基于中心引导判别学习的弱监督视频异常检测
WEAKLY SUPERVISED VIDEO ANOMALY DETECTION VIA CENTER-GUIDED DISCRIMINATIVE LEARNING
基于中心引导判别学习的弱监督视频异常检测
abstract
由于异常视频内容和时长的多样性,监控视频中的异常检测是一项具有挑战性的任务。在本文中,我们将视频异常检测看作是一个弱监督下视频片段异常分数的回归问题。因此,我们提出了一个称为异常Regression Net(AR-Net)的异常检测框架,它在训练阶段只需要视频级别的标签。此外,为了学习异常检测的判别特征,我们设计了一个动态多实例学习损失和一个中心损失。前者用于扩大异常实例和正常实例之间的类间距离,而后者用于缩小正常实例的类内距离。综合实验是在一个具有挑战性的benchmark上进行的: Shang-haiTech。该方法为Shang-haiTech数据集上的视频异常检测提供了新的最优结果。
Introduction
视频异常检测是计算机视觉中一项重要而又具有挑战性的任务,被广泛应用于犯罪预警、智能视频监控和证据收集等领域。根据研究[1],弱监督视频异常检测有两种范式:一元分类和二元分类。视频异常检测是计算机视觉中一项重要而又具有挑战性的任务,被广泛应用于犯罪预警、智能视频监控和证据收集等领域。根据研究[1],弱监督视频异常检测有两种范式:一元分类和二元分类。异常通常被定义为不同于以前作品中常见模式的视频内容模式[2] [3] [4] [5] [6]。基于这一定义,基于一元分类范式的方法只使用正常的训练样本来建模通常的模式。然而,不可能在一个训练集中收集所有种类的正常样本。因此,在这种模式下,不同于训练视频的正常视频可能会出现虚假警报。为了解决这个问题,引入了二进制分类模式,其中训练数据包含异常和正常视频。根据二分类的规则一些关于异常检测的研究已经被发表。在【1】中,视频异常检测被表述为噪声样本下的全监督学习任务。作为一种修正,提出了一种图形卷积网络(GCN)来训练动作分类器。GCN和动作分类器被交替优化。
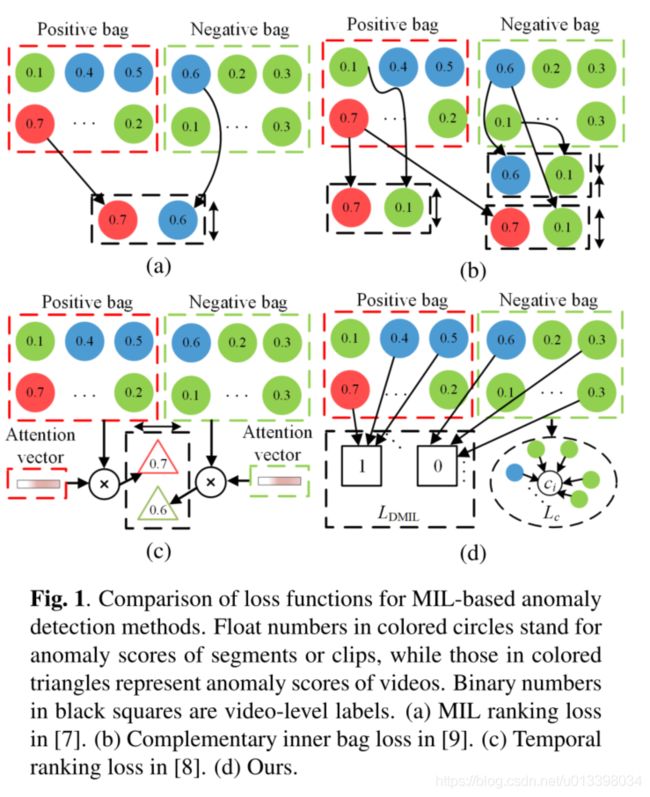
在本文中,我们将视频异常检测描述为一个遵循二进制分类范式的弱监督学习问题,在训练阶段只涉及视频级标签。最近,多实例学习(MIL)已经成为若干计算机视觉任务中的主要技术,包括弱监督时间活动定位和分类[10] [11]和弱监督对象检测[12]。7,8,9是一些基于MIL的视频异常检测研究。在这些方法中,每个训练视频被视为一个包,视频剪辑被视为实例。异常视频被视为阳性包,正常视频被视为阴性包。Sultani等人。[7]提出了一种以C3D网络[13]提取的特征作为输入的深度MIL排序模型。为了区分异常实例和正常实例的异常得分,提出了深度MIL排序损失。张某等人。[9]提出了一种互补性的内包丢失机制,在减小类内距离的同时,增大实例的类间距离。异常视频和正常视频的最高和最低异常得分是必需的。Zhu and Newsam[8]提出了一个根据异常得分计算的时间排名损失。