智能营销增益模型(Uplift Modeling)实践整理
一、uplift 思想(因果推断)
常用的点击率预测模型,称为响应模型(response model),即预测用户看到商品(Treatment)后点击(购买)的概率。但在营销的发放优惠券这种场景下,很自然会想到,用户是本来就有购买的意愿还是因为发放了优惠券诱使用户购买?
对有发放优惠券这种有成本的营销活动,我们希望模型触达的是营销敏感的用户,即发放的优惠券促使用户购买,而对优惠券不敏感的用户——无论是否发券都会购买——最好不要发券,节省成本。营销活动中,对用户进行干预称为treatment,例如发放优惠券是一次treatment。我们可以将用户分为以下四类:

- persuadables:不发券就不购买、发券才会购买的人群,即营销敏感人群
- sure thing:无论是否发券,都会购买,自然转化
- lost causes:无论是否发券都不会购买,这类用户实在难以触达到,直接放弃
- sleeping dogs:与persuadables相反,对营销活动比较反感,不发券的时候会有购买行为,但发券后不会再购买。
假设有 N 个用户,Y*i*(1) 表示我们对用户 i 干预后的结果,比如给用户 i 发放优惠券后(干预)用户下单(结果);Y*i*(0) 表示我们没有对用户 i 干预的结果,比如没有给用户 i 发放优惠券(干预)用户下单(结果)。
用户 i 的因果效应(causal effect)的计算如下:

我们通常估计的是CATE( Conditional Average Treatment Effect),也就是说,对人群中的一个子人群来评估因果关系(用一个自人群的因果效果来表示一个单个人的因果效果)。

二、建模方式
1. 差分响应模型(Two-Model)
Two-model 方法是分别在 treatment 组和 control 组数据上独立建模(目标是 order)。
预测时分别用 treatment 模型和 control 模型预测用户(特征 X 相同)的分数,两个模型预测分数相减得到 uplift score (多个模型预测一条样本)
这里因果效应分数是计算出来的而不是通过模型直接优化出来的,所以本质上,这还是传统的响应模型,而且两个独立的模型分开训练容易累积误差(两个独立模型的误差会累加传递到最终的uplift score)

2. 差分响应模型升级版(One-Model)
One-Model 在模型层面做了打通,同时底层的样本也是共享的(把 是否发券 - 是否购买 样本都扔进模型)(treatment 作为其中的一维特征)(建模目标仍然是 order)
One Model 优点是样本的共享可以使模型学习的更加充分,同时避免双模型打分误差累积的问题,且可以支持 multiple treatment 的建模(Treatment 特征可以是多种枚举值,比如不同金额)
在预测的时候,一个模型预测多条样本,同一个用户,特征 X (除 Treatment 外)都相同,将 treatment 修改构造多个样本,将 T = treatment 的预测结果 pre( t ) 与 T = control 的预测结果 pre( c ) 相减,得到 uplift score
但是它在本质上还是在对 response 建模,因此对 uplift 的建模还是比较间接;而且如果特征集 X 比较大的话,则 treatment 特征 只占上百个特征中的一个,重要度不高,导致pre( t ) 与 pre( c ) 差别非常小,从而用户区分度非常低。
3. 标签转换模型(Class Transformation Method)
类别转换的方式是针对二分类的情境下提出的。这种方法的目标函数如下:

其中 W 表示 Treatment,Y 表示是否购买,可以知道,标签转换是将 发券才买 的营销敏感用户 & 不发券就不买的无动于衷用户作为正样本,将 发券仍不买 & 不发券也买 的无需营销用户作为负样本,训练二分类模型

4. 直接建模(Modeling Uplift Directly)
是通过修改已有的学习学习结构直接对 uplift 进行建模,比较流行的就是修改树模型的特征分裂方法。

传统树模型的分裂过程中,主要参照指标是信息增益,其本质是希望通过特征分裂后下游正负样本的分布更加悬殊,即代表类别纯度变得更高。
同理这种思想也可以引入到 Uplift Model建模过程,其中 Pt 是 treatment 组的概率分布(可以简单理解为:购买 / 不购买的比例),Pc 是 control 组的概率分布,我们希望通过特征分裂后,Pt 与 Pc 的概率分布差异,比特征分裂前更大,也就是这里的 gain

