【论文精读】:Global Matching with Overlapping Attention for Optical Flow Estimation
作者:Shiyu Zhao,Long Zhao,Zhixing Zhang,Enyu Zhou,Dimitris Metaxas
来源:CVPR2022
摘要
1、想要解决什么问题?question
适用于大运动区域和无纹理区域的光流估计。
2、通过什么方法来解决这个问题?method
在直接回归前引入全局匹配;提出基于patch的重叠注意力机制(POLA);开发匹配优化框架GMFlowNet。
3、作者给出的结果是什么?answer
GMFlowNet的性能远远优于RAFT,达到了sota的效果。
引言
1、研究背景
光流估计是计算机视觉中一项关键的任务。
2、当前研究进展
基于能量优化法;基于匹配优化法;直接回归法。
3、存在的问题
基于神经网络直接回归的光流估计方法不能明确地捕获长期运动的相关性,不能有效处理大的运动。
4、灵感来源
基于能量优化的方法中,在优化前引入匹配可以提升性能。

相关工作
1、将光流问题描述为连续的全局能量函数优化问题
Black和Anandan[5]设计一种稳固的估计框架来处理由遮挡或显著亮度变化引起的离群值→[6,35,54]利用正则项或额外的优化项进行改进。(这些方法缺少长期依赖关系且只对小运动有效)→提出从粗到细的策略[6,9],在图像金字塔的不同层次上处理大小位移。(不能处理在粗层上消失的快速移动的小物体)→引入局部特征匹配[1,3,12,20,49],这些研究认为全局匹配耗时。
2、将光流作为回归网络
[42]为每对像素构建4D代价体;Separable Flow[55]为了高效的聚合提出分离的代价体模型。
3、注意力机制
LoFTR[41]采用自注意力和交叉注意力进行特征匹配;Swin Transformer[29]通过滑动窗口进行patch间的信息交互。
研究方法
GMFlowNet由3部分组成:大背景特征提取、全局匹配、基于学习的优化。

1、大背景特征提取
首先用三个卷积层提取出初始特征,再采用Transformer块来包含长期依赖信息。为了减少计算成本,提出局部注意力模块POLA。
-
注意力计算
用[45]的transformer计算方式,再加上[34]中提出的相对位置偏置B,得到注意力

-
POLA(Patch-based overlapping attention)

POLA将特征划分为M×M非重叠的patch,处理每个及其相邻8个的patch,根据[29,45]在注意力块中采用多头注意力。给定一个向量化的patch为P,其周围的3×3paches为S.在注意力中的第i个头,首先用线性投影将P和S投影到dk维数,投影后为Pi和Si;再用Pi和Si算注意力,得到输出hi;将hi聚合得到H,把H投射为d维,得到最终结果O

- Swin Transformer有一个固定窗口和一个滑动窗口,而滑动窗口需要2个单独的注意力块来进行patch间信息的交换,这会导致信息丢失,不利于匹配。POLA在一个块内包含patch间的特征,直接进行信息交换,信息损失较小。POLA的优势在于:消耗的内存更少;可以在现有的深度学习平台上高效实现;通过patch排列特征可以获得更好的性能。


2、全局匹配
-
4D代价体计算
根据[26,42],在输入分辨率的1/8上构建4D代价体。

-
匹配置信度计算
根据[37],用双softmax算子将代价体转换为匹配置信度。

-
匹配的选择和流的生成
根据匹配置信度,算出输入图像I1和I2的匹配;定义匹配集;计算粗流。
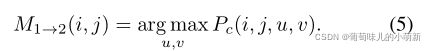
![]()
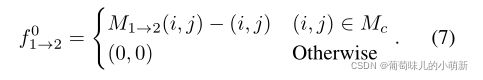
3、优化
利用RAFT的优化作为本研究的优化,RAFT优化的初始值是0,本研究为f01→2
4、监督
-
匹配损失

