NLP预训练模型小型化与部署的那些事儿
点击左上方蓝字关注我们

课程简介
“手把手带你学NLP”是基于飞桨PaddleNLP的系列实战项目。本系列由百度多位资深工程师精心打造,提供了从词向量、预训练语言模型,到信息抽取、情感分析、文本问答、结构化数据问答、文本翻译、机器同传、对话系统等实践项目的全流程讲解,旨在帮助开发者更全面清晰地掌握百度飞桨框架在NLP领域的用法,并能够举一反三、灵活使用飞桨框架和PaddleNLP进行NLP深度学习实践。

6月,百度飞桨 & 自然语言处理部携手推出了12节NLP视频课,课程中详细讲解了本实践项目。
观看课程回放请戳:
https://aistudio.baidu.com/aistudio/course/introduce/24177
欢迎来课程QQ群(群号:758287592)交流吧~~
近年来,基于Transformer结构使用海量数据自监督训练得到的预训练模型不断刷新着自然语言处理各项任务的最好成绩,同时被不断刷新的还有模型规模,大力出奇迹不再只是玩梗。不断上升的模型规模给预测部署带来了巨大困难。
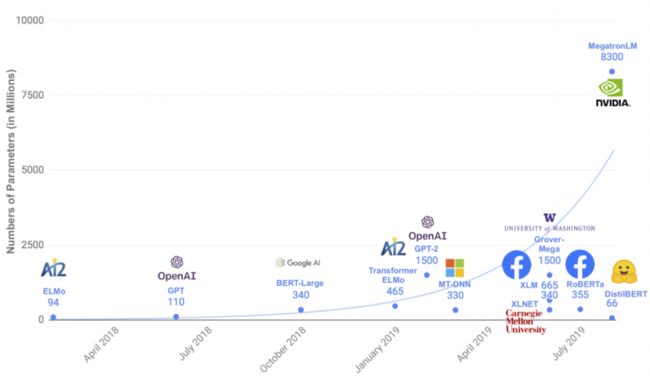
模型压缩技术的发展使得这个问题得到了缓解。模型压缩能够保证一定精度的情况下,降低模型大小,进而减少推理时间,同时提升内存和计算效率。
当前模型压缩的基本方法主要包括量化、裁剪和蒸馏。量化和裁剪通常需要更为底层的支持,如低比特和稀疏矩阵运算的支持;相比之下,蒸馏是更为简单有效的模型压缩方法。通过模型蒸馏技术,ERNIE-Tiny在4倍提速的同时模型效果只有少量下降;非Transformer结构的BOW/CNN/RNN简单模型(速度成百上千倍于预训练模型)效果也可以有效提升。

本项目基于PaddleNLP围绕模型蒸馏进行实践教学,主要包含以下内容:
如何通过PaddleNLP快速使用通用蒸馏模型ERNIE-Tiny在特定任务微调训练
如何使用PaddleNLP快速实现在特定任务上使用ERNIE模型蒸馏Bi-LSTM模型
产出小模型后如何使用Paddle Inference进行预测部署
ERNIE-Tiny 微调
ERNIE-Tiny是使用ERNIE 2.0 Base模型经通用蒸馏得到的轻量级模型,蒸馏时使用蒸馏信号(知识)包括ERNIE教师模型的预测结果(logits或软标签,这能够表示更细粒度的类别概率信息,提供信息量更大的知识)和中间各层的结果(包括中间层的输出表征和attention分布)。
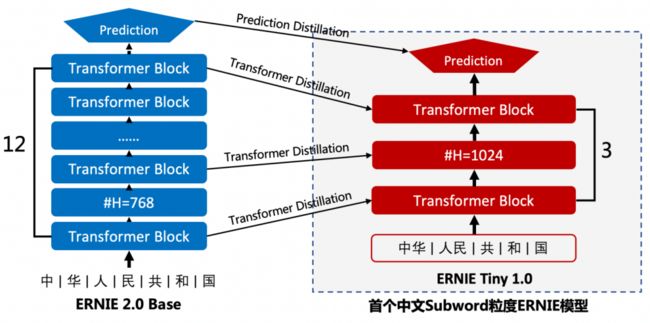
ERNIE-Tiny更浅(12层->3层transformer block)、更短(字粒度->subword粒度缩短输入长度),并加大宽度(768->1024 hidden size)弥补模型变浅带来的效果损失,在4倍提速的同时模型效果只有少量下降。直接使用ERNIE-Tiny在下游任务上微调即可得到兼顾效果与性能的模型。
使用PaddleNLP可以快速实现ERNIE-Tiny在特定任务上的微调训练,只需将模型换成ERNIE-Tiny即可。
from paddlenlp.transformers import ErnieTinyTokenizer, ErnieForSequenceClassification
# 创建Ernie Tiny模型使用的tokenzier
tokenizer = ErnieTinyTokenizer.from_pretrained('ernie-tiny')# 创建使用Ernie Tiny预训练模型的句子分类模型
model = ErnieForSequenceClassification.from_pretrained('ernie-tiny', num_classes=2)# 打印查看Ernie Tiny
ERNIE 蒸馏 Bi-LSTM
虽然ERNIE-Tiny相比ERNIE模型有4倍提速,但这在一些性能要求苛刻的部署场景中是不够的,大量CPU和低时延的场景只能使用轻量级的BOW/CNN/RNN模型,模型蒸馏同样可以用来提升这些模型的效果。
参考论文 Distilling Task-Specific Knowledge from BERT into Simple Neural Networks 实现在特定任务上使用复杂大模型蒸馏简单模型。我们的任务数据集使用中文情感分类数据集chnsenticorp;教师模型使用ERNIE微调得到的模型,学生模型使用Bi-LSTM模型;蒸馏信号(知识)使用教师模型输出的logits;另外通过数据增强扩充数据并使用教师模型预测获取更多知识。