视频的异常得分是视频异常得分向量和注意力向量的加权和。然而,如图1所示,这些方法采用了成对计算的损失,在此基础上,模型的检测能力部分取决于批次大小。换句话说,检测性能在一定程度上受到图形内存的限制。在这项工作中,我们研究了一种在没有配对视频实例的情况下最大化类间距离和最小化类内距离的方法。我们提出了一种称为异常回归网络(AR-Net)的框架和两种新的损失来学习视频级弱监督下的区分特征。如图1-(D)所示,提出了动态多示例学习损失(LDMIL),以使特征更容易分离。LDMIL值是通过计算视频片段的异常分数与其对应的视频标签之间的交叉熵来获得的。中心损失被设计为每个训练正常视频中视频片段的异常得分与其对应的平均异常得分Ci之间的距离。通过最小化这两个损失,可以得到用于视频异常检测的区分性特征表示。综合实验是在一个基准上进行的:ShanghaiTech[14]。我们的方法得到了一个新的最先进的结果,在ShanghaiTech数据集上获得了4.94%的曲线下面积(AUC)的绝对收益。
Proposed Method
在本节中,我们首先定义符号和问题陈述。然后描述了所提出的特征提取网络。最后,我们给出了我们的AR-Net,然后详细描述了提出的损失。
问题陈述:在异常检测数据集中,由n个视频组成的训练集由χ={xi}i=1表示。数据集的时间持续时间被定义为T={ti}i=1,其中ti是第i个视频的剪辑编号。视频异常标签集表示为Y={yi}i=1,其中yi={0,1}。在测试阶段,视频x的预测异常分数向量表示为s={sj}j=1,其中sj∈[0,1],第j个视频片段的异常分数。
2.1. Feature Extraction
为了利用视频的外观和运动信息,使用在Kinetics[15]数据集上预先训练的膨胀3D(I3D)[15]作为特征提取网络。输入视频被分成不重叠的剪辑,每个剪辑包含16个连续帧。I3D的RGB和光流版本分别由I3DRGB和I3D光流表示。前者以RGB帧为输入,后者以光流帧为输入。我们将I3DRGB倒数第二层的特征与I3D光学浮点连接在一起,这是我们视频剪辑的最终呈现。图2中的特征矩阵Xi展示了训练视频Xi中的特征组成,Xi的维度为F×ti,其中F为片段特征的维度。而不是原始视频片段被输入到我们的AR-Net。
2.2. Anomaly Regression Network
AR-Net的体系结构如图2所示。AR-Net中的全连接层(FC层)和异常回归层(AR层)仅需要视频级标签即可进行视频异常检测。我们采用ReLU [17]作为FC层的激活功能。为了避免过度拟合,FC-Layer引入了Dropout [18],可以将其形式化如下:
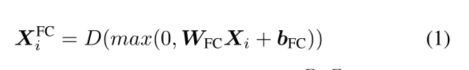
其中D(·)表示Dropout,WFC∈RF×F和bFC∈RF×1是可从训练数据中优化的可学习参数,XFC i∈RF×ti是FC层输出特征输出的第i个视频特征。
我们根据AR-Laye在表示XFC i和异常得分向量sir(这是一个完全连接的层)之间建立映射函数。AR层可以表示如下:
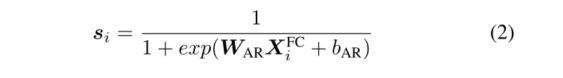
其中WAR∈R1×F,bAR∈R1是可学习的参数,si∈R1×ti。异常分数向量表示实例被分类为异常的概率。
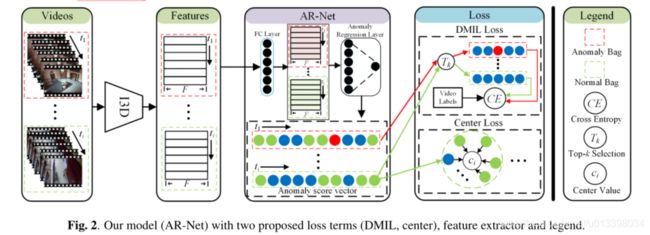
2.3. Dynamic Multiple-Instance Learning Loss
如第1节所述,视频异常检测在本文中被视为MIL任务。在MIL中,一个正袋至少包含一个正实例,一个负袋不包含正实例,即异常视频至少包含一个异常事件,而正常视频不包含异常事件。为了在[10] [11]中的k-max MIL损失的启发下,在弱监督下扩大异常实例与正常实例之间的类间距离,我们提出了一种动态多实例学习(DMIL)损失,该损失考虑了视频时长的多样性。
与[7] [8] [9]中使用的基于MIL的损失函数的最大选择方法不同,我们引入了[10] [11]中使用的kmax选择方法,以获得k-max异常分数。具体来说, k是根据视频中剪辑的数量确定的。

其中α是超参数。因此,第i个视频的k-max异常得分可以表示为:
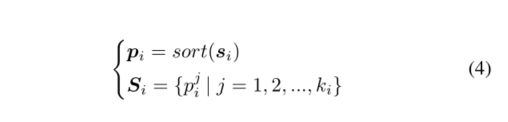
其中第i个视频的si是异常得分矢量,sort(·)是降序排序运算符,pi是排序后的si。因此,Si由si中的前基元组成。 DMIL损失可以表示如下:(取前k个作为loss计算范围)
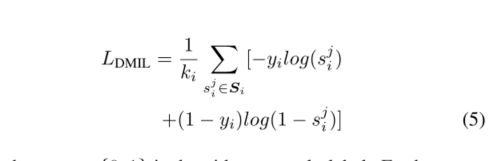
其中yi = {0,1}是视频异常标签。此外,在[10] [11]中,我们没有计算所选k分数的平均值与视频标签之间的交叉熵,而是分别计算了所选k分数和视频标签之间的交叉熵作为实例损失。噪声标签将影响样本特征的异常评分,从中可以计算出平均异常评分。虽然我们的DMIL损失着重于单个异常分数,而不是平均分数。因此,这种损失阻止了噪声标签带来的误差的传播。
2.4. Center loss for Anomaly Scores Regression
DMIL损失的目的是扩大实例的类间距离。然而,由于异常视频中正常片段和异常片段的异常分数在训练初期是相似的,所以最大值选择方法和k-最大值选择方法都不可避免地会产生错误的标签分配。因此,DMIL丢失会导致正常实例的类内距离增大,从而降低测试阶段的检测精度。受[19]中心丢失的启发,我们提出了一种新的异常分数回归中心丢失方法来解决上述问题。在[19]中,中心损失学习每类的特征中心,并惩罚特征表示与其对应的类中心之间的距离。在我们的例子中,提出的异常分数回归的中心损失收集了正常视频片段的异常分数。我们异常分数回归的中心损失可以表示为:
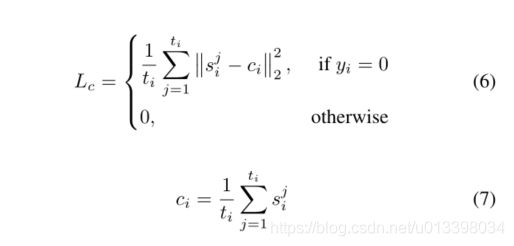
其中Ci是第i个视频的异常得分向量Si的中心。
2.5. Optimization
AR网络的总损失函数可以表示如下:
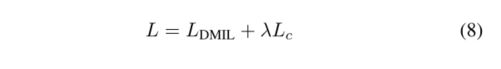
为了在训练阶段实现两个损失之间的平衡,我们经验地设置了λ=20。
3. EXPERIMENTS