-
优化损失
与RAFT相同

-
总损失
![]()
实验
1、定量评估
-
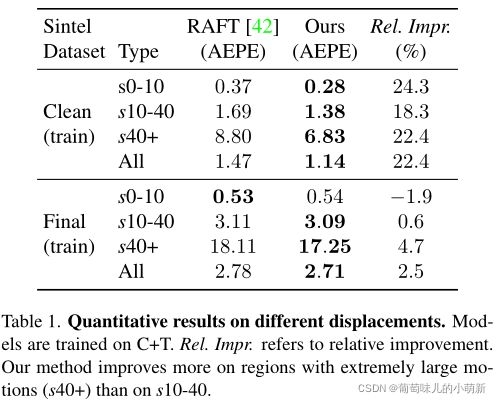
不同位移下的表现
将Sintel训练集划分为s10,s10-40,s40+子集,在C+T数据集上训练GMFlowNet,以RAFT为基准,在子集上评估,评价指标为AEPE。结果表明,GMFlowNet在位移极大的区域上有很大的改进,这说明具有大背景的全局匹配有利于处理较大的运动。
-
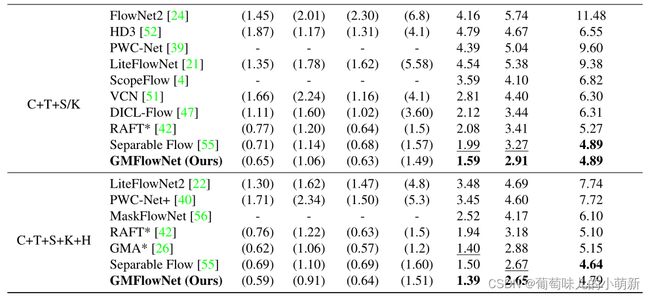
跨域评估[26,42,25]
在C+T数据集上训练,在S和K数据集上评估。结果表明GMFlowNet具有很好的泛化能力,将泛化能力的提高归功于全局匹配。
-
在标准基准上评估[26,42,25]
2、定性评估
-
可视化估计流
GMFlowNet对局部模糊区域,如无纹理区域提供了更好的预测

-
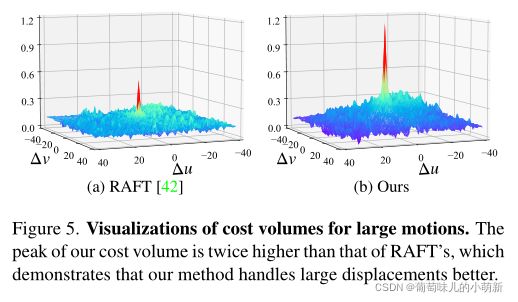
可视化代价体
GMFlowNet的代价体峰值远高于RAFT
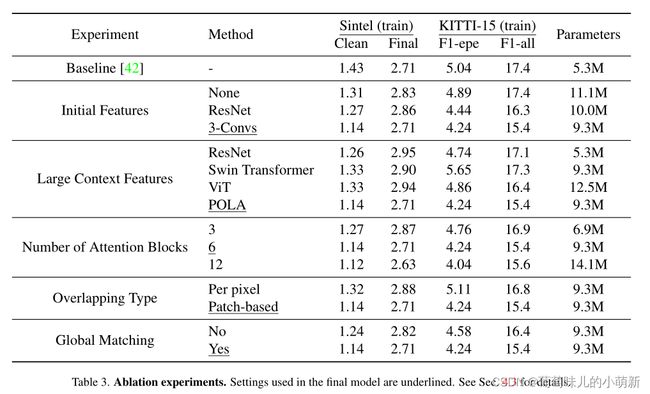
3、消融实验
在初始特征提取模块的选择;大背景特征提取模块选择;注意力块数量的选择;重叠类型的选择;是否使用全局匹配,分别进行实验,验证各个模块的有效性
4、效率
-
全局匹配运行时间
用RAFT和加入全局匹配的RAFT做对比试验,结果表明加入全局匹配后运行速度稍慢,但性能显著提高。
-
重叠注意力运行时间
与+Swin相比,GMFlowNet需要0.078秒的额外时间,考虑到性能的改进,这种开销是可以接受的。

本文的创新点:
- 在回归前引入全局匹配来处理大位移
- 特征提取中使用POLA注意力机制,减少匹配中的模糊区域,提高精度