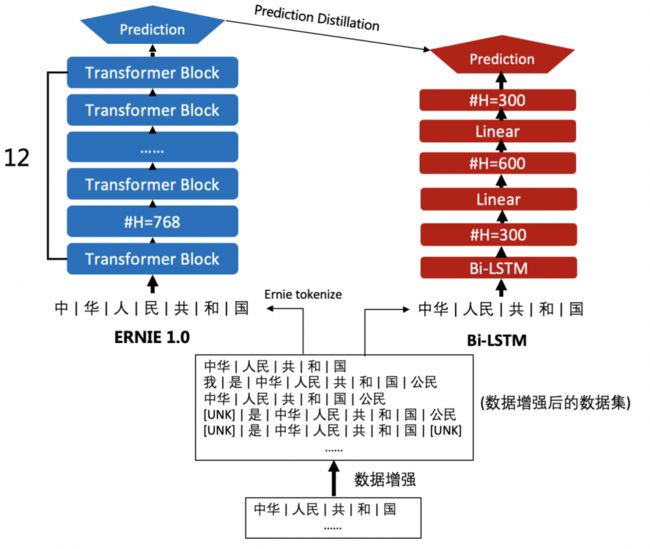
对于教师模型的训练不再赘述,只需将第一部分微调训练中的模型换为教师模型即可,这里只对蒸馏训练学生模型的内容进行介绍。
蒸馏训练的过程也同之前按照:
数据准备 -> 模型定义 -> 优化策略 -> 迭代训练四步说明;
略有不同的只是在数据准备中加入了数据增强,在优化目标中考虑教师模型预测产生的软标签。
2.1 数据准备
数据准备流程如下:

加载数据集
使用PaddleNLP提供的load_dataset API,即可一键完成数据集加载,返回包含了相应数据集的MapDataset对象。
from paddlenlp.datasets import load_dataset# 获取内置的数据集
train_ds, dev_ds = load_dataset('chnsenticorp', splits=["train", "dev"])
数据增强
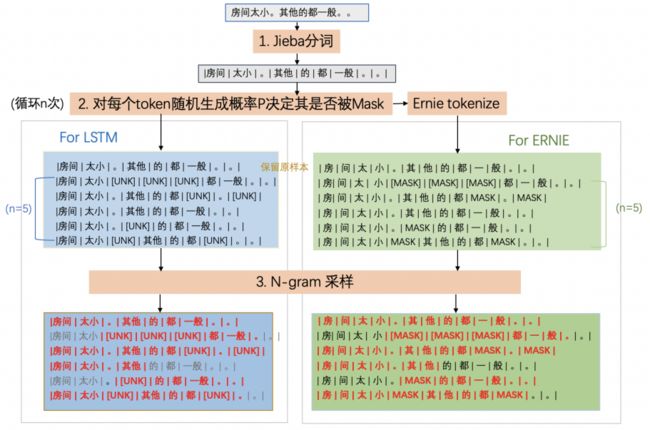
异构网络难以直接使用网络的中间内容作为知识,考虑通过数据增强扩充数据并使用教师模型获取更多的软标签作为知识,参照论文中给出的数据增强方法,这里实现了以下两种策略:
Masking,即以一定的概率将句子中的token替换成[MASK]。(类似图像领域的随机噪声)
n-gram sampling,即以一定的概率从句子中采样n-gram作为样本,其中n的范围可进行设置。(类似图像领域的随机裁剪)
在实现中,数据增强基于词(whole word)粒度进行,使用jieba分词。jieba分词也是学生模型Bi-LSTM使用的tokenize方式,顺带将tokenize处理也一并在这里实现;另外教师模型ERNIE使用了不同的tokenize方式(ErnieTokenizer),结果中也将包含这两种tokenize后的数据。
# 教师模型Ernie使用的tokenizer
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
def apply_data_augmentation(data,
n_iter=2,
p_mask=0.1,
p_ng=0.25,
ngram_range=(2, 10)):
# 固定seed便于演示复现
np.random.seed(2021)
# 存放扩充后的数据
new_data = []
# 循环对数据集的每条样本进行数据增强
for example in data:
# 使用jieba分词,基于词粒度进行数据增强
words = [word for word in jieba.cut(example['text'])]
# 学生模型使用jieba分词结果,教师模型使用ErnieTokenizer结果
lstm_tokens, ernie_tokens = words, tokenizer.tokenize(example['text'])
# 将原样本数据加入扩充数据集
new_data.append({
"lstm_tokens": lstm_tokens,
"ernie_tokens": ernie_tokens,
"label": example['label']
})
for _ in range(n_iter):
# 存放数据增强后学生模型和教师模型的tokenize结果
lstm_tokens, ernie_tokens = [], []
# 1. Masking
for word in words:
# 基于词粒度,词内容整体list处理
if np.random.rand() < p_mask:
lstm_tokens.append(['[UNK]'])
ernie_tokens.append([tokenizer.mask_token])
else:
lstm_tokens.append([word])
ernie_tokens.append(tokenizer.tokenize(word))
# 2. N-gram sampling
if np.random.rand() < p_ng:
ngram_len = min(np.random.randint(ngram_range[0], ngram_range[1] + 1), len(words))
start = np.random.randint(0, len(words) - ngram_len + 1)
lstm_tokens = lstm_tokens[start:start + ngram_len]
ernie_tokens = ernie_tokens[start:start + ngram_len]
# 展开得到tokenize的结果:
# lstm:[[房间], [太小]] -> [房间, 太小] ernie:[[房, 间], [太, 小]] -> [房, 间, 太, 小]
lstm_tokens, ernie_tokens = list(chain(*lstm_tokens)), list(chain(*ernie_tokens))
# 将新样本加入扩充数据集
new_data.append({
"lstm_tokens": lstm_tokens,
"ernie_tokens": ernie_tokens,
"label": example['label']
})
return new_data
实现数据增强策略之后,可以使用数据集对象的map()方法完成数据增强的操作。map()将使用当前数据集作为参数调用该函数(batched=True时)。
# 执行数据增强,`batched=True`时执行`data_aug_fn(train_ds)`
train_ds = train_ds.map(apply_data_augmentation, batched=True)tokenize 与 id 化
获得数据增强扩充的数据集后,需要将文本数据转换为模型使用的id数据,包括tokenize和id化处理。由于tokenize处理已经在数据增强过程中一并完成,下面实现中可选的进行tokenize。另外由于学生模型Bi-LSTM和教师模型ERNIE使用了不同的tokenize方式,对应也需要两个不同的转换处理。
# 学生模型id转换使用的词典
vocab = Vocab.load_vocabulary(
filepath='senta_word_dict_subset.txt',
unk_token='[UNK]',
pad_token='[PAD]')
def convert_example_for_lstm(example, max_seq_length=128, is_tokenized=True):
"""
将单条样本转成学生模型(Bi-LSTM)需要的输入
"""
# tokenize分词
words = example['lstm_tokens'] if is_tokenized else list(jieba.cut(example['text']))
# 使用vocab转为id数据
input_ids = [vocab[word] for word in words][:max_seq_length]
valid_length = np.array(len(input_ids), dtype='int64')
return input_ids, valid_length, np.array(example['label'], dtype="int64")
def convert_example_for_ernie(example, max_seq_length=128):
"""
将单条样本转成教师模型(ERNIE)需要的输入
"""
example = tokenizer(example['ernie_tokens'], max_seq_len=max_seq_length, is_split_into_words=True)
return example['input_ids'], example['token_type_ids']
def convert_example_for_distill(example):
"""
将单条样本同时转成大小模型均需要的输入
"""
# 得到Ernie的输入
ernie_inputs = convert_example_for_ernie(example)
# 得到Bi-LSTM的输入
lstm_inputs = convert_example_for_lstm(example)