3.1. Experiments Setup
数据集:提出的AR-Net是在一个具有挑战性的数据集上进行评估的,该数据集包含具有可变场景、内容和持续时间的未修剪视频。上海科技[14]是一个包含437个视频、13个场景130个异常的数据集。然而,该数据集是用于一元分类的,因此所有的训练视频都是正常的[14]。为了使二进制分类可用,我们采用了文献[1]中提出的分裂版本。具体来说,训练视频有238个,测试视频有199个。
评估指标:类似于前人的工作[1][14][7],我们使用(ROC)和虚警率(FAR)的曲线下面积(AUC)作为评估指标,阈值为0.5。在视频异常检测任务中,AUC越高,模型的性能越好,正常视频的FAR越低,异常检测方法的鲁棒性越强。
实现细节:我们将I3DRGB和I3DOptional-Flowas相结合,我们的特征提取器称为I3DConc。I3DConc的特征是来自I3DRGB和I3D光流的特征的串联。此外,我们的特征提取器没有微调。基于TV-L1算法[16]生成每个剪辑的光流帧。经验上,我们为上海科技大学的数据集设置了α=4。AR-Net的权值采用Xavier方法[20]进行初始化,FC层的丢包率为0.7。我们采用了ADAM优化器[21],批大小为60,从训练集中随机抽取了30个正常视频和30个异常视频。在我们的实验中,学习速率始终是10−4。
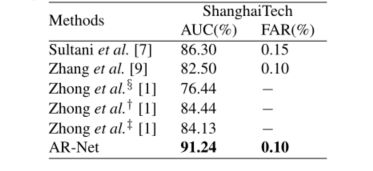
表1。建议方法与3种现有方法的AUC和FAR。§、†和‡分别表示了基于C3D的异常检测模型、基于TSNRGB的异常检测模型和基于TSNOptional-Flowin的异常检测模型[1]。
3.2. Comparison Results
表1显示了我们的方法与上海科技大学数据集上现有方法[7][1][9]的比较。为了与上海科技大学数据集基于MIL的工作进行比较,我们复制了[9]中的方法,并采用了Sultani等人提供的开放源代码。[7]进行异常检测。上述两个模型是通过预先训练的C3D得到的。如表1所示,[9]实现了82.50%的帧级AUC。同时,[7]的帧级AUC达到86.30%,优于现有最好的方法[1]。我们的方法大大超过了Sultani等人。[7]和钟等人的†[1],帧级AUC值为91.24%。此外,我们的方法是唯一一种在上海科技大学数据集的AUC超过90%的方法。
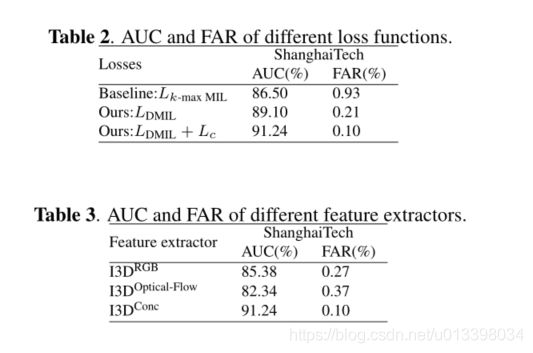
3.3. Ablation Study
表2中使用不同损失函数的比较结果说明了所提出的Lcand LDMIL在我们的AR-Net中所带来的提升。在我们的消融研究中,涉及基于k-max选择的MIL损失(LK-max MIL)的AR-net被视为基线。在上海科技上实现了86.50%的帧级AUC。而提出的基于DMIL损失的AR-Net在上海科技大学数据集上获得了89.10%的帧级AUC,从而提高了性能。此外,借助拟议的Lc,有关ShanghaiTech的FAR降低到了基线实现的FAR的1/9。为了展示视频外观和运动信息带来的性能,我们比较了基于不同特征提取器的异常检测结果。如表3所示,采用I3DRGB的AR-NET实现了85.38%的帧级AUC。基于I3D光流的AR-Net实现了82.34%的帧级AUC。采用I3DConc的AR-Net提高了性能,帧级AUC达到91.24%。