D(*) 表示的是差异度量函数(如何表示这两组的分布差异),有这么三种方式:Kullback,、Euclidean、Chi-Squared,常用的是 KL 散度。公式如下:

关于 KL 具体的非常好的例子可以参考:https://www.zhihu.com/question/41252833

5. 多分类模型(multi-classification model)
根据第一节,我们知道,用户可以按照是否发券 - 是否购买,划分成四象限,因此另一种建模方式则是按照:(treatment / control) * (order / not) 分为四种类别
def get_new_label(label, p_abgroup):
# 不发券不买 Control Non-Responders(CN)
if label == 0 and p_abgroup == 'b':
return 0
# 不发券买 Control Responders(CR)
if label == 1 and p_abgroup == 'b':
return 1
# 发券不买 Treatment Non-Responders(TN)
if label == 0 and p_abgroup == 'a':
return 2
# 发券买 Treatment Responders(TR)
if label == 1 and p_abgroup == 'a':
return 3
同样的,也是将所有真实样本喂入模型,底层的样本也是共享的,而且建模目标不再是 order 而是用户属于哪种群体
特征则是构建了:画像、行为、下单、竞品、用券、收益、交叉转换、实时特征 Flink 等(其中券特征可以参考:https://tianchi.aliyun.com/notebook-ai/detail?postId=58107)
模型按照四分类的思路建模,得到用户属于四种群体的概率值后,按照权重相加(我这里用的是 [1, 1, -1, -1] ,可以自行试验最优权重组合)(索引与上面的代码一致):uplift_scores = [i[3] + i[0] - i[2] - i[1] for i in class_probs],即得到所有用户的 uplift score。
评估时有三种方式:
- acc 分类准确率,这个指标结合 loss 损失的走向,用来验证模型是否过拟合,以及拟合是否充分
- auuc(Area Under Uplift Curve),也就是下面这张图,其中深蓝色的是对用户随机排序,得到的实验组(Treatment)比对照组(Control)的增量,可以看到随机排序时是一个均匀的线性关系;同时,我们使用定价模型对测试集进行预测,会得到多组结果,按照 argmax 的原则,选择最大的作为最终结果,并将对应的价格作为定价。然后我们按照模型预测的 lift 值由高到低排序,画出来的增量走势曲线,即为浅蓝色的这条曲线。计算曲线下面积即为 auuc ,越大表示模型的结果越好
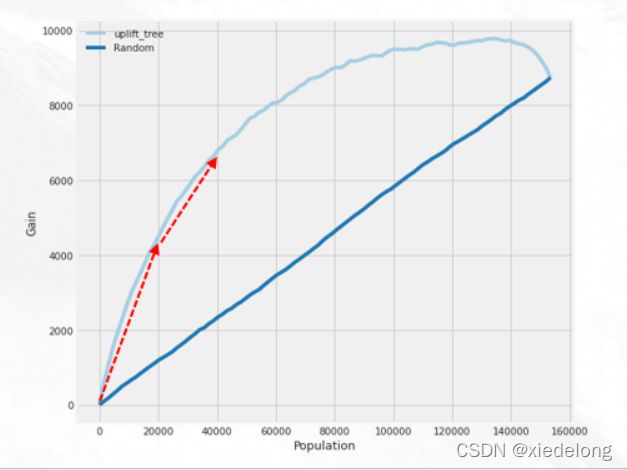
- 分段评估,还是看上面这张图,将全量测试集用户样本,按照 10% 为间隔,分为10个档位,我们去评估每 10% 的增量效果。公式的含义是,首先第一项是实验组里购买的比例,也即是实验组转化率,第二项是指对照组的转化率,二者之差也就是发券转化率增量,就是图里的斜率。后面括号第三项的含义是是当前这 10% 的总用户量(也就是△x),所以得到的结果就是每 10% 的实验组增量
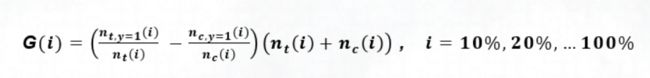
附1(causal uplift model 代码):
from causalml.inference.meta import LRSRegressor
from causalml.inference.meta import XGBTRegressor, MLPTRegressor
from causalml.inference.meta import BaseXRegressor
from causalml.inference.meta import BaseRRegressor
from xgboost import XGBRegressor
from causalml.dataset import synthetic_data
from causalml.dataset import make_uplift_classification
from causalml.inference.tree import UpliftRandomForestClassifier
from causalml.metrics import plot_gain
from causalml.metrics import auuc_score
from __future__ import division
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time
import datetime
import warnings
import operator
import re
import pickle
import gzip
from sklearn.utils import shuffle
from sklearn import linear_model, datasets
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.metrics import classification_report, accuracy_score,roc_auc_score
import pickle
warnings.filterwarnings(action='ignore', category=UserWarning, module='matplotlib')
pd.options.mode.chained_assignment = None # default='warn'
plt.style.use('seaborn-whitegrid')# 设置图形的显示风格
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# 显示所有列(参数设置为None代表显示所有行,也可以自行设置数字)
pd.set_option('display.max_columns', 100)
# 显示所有行
pd.set_option('display.max_rows', 100)
# 设置数据的显示长度,默认为50
pd.set_option('max_colwidth', 100)
# 禁止自动换行(设置为Flase不自动换行,True反之)
pd.set_option('expand_frame_repr', False)
# 特征
portrait_cols = []
action_cols = []
purchase_cols = []
compete_colst = []
bonus_cols = []
cal_cols = []
all_cols = portrait_cols + action_cols + purchase_cols + compete_colst + bonus_cols + cal_cols
# 样本
data = pd.read_csv('../data/all_data.csv')