return ernie_inputs + lstm_inputs
之后同样使用数据集的map()方法完成转换处理。注意,不同于上面数据增强的操作,这里的转换函数作用于单条样本(对应batched=False)。另外这里也将转换的操作延迟到实际取数据时进行,这可以通过设置lazy=True实现。
from functools import partial
# 训练集转换,`lazy=True`时在实际取数据时进行转换
train_ds = train_ds.map(convert_example_for_distill, lazy=True)
# 验证集转换
dev_ds = dev_ds.map(partial(convert_example_for_lstm, is_tokenized=False), lazy=True)构造batch数据
每条样本转换为模型使用的id数据之后,还需要将数据组织成batch输入。这包括两个操作:
将多条样本组成batch,这可以通过Paddle的paddle.io.BatchSampler接口实现。(batch_sampler组件)
将batch内的数据的各字段进行补齐等操作(tensor化),这可以通过paddlenlp.data下的Pad、Stack等接口实现。(batchify_fn组件)
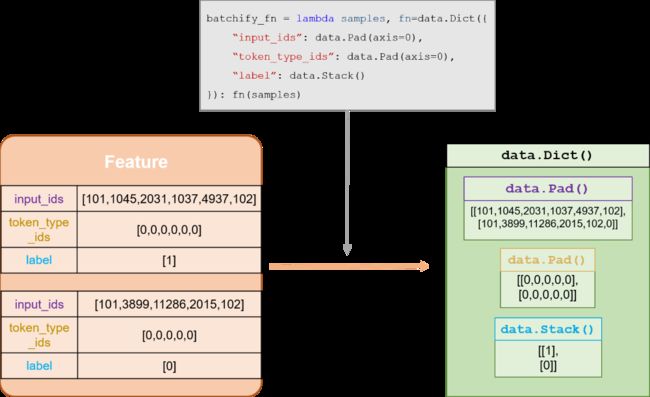
在数据集、batch_sampler 组件和 batchify_fn 组件都定义完成之后,可以使用paddle.io.DataLoader构造batch数据的迭代器。
2.2 模型定义
蒸馏训练中的教师模型和学生模型分别为ERNIE和Bi-LSTM。
ERNIE 教师模型
目前PaddleNLP已经内置了包括ERNIE在内的多种基于预训练模型的常用任务的下游网络,这些网络在paddlenlp.transformers下,均可实现一键调用。这里直接加载提前训练好的教师模型。
from paddlenlp.transformers import ErnieForSequenceClassification
# 导入已微调训练好的教师模型
teacher = ErnieForSequenceClassification.from_pretrained("/home/aistudio/data/data88390/")
Bi-LSTM 学生模型
参照论文中的结构进行Bi-LSTM模型实现:embedding层后经过一个双向LSTM,将两个方向最后的hidden state拼接后送入带有tanh激活函数的线性变换层,最后由分类层输出预测结果。
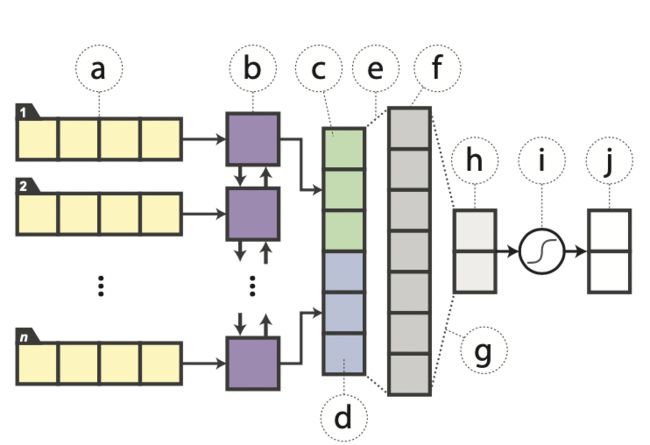
其中a表示输入的embeddings,b表示双向LSTM,c、d分别表示反向和前向的隐藏状态,e、g表示两个全连接层,其中e中带有激活函数,f是隐藏层表示,h是网络的logit输出,i表示softmax激活函数,j是最终输出的概率。
class BiLSTM(nn.Layer):
def __init__(self,vocab_size,embed_dim,hidden_size,output_dim,num_layers=1,
dropout_prob=0.0,
padding_idx=0,
init_scale=0.1):
super(BiLSTM, self).__init__()
self.embedder = nn.Embedding(vocab_size, embed_dim, padding_idx)
self.lstm = nn.LSTM(
embed_dim,
hidden_size,
num_layers,
'bidirect', # 双向LSTM
dropout=dropout_prob)
self.fc = nn.Linear(
hidden_size * 2,
hidden_size,
weight_attr=paddle.ParamAttr(initializer=I.Uniform(
low=-init_scale, high=init_scale)))
self.output_layer = nn.Linear(
hidden_size,
output_dim,
weight_attr=paddle.ParamAttr(initializer=I.Uniform(