3.4. Qualitative Analysis
如表1所示,我们的方法超过了最近基于MIL的大多数工作。在ShanghaiTech中,有时异常会占整个视频的一小部分。在基于分段的方法中[7] [9],尽管每个视频都被分为32个不重叠的分段,但每个分段中的异常事件可能只占总数的一小部分。
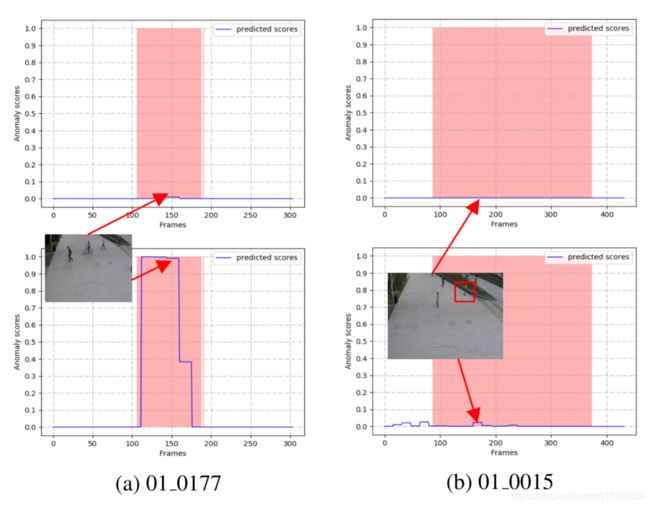
换句话说,异常帧的特征将在一个段中被正常帧所淹没。结果,包含异常的片段倾向于被认为是正常模式,即,由这些片段训练的异常检测模型缺乏检测短期异常的能力。在[10] [11]等我们的基于片段的方法中,视频被分成具有固定帧数的片段。使用此策略的异常检测模型可避免异常被正常帧淹没,并能够识别短期异常。如图3-(a)所示,[7]中的模型(在第一行中显示)无法识别非法自行车,而我们的模型(在第二行中)则可以识别。
如图3-(b)的第一行所示,[7](在第一行中说明)和我们的方法(在第二行中)均未能检测到“ 01 0015”中的异常事件。原因是:1)用红色框标记的异常仅占视频场景的局部,而使用全局输入的方法则容易忽略局部异常2)人行道上滑板的异常在视觉上无法区分从正常行为来看,因此异常片段和非片段是不可分离的。总而言之,对于当前模型,在此类场景中进行视频异常检测仍然是一个巨大的挑战。
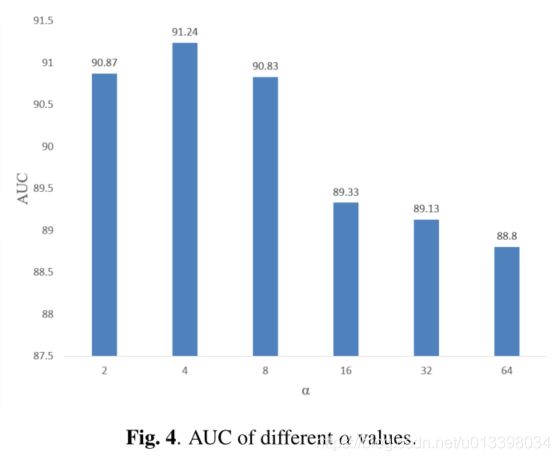
为了深入了解超参数α,我们使用具有不同α值的I3DConcfeature提取器进行了实验,如图4所示。实际上,α决定了训练阶段噪声标签实例的比例。尽管较高的α会导致较小的带噪标签实例比例,但在训练阶段将忽略一些异常实例。这导致训练异常实例的多样性不足,从而减少了AR-Net的帧级AUC。当α设置为8、16、32或64时,帧级AUC最多减少2.44%。
较低的α会导致在训练阶段将更多正常实例标记为异常实例。这也减少了AR-Net的帧级AUC。图4表明,当α小于4时,AR-Net的帧级AUC下降0.37%。
4. CONCLUSION
在本文中,我们提出了一种基于MIL的异常回归网络来进行视频异常检测。此外,我们设计了动态损耗LDMIL来学习可分离的特征,并设计了中心损耗Lc来校正AR-Net输出的异常分数。通过在弱监督下优化AR-Net的参数,动态多实例学习损失避免了由于剪辑特征之间的干扰而引起的误报。中心回归损失通过平滑异常分数的分布来抑制标签噪声。此外,基于片段的实例生成策略也有利于短期异常检测。在具有挑战性的数据集上进行的实验清楚地证明了我们的视频异常检测方法的有效性。将来,我们将研究对实例之间的时间关系建模以获得更多的鲁棒性。
这篇文章整体看下来个人觉得创新不太大,两个loss都在其他文章似曾相识,特别是center loss。但是发表了都是大佬!!!