data['treatment_key'] = data[['price', 'p_abgroup']].apply(lambda row: row['p_abgroup'] + '_' + str(row['price']) if row['p_abgroup'] == 'a' else 'b', axis=1)
# function for calculating the uplift
def calc_uplift(df, label_name):
avg_order_value = 25 # 单价收益
# calculate conversions for each offer type
base_conv = df[df.p_abgroup == 'b'][label_name].mean() # 对照
disc_conv = df[df.p_abgroup == 'a'][label_name].mean() # 实验
# calculate conversion uplift for discount and bogo
disc_conv_uplift = disc_conv - base_conv
# calculate order uplift
disc_order_uplift = disc_conv_uplift * len(df[df.p_abgroup == 'a'][label_name])
# calculate revenue uplift
disc_rev_uplift = disc_order_uplift * avg_order_value
print('Discount Conversion Uplift: {0}%'.format(np.round(disc_conv_uplift * 100, 5))) # 发券
return disc_conv_uplift
# 训练
val = data[(data['dt'] > 20210101)]
x_val = val[all_cols]
y_val = val['label']
df_data_lift = val.copy()
train = data[(data['dt'] <= 20210101)]
# Look at the conversion rate and sample size in each group
train.pivot_table(values='label',
index='treatment_key',
aggfunc=[np.mean, np.size],
margins=True)
uplift_model = UpliftRandomForestClassifier(n_estimators=10, control_name='b')
# , max_depth=6, min_samples_leaf=50
uplift_model.fit(train[all_cols].values,
treatment=train['treatment_key'].values,
y=train['label'].values)
# 预测
y_pred = uplift_model.predict(val[all_cols].values)
result = pd.DataFrame(y_pred, columns=uplift_model.classes_)
# 计算 auuc
# If all deltas are negative, assing to control; otherwise assign to the treatment
# with the highest delta
best_treatment = np.where((result < 0).all(axis=1), 'b', result.idxmax(axis=1))
# Create indicator variables for whether a unit happened to have the
# recommended treatment or was in the control group
actual_is_best = np.where(val['treatment_key'] == best_treatment, 1, 0)
actual_is_control = np.where(val['treatment_key'] == 'b', 1, 0)
synthetic = (actual_is_best == 1) | (actual_is_control == 1)
synth = result[synthetic]
auuc_metrics = (synth.assign(is_treated = 1 - actual_is_control[synthetic],
conversion = val.loc[synthetic, 'label'].values,
uplift_tree = synth.max(axis=1))
.drop(columns=list(uplift_model.classes_)))
plot_gain(auuc_metrics, outcome_col='conversion', treatment_col='is_treated')
auuc_score(auuc_metrics, outcome_col='conversion', treatment_col='is_treated')
# 计算阈值
df_data_lift['uplift_score'] = y_pred[:, 3]
lift_list = []
uplift_q_list = []
for i in np.arange(0, 1.1, 0.1):
uplift_q_i = df_data_lift.uplift_score.quantile(i)
uplift_q_list.append(uplift_q_i)
df_q_i_data_lift = df_data_lift[df_data_lift.uplift_score <= uplift_q_i].reset_index(drop=True)
lift_list.append(calc_uplift(df_q_i_data_lift, 'label'))
plt.plot(uplift_q_list, [np.round(i, 1) for i in list(np.arange(0, 1.1, 0.1))], marker='o')
plt.xlabel('threshold')
plt.title('cumulative gain chart')
plt.ylabel('data ratio')
plt.show()
附2(四分类 lgb 代码,效果最优):
from __future__ import division
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import time
import datetime
import warnings
import operator
import re
import pickle
import gzip
from sklearn.utils import shuffle
from sklearn import linear_model, datasets