low=-init_scale, high=init_scale)))
def forward(self, x, seq_len):
# 对文本输入接入Embedding层
x_embed = self.embedder(x)
# 文本表示、文本长度作为双向LSTM的输入,经过计算得到LSTM的输出和终态表示
lstm_out, (hidden, _) = self.lstm(
x_embed, sequence_length=seq_len)
# 将终态两个方向最后一层的隐状态拼接在一起
out = paddle.concat((hidden[-2, :, :], hidden[-1, :, :]), axis=1)
# 经过一层线性层和Tanh激活函数
out = paddle.tanh(self.fc(out))
# 经过最后一层线性层得到logit并返回
logits = self.output_layer(out)
return logits
# 根据超参创建Bi-LSTM学生模型
student = BiLSTM(vocab_size, emb_dim, hidden_size,
output_dim, num_layers, dropout_prob,
padding_idx)2.3 优化策略与模型训练
完成模型定义后,下一步创建优化目标和优化器并迭代数据进行蒸馏训练。
相比于此前的模型训练,这里的蒸馏训练以最小化学生模型和教师模型软标签预测结果的均方误差损失为优化目标。单步训练过程也多出一个执行教师模型的前向预测获取软标签的步骤。
# 定义损失函数
mse_loss = nn.MSELoss()
# 定义优化器
optimizer = paddle.optimizer.Adadelta(
learning_rate=1.0, rho=0.95, parameters=student.parameters())
# 教师模型设置为eval模式
teacher.eval()
# 定义评估指标与评估函数
metric = paddle.metric.Accuracy()
best_acc = 0
def evaluate(model, metric, data_loader):
model.eval()
metric.reset()
for i, batch in enumerate(data_loader):
input_ids, seq_len, labels = batch
logits = model(input_ids, seq_len)
# 每个step调用compute和update
correct = metric.compute(logits, labels)
metric.update(correct)
# 最后调用accumulate得到最后的评价指标(ACC)值
res = metric.accumulate()
model.train()
return res
max_step = 2for epoch in range(epochs):
for i, batch in enumerate(train_data_loader):
global_step += 1
# 从data loader中取出一个batch data
teacher_input_ids, teacher_segment_ids, student_input_ids, seq_len, labels = batch
# 教师模型执行前向计算,获取logits作为蒸馏信号。`no_grad`下的内容将不进行梯度计算
with paddle.no_grad():
teacher_logits = teacher(teacher_input_ids, teacher_segment_ids)
# 学生模型执行前向计算
logits = student(student_input_ids, seq_len)
# 计算学生模型和教师模型logits输出的均方误差损失
loss = mse_loss(logits, teacher_logits)
# 学生模型执行反向计算获取梯度,梯度计算及参数更新、优化器更新
loss.backward()
# 优化器更新学生模型的参数权重,然后清空梯度
optimizer.step()
optimizer.clear_grad()
