【图像分割论文阅读】DeepLabV3+:Encoder-Decoder with Atrous Separable Convolution for SemanticImageSegmentation

本文出自谷歌Liang-Chieh Chen团队,收录于CVPR2018
论文地址Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
背景
空间金字塔池化SPP以及编解码器Encoder-decoder结构常被用于语义分割任务中。前者以不同比率、不同大小的感受野的卷积池化操作在多尺度上编码上下文信息。而后者通过Decoder逐步重建空间信息以捕捉更清晰的图像边界。
在作者之前的工作中,DeepLabV3中尽管最后的特征图尽管已经编码了许多语义信息,但是于图像边界相关的细节信息在池化带步长的卷积操作过程中丢失了。这一点可以用Atrous convolution提取密集特征来解决。但是由于计算GPU内存的限制,当下的SOTA模型最后的特征图大小很难保证在原始分辨率的1/8、1/4内。利用模型提取密集特征输出时计算量很大。
而编解码器结构在编码过程以及更深的解码器部分重建清晰的图像边界则计算迅速。
本文在DeepLabV3的基础上增加一个简单有效的Decoder结构优化分割结果,特别是图像边界。此外还利用Xception模块,并且将depthwise separable convolution用于ASPP以及解码器模块,使得整个网络成为更快更强的编解码器结构。最后的实验部分是在Pascal voc 2012、Cityscapes上完成,最后取得的结果非常好,分别为89.0%和81.2%.
本文的主要贡献在于:
- 将
DeepLabV3模型作为编码器,联合一个简单有效的解码器结构构造了一个全新的编解码器结构。 - 在这个结构中可以利用
atrous convolution操作控制编码器提取的特征分辨率的特性,取得精度与运行速度之间的权衡,而这一点时其他编解码器结构所没有的。 - 采用
Xception模块,并且将Depthwise separable convolution用于ASPP模块和解码器模块。
模型结构
DeepLabV3+与DeepLabV3的差异从下图a和c可知,之前的模型中利用DeepLabV3提取到的特征图直接上采样得到最终输出。本文结合编码器结构,得到c图中的新的编解码器结构。将DeepLabV3提取到的特征进一步处理并且将编码部分的特征也作进一步处理,得到新的编解码器结构。下图是一个稍显抽象的描述,具体的结构在下文会继续介绍。
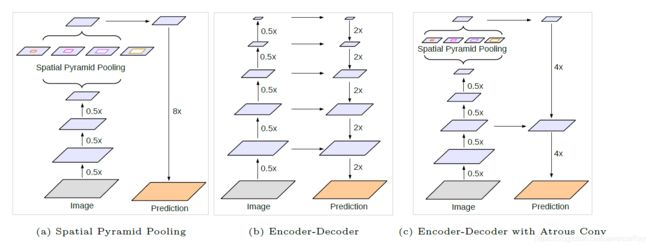
文中在这一部分分两部分介绍,第一部分介绍Encoder-Decoder with Atrous Convolution,介绍使用扩张卷积的编解码器结构。另一部分介绍Modified Aligned Xception,修正对齐的Xception,下面一一介绍。
Encoder-Decoder with Atrous Convolution
Atrous convolution
这一部分在DeepLab系列已经被玩坏了,就不过多介绍了。可以理解为,通过利用指数增加的dialtion系数进行卷积,在不增加模型参数的前提下,获得更大的感受野。可以认为一般的卷积过程是dilation=1的Atrou convolution.
Depthwise separable convolution
个人译做纵深分解卷积,可以将标准卷积操作分解为纵深卷积,也即在每一个输入通道上使用一个卷积核操作。通过这种方式在保持性能的前提下可以极大的减少计算复杂度(虽然我也不知道是怎么减少的,这个要去翻出处)。然后对于每个通道上的计算结果通过pointwise convolution整合。作者将使用了atrous convolution的纵深分解卷积称作atrous separable convolution,如下图所示:

DeepLabv3 as encoder
记output stride为输入图像的分辨率与输出的分辨率的比率。对分类任务,通常有output stride=32,对分割任务,通常有output stride=16(8).本文将DeepLabv3用作encoder提取特征,最后的输出特征包含256个包含丰富语义信息的通道,output stride=16。并且可以视计算预算使用astrous convolution使用任意的分辨率提取特征。
Proposed decoder
如果解码器部分是对DeepLabv3中输出的output stride=16的进行线性插值上采样,则称这是naive decoder模块。但是这种方式并不能恢复目标的分割细节。本文中提出新的decoder其构造是对DeepLabv3输出的特征图进行4倍上采样同时对底层特征(包含512/256个通道)进行1x1 convolution处理,调整通道数一致后融合这两部分特征.对融合后的特征进行filter=3*3卷积提炼特征。之后再做采样率为4的线性二值上采样。使用这种decoder可以在不增加计算复杂度的前提下获得output stride=8更为丰富的特征。文中提出的decoder构造如下:

Modified Aligned Xception
先看一下Xception模型构造:

为了快速计算和内存效率,没有改变Entry flow结构。所有的最大池化层被带步长的纵深分解网络取代,这使得可以利用Atrous separable convolution对提取任意大小的分辨率。在每个filter=3*3的depthwise convolution之后加入额外的batch normalization和ReLU模块。文中所使用的修正后的Xception模型为:

实验
实验所采用的数据集为Pascal voc 2012,包含20类前景对象以及一类背景标签。模型的评价指标为mIoU.
作者在这一部分介绍了decoder的设计过程。这里贴一张比较完整的图,方便描述作者的实验过程:

- 作者首先测试了底层特征的通道数应该如何设置,也就是上图中最左侧的
low-level feature的通道数。最后敲定为channels=48.

2).decoder中使用的filter=3*3该如何设计?作者的实验如下图所示。最后得出使用连续的两个filter=3*3的卷积效果最好。

ResNet-101 as Network BackBone
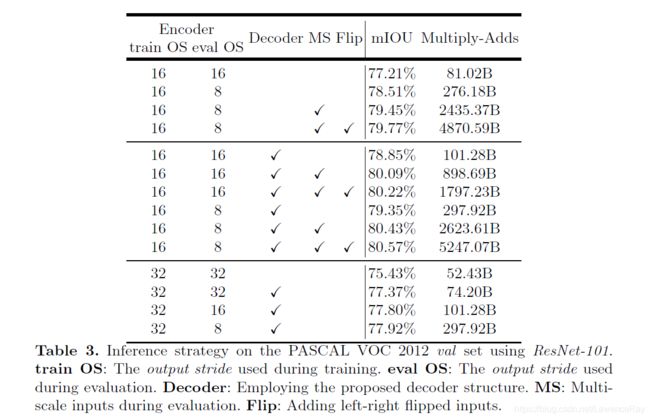
作者采用了ResNet-10作为基础模型时测试了使用DeepLabv3在训练测试过程中分别产生多大的特征图,以及是否使用decoder模块,是否利用多尺度提取特征,是否采用左右反转图片作为输入。实验如图:
Xception as Network Backbone
此外还是用Xception作为基础模型。

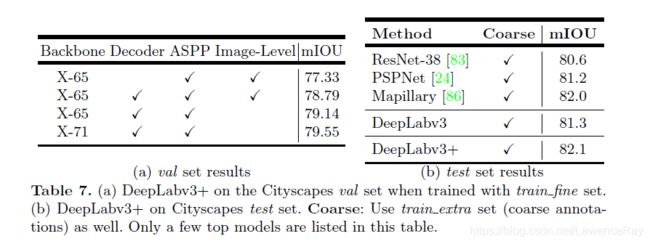
最后在Pascal voc 2012、Cityscapes两个数据集上实验,最后得到的效果如下;
Pascal voc 2012
其中JFT代表在次数据集上预训练。

Cityscapes
反思:这个Xception还是要看的,这里根本不懂是什么!!!