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.metrics import classification_report, accuracy_score,roc_auc_score
import pickle
warnings.filterwarnings(action='ignore', category=UserWarning, module='matplotlib')
pd.options.mode.chained_assignment = None # default='warn'
plt.style.use('seaborn-whitegrid')# 设置图形的显示风格
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# 显示所有列(参数设置为None代表显示所有行,也可以自行设置数字)
pd.set_option('display.max_columns', 100)
# 显示所有行
pd.set_option('display.max_rows', 100)
# 设置数据的显示长度,默认为50
pd.set_option('max_colwidth', 100)
# 禁止自动换行(设置为Flase不自动换行,True反之)
pd.set_option('expand_frame_repr', False)
from causalml.metrics import plot_gain
from causalml.metrics import auuc_score
# function for calculating the uplift
def calc_uplift(df, label_name):
avg_order_value = 25 # 单价收益
# calculate conversions for each offer type
base_conv = df[df.p_abgroup == 'b'][label_name].mean() # 对照
disc_conv = df[df.p_abgroup == 'a'][label_name].mean() # 实验
# calculate conversion uplift for discount and bogo
disc_conv_uplift = disc_conv - base_conv
# calculate order uplift
disc_order_uplift = disc_conv_uplift * len(df[df.p_abgroup == 'a'][label_name])
# calculate revenue uplift
disc_rev_uplift = disc_order_uplift * avg_order_value
print('Discount Conversion Uplift: {0}%'.format(np.round(disc_conv_uplift * 100, 5))) # 发券
return disc_conv_uplift
# 特征
portrait_features = []
action_features = []
purchase_features = []
compete_features = []
bonus_features = []
real_time_features = []
cal_features = []
ota_flight_features = []
emb_cols = []
user_cols = []
fill_na_dict = {i: -1 for i in portrait_features}
fill_na_dict.update({i: 0 for i in action_features if '2' not in i})
fill_na_dict.update({i: -1 for i in action_features if '2' in i})
fill_na_dict.update({i: 0 for i in purchase_features if '_ratio' not in i})
fill_na_dict.update({i: -1 for i in purchase_features if '_ratio' in i})
fill_na_dict.update({i: -1 for i in compete_features})
fill_na_dict.update({i: -1 for i in bonus_features if 'count' not in i})
fill_na_dict.update({i: 0 for i in bonus_features if 'count' in i})
fill_na_dict.update({i: -1 for i in real_time_features if 'cnt' not in i})
fill_na_dict.update({i: 0 for i in real_time_features if 'cnt' in i})
fill_na_dict.update({i: -1 for i in cal_features})
fill_na_dict.update({i: 0 for i in ota_flight_features})
remove_cols = []
fill_na_dict = {key: value for key, value in fill_na_dict.items() if key not in remove_cols}
feature_cols = list(fill_na_dict.keys()) + emb_cols
# 训练
data_new = pd.read_csv('./data/train_data_embedding_all.csv')
val = data_new[data_new['dt'] > 20210101]
x_val = val[feature_cols]
# new_label 为按照 ab 和 label 转换后的四分类
y_val = val['new_label']
df_data_lift = val.copy()
length = len(df_data_lift)
clf_dict = {}
feat_imp_split_dict = {}
treat_cols = [50, 100, 1000]
# 不同的 treatment(这里是金额)
for price in treat_cols:
print(price)
train = data_new[(data_new['dt'] <= 20210105)]
train = train[train['price'] == price]
label_sample = train['new_label'].value_counts().reset_index()['new_label'].min()
df_0_sample = train[train['new_label'] == 0].sample(label_sample)
df_1_sample = train[train['new_label'] == 1].sample(label_sample)