下面是ERNIE模型、Bi-LSTM模型以及蒸馏得到的Bi-LSTM模型在ChnSentiCorp的验证集上的准确率指标:
Accuracy(%) |
|
|---|---|
ERNIE-1.0 |
95.55 |
Bi-LSTM |
92.00 |
Distilled Bi-LSTM |
93.333 |
预测部署
模型训练完成之后,我们来实现模型的预测部署。虽然训练阶段使用的动态图模式有诸多优点,包括Python风格的编程体验(使用RNN等包含控制流的网络时尤为明显)、友好的debug交互机制等。但Python动态图模式无法更好的满足预测部署阶段的性能要求,同时也限制了部署环境。
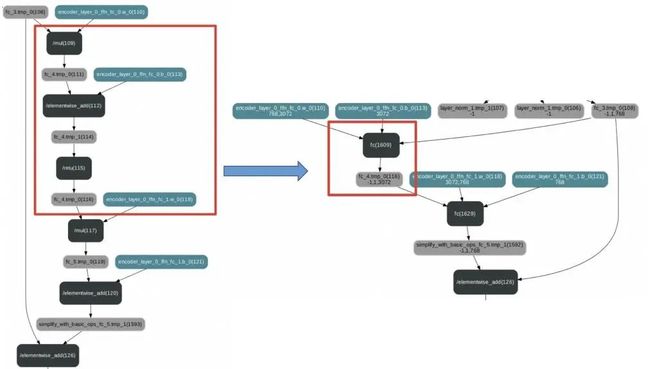
静态图是预测部署通常采用的方式。通过静态图中预先定义的网络结构,一方面无需像动态图那样执行开销较大的Python代码;另一方面,预先固定的图结构也为基于图的优化提供了可能,这些能够有效提升预测部署的性能。常用的基于图的优化策略有内存复用和算子融合,这需要预测引擎的支持。下面是算子融合的一个示例(将Transformer Block的FFN中的矩阵乘->加bias->relu激活替换为单个算子):
高性能预测部署需要静态图模型导出和预测引擎两方面的支持,这里分别介绍。
3.1 动转静导出模型
基于静态图的预测部署要求将动态图的模型转换为静态图形式的模型(网络结构和参数权重)。
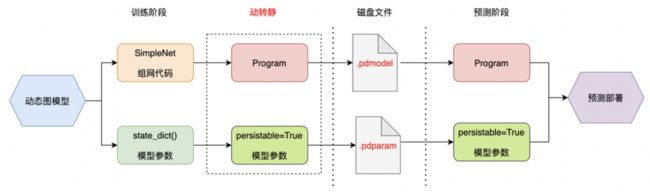
Paddle静态图形式的模型(由变量和算子构成的网络结构)使用Program来存放,Program的构造可以通过Paddle的静态图模式说明,静态图模式下网络构建执行的各API会将输入输出变量和使用的算子添加到Program中。
import paddle # 默认为动态图模式,这里开启静态图模式
paddle.enable_static() # 定义输入变量,静态图下变量只是一个符号化表示,并不像动态图 Tensor 那样持有实际数据
x = paddle.static.data(shape=[None, 128], dtype='float32', name='x')
linear = paddle.nn.Linear(128, 256, bias_attr=False)# 定义计算网络,输入和输出也都是符号化表示
y = linear(x)# 打印 program
print(paddle.static.default_main_program())# 关闭静态图模式
paddle.disable_static()
结合Paddle的静态图机制,Paddle提供了从动态图模型转换并导出静态图模型(包括网络结构和参数权重)的功能,通过jit.to_static和jit.save完成。
①paddle.jit.to_static 完成动态图模型到静态图模型的转换。
网络结构:将动态图模型的forward函数转写(重点将Python控制流转换为Paddle对应API的调用),然后以静态图模式执行,生成Program。
参数权重:将动态图模型的参数在生成Program时对应到其中的变量上。
动转静时还需要使用InputSpec提供模型输入的描述信息(shape、dtype和name)保证Program构建过程中形状和数据类型的正确性。
# 设置log输出转写的代码内容# paddle.jit.set_code_level(100)
# 加载动态图模型
param_state_dict = paddle.load("best_model_7380_933.pdparams")
student.set_state_dict(param_state_dict)
# 动转静,通过`input_spec`给出模型所需输入数据的描述,shape中的None代表可变的大小,类似上面静态图模式中的`paddle.static.data`
model = paddle.jit.to_static(
student,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype="int64"), # input_ids: [batch_size, max_seq_len]
paddle.static.InputSpec(
shape=[None], dtype="int64") # length: [batch_size]
