差
y2(i)=x(i)+normrnd(0,0.1);
end
%plot(t,x,t,y,'LineWidth',2);
%%%%%%%%%%%信号生成完毕%%%%
%X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2
%Y(K)=X(K)+R R~N(0,1)
%此时状态变量X=[X(K) X'(K) X''(K) ]T(列向量)
%Y(K)=H*X+R H=[1 0 0](行向量)
%预测方程
%X(K)=X(K-1)+X'(K-1)*dt+X''(K-1)*dt^2*(1/2!)+Q2
%X'(K)=0*X(K-1)+X'(K-1)+X''(K-1)*dt+Q3
%X''(K)=0*X(K-1)+0*X'(K-1)+X''(K-1)+Q4 %%多项式信号多求几阶导数,总会比较平缓,而
%X''(K)=X''(K-1)+Q3正是描述平缓的随机过程,这种建模相对精细一些,适用范围也较广
%F= 1 dt 0.5*dt^2
% 0 1 dt
% 0 0 1
%H=[1 0 0]
%Q= Q2 0 0
% 0 Q3 0
% 0 0 Q4 协方差矩阵
dt=t(2)-t(1);
F2=[1,dt,0.5*dt^2;0,1,dt;0,0,1];%%%此处要注意矩阵是否病态,若dt特别小,易导致矩阵病态或精度丢失
H2=[1,0,0];
Q2=[1, 0, 0;0, 0.01, 0;0, 0, 0.0001];
R2=3;
%%%设置初值%%%%
Xplus2=zeros(3,L);
Xplus2(1,1)=0.1^2;
Xplus2(2,1)=0;
Xplus2(3,1)=0;
Pplus2=[0.01, 0, 0;0, 0.01,0;0, 0, 0.0001];
for i=2:L
%这里没有更新dt,正常来说,dt,F也要更新的。
%%%预测步%%%
Xminus2=F2*Xplus2(:,i-1);
Pminus2=F2*Pplus2*F2'+Q2;
%%%更新步%%%%
K2=(Pminus2*H2')*inv(H2*Pminus2*H2'+R2);
Xplus2(:,i)=Xminus2+K2*(y(i)-H2*Xminus2);
Pplus2=(eye(3)-K2*H2)*Pminus2;
end
plot(t,x,'r',t,y,'g',t,Xplus2(1,:),'b','LineWidth',2);
4 两个传感器问题
生成真实数据以及两个传感器的观测数据
t=0.1:0.01:1;
L=length(t);
x=zeros(1,L);
y=x;
y2=x;
%生成信号,设x=t^2
for i=1:L
x(i)=t(i)^2;
y(i)=x(i)+normrnd(0,0.1);% 传感器1
y2(i)=x(i)+normrnd(0,0.1);%传感器2
end
状态方程和观测方程采用上面模型2的方式
X(K)=X(K-1)+X’(K-1)dt+X’‘(K-1)dt^2(1/2!)+Q2
X’(K)=0X(K-1)+X’(K-1)+X’‘(K-1)dt+Q3
X’'(K)=0X(K-1)+0*X’(K-1)+X’'(K-1)+Q4 %%多项式信号多求几阶导数,总会比较平缓,而
Y1(K)=X(K)+R1
Y2(K)=X(K)+R2
F3=[1, dt, 0.5*dt^2;0, 1, dt;0, 0, 1];
H3=[1,0,0;1,0,0];%两个传感器,所以H3比H2大一倍
Q3=[1, 0, 0;0, 0.01, 0;0, 0, 0.0001];
R1 = 3;
R2 =3;
R3=[R1,0;0,R2];% 这里跟上面模型二不同是有了2个传感器,所以是协方差矩阵
%%%设置初值%%%%
Xplus3=zeros(3,L);
Xplus3(1,1)=0.1^2;
Xplus3(2,1)=0;
Xplus3(3,1)=0;
Pplus3=[0.01, 0,0;0, 0.01,0;0,0, 0.0001];
更新和预测
for i=2:L
%%%预测步%%%
Xminus3=F3*Xplus3(:,i-1);
Pminus3=F3*Pplus3*F3'+Q3;
%%%更新步%%%%
K3=(Pminus3*H3')*inv(H3*Pminus3*H3'+R3);
Y=zeros(2,1);
Y(1,1)= y(i);
Y(2,1)=y2(i);
Xplus3(:,i)=Xminus3+K3*(Y-H3*Xminus3);
Pplus3=(eye(3)-K3*H3)*Pminus3;
end
plot(t,x,'r',t,y,'g',t,Xplus3(1,:),'b','LineWidth',2);