df_2_sample = train[train['new_label'] == 2].sample(label_sample)
df_3_sample = train[train['new_label'] == 3].sample(label_sample)
train = pd.concat([df_0_sample, df_1_sample, df_2_sample, df_3_sample])
# 提取训练数据
x_train, x_test, y_train, y_test = train_test_split(train[feature_cols], train['new_label'], test_size=0.2, random_state=10)
train_data = lgb.Dataset(x_train, label=y_train, free_raw_data=False)
validation_data = lgb.Dataset(x_test, label=y_test, free_raw_data=False)
params = {
'learning_rate': 0.02,
'boosting_type': 'gbdt',
'lambda_l1': 0.2,
'lambda_l2': 0.2,
'max_depth': 7,
'num_leaves': 64,
'metric': {'multi_logloss'},
'objective': 'multiclass',
'nthread': -1,
'num_class': 4,
}
clf = lgb.train(params, train_data, valid_sets=[validation_data], num_boost_round=1000, early_stopping_rounds=100)
clf_dict[price] = clf
# 特征重要性
feat_imp_split = pd.DataFrame({
'column': list(x_train.columns),
'importance': clf.feature_importance(importance_type='split'),
}).sort_values(by='importance', ascending=True)
feat_imp_split_dict[price] = feat_imp_split
feat_imp_split.plot(x='column', y='importance', kind='barh', figsize=(12.5, 50), title='Feature Importances')
plt.xlabel('Feature Importance Score')
class_probs = clf.predict(x_val.values)
uplift_scores = [i[3] + i[0] - i[2] - i[1] for i in class_probs]
accuracy_score(list(y_val), np.argmax(class_probs, axis=1))
df_data_lift['uplift_score' + str(price)] = uplift_scores
# 评估
top_3 = sorted(df_data_lift['uplift_score' + str(price)], reverse=True)[:int(length * 0.3)][-1]
calc_uplift(df_data_lift[df_data_lift['uplift_score5'] > top_3], 'label')
# 保存模型
def dump_obj_compressed(obj, path):
with gzip.GzipFile(path, "wb") as file:
pickle.dump(obj, file)
model_dict = {"models":clf_dict, "model_cols":list(x_train.columns), "fillna_dict": fill_na_dict}
dump_obj_compressed(model_dict, "../model/model.pickle".format(price))
# 计算 auuc
result = df_data_lift[['a_' + str(i) for i in treat_cols]]
# 计算 auuc
# If all deltas are negative, assing to control; otherwise assign to the treatment
# with the highest delta
best_treatment = np.where((result < 0).all(axis=1), 'b', result.idxmax(axis=1))
# Create indicator variables for whether a unit happened to have the
# recommended treatment or was in the control group
actual_is_best = np.where(val['treatment_key'] == best_treatment, 1, 0)
actual_is_control = np.where(val['treatment_key'] == 'b', 1, 0)
synthetic = (actual_is_best == 1) | (actual_is_control == 1)
synth = result[synthetic]
auuc_metrics = (synth.assign(is_treated = 1 - actual_is_control[synthetic],
conversion = val.loc[synthetic, 'label'].values,
uplift_tree = synth.max(axis=1))
.drop(columns=['a_' + str(i) for i in treat_cols]))
plot_gain(auuc_metrics, outcome_col='conversion', treatment_col='is_treated')
auuc_score(auuc_metrics, outcome_col='conversion', treatment_col='is_treated')
附3(参考文章):
https://blog.csdn.net/jinping_shi/article/details/105583375
https://zhuanlan.zhihu.com/p/192960265
https://cloud.tencent.com/developer/news/705938
https://cloud.tencent.com/developer/article/1620903
https://blog.csdn.net/u011984148/article/details/105721582
https://www.zhihu.com/question/391900914
https://www.zhihu.com/question/41252833