])
②paddle.jit.save 完成静态图模型(网络结构和参数权重)的序列化保存。
网络结构:以.pdmodel为扩展名的文件,可以使用visualdl来可视化。
参数权重:以.pdiparams为扩展名的文件。
3.2 使用推理库预测
获得静态图模型之后,我们使用Paddle Inference进行预测部署。Paddle Inference是飞桨的原生推理库,作用于服务器端和云端,提供高性能的推理能力。
Paddle Inference采用 Predictor 进行预测。Predictor 是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。另外Paddle Inference提供了Python、C++、GO等多语言的API,可以根据实际环境需要进行选择,为了便于演示这里使用Python API来完成,其已在安装的Paddle包中集成,直接使用即可。使用 Paddle Inference 开发 Python 预测程序仅需以下步骤:

import paddle.inference as paddle_infer
# 1. 创建配置对象,设置预测模型路径
config = paddle_infer.Config("infer_model/model.pdmodel", "infer_model/model.pdiparams")# 启用 GPU 进行预测 - 初始化 GPU 显存 100M, Deivce_ID 为 0# config.enable_use_gpu(100, 0)
config.disable_gpu()# 2. 根据配置内容创建推理引擎
predictor = paddle_infer.create_predictor(config)# 3. 设置输入数据# 获取输入句柄
input_handles = [
predictor.get_input_handle(name)
for name in predictor.get_input_names()
]# 获取输入数据
data = dev_batchify_fn([dev_ds[0]])# 设置输入数据
for input_field, input_handle in zip(data, input_handles):
input_handle.copy_from_cpu(input_field)
# 4. 执行预测
predictor.run()
# 5. 获取预测结果# 获取输出句柄
output_handles = [
predictor.get_output_handle(name)
for name in predictor.get_output_names()
]# 从输出句柄获取预测结果动手试一试
是不是觉得很有趣呀。小编强烈建议初学者参考上面的代码亲手敲一遍,因为只有这样,才能加深你对代码的理解呦。
本次项目对应的代码:
https://aistudio.baidu.com/aistudio/projectdetail/2114383
更多PaddleNLP信息,欢迎访问GitHub点star收藏后体验:
https://github.com/PaddlePaddle/PaddleNLP
加入交流群,一起学习吧
如果你在学习过程中遇到任何问题或疑问,欢迎加入PaddleNLP的QQ技术交流群!

回顾往期
越学越有趣:『手把手带你学NLP』系列项目01 ——词向量应用的那些事儿
越学越有趣:『手把手带你学NLP』系列项目02 ——语义相似度计算的那些事儿
越学越有趣:『手把手带你学NLP』系列项目03 ——快递单信息抽取的那些事儿
越学越有趣:『手把手带你学NLP』系列项目04 ——实体关系抽取的那些事儿
越学越有趣:『手把手带你学NLP』系列项目05 ——文本情感分析的那些事儿
越学越有趣:『手把手带你学NLP』系列项目06 ——机器阅读理解的那些事儿
越学越有趣:『手把手带你学NLP』系列项目07 ——机器翻译的那些事儿
越学越有趣:『手把手带你学NLP』系列项目08 ——“不缺钱,只缺人” ,同传翻译的那些事儿
越学越有趣:『手把手带你学NLP』系列项目09 ——“此苹果非彼苹果”看意图识别的那些事儿
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
