贝尔曼方程计算Markov最优决策
贝尔曼方程计算Markov最优决策
一、实验目的
深刻理解制定复杂决策中的Markov决策过程,以及学会使用价值迭代的方式找到最优策略,加深对决策这个概念的理解。
二、实验内容
- 验证给定的可完全观测的 4 × 3 4\times3 4×3状态空间(折扣因子 γ = 1 \gamma=1 γ=1,回报函数 R ( s ) = − 0.04 R(s)=-0.04 R(s)=−0.04)真正效用值的价值迭代过程,并验证最优策略。
- 验证不同回报函数的最优策略
- 假定有一个 X × Y X\times Y X×Y的状态空间, ( x 1 , y 1 ) (x_1,y_1) (x1,y1)为墙, ( x 2 , y 2 ) (x_2,y_2) (x2,y2)为 + 1 +1 +1目标状态, ( x 3 , y 3 ) (x_3,y_3) (x3,y3)为 − 1 -1 −1目标状态,给出通用的价值迭代过程和最优策略计算。并对算法在不同条件下进行测试
三、实验设计
由于 4 × 3 4\times3 4×3 状态空间为 X × Y X\times Y X×Y 状态空间的一个特殊情况,故直接以 X × Y X\times Y X×Y的状态空间来说明实验设计。
实验要求进行 M a r k o v Markov Markov 决策过程的计算,并且求出最优策略。
结果分析,可以知道,实验分为以下几步:
(1)初始化:
初始化状态空间,确定墙的位置、+1目标状态及 -1目标状态的坐标。同时,确定非终止状态的回报函数 R ( s ) R(s) R(s)、折扣因子 γ \gamma γ、非终止状态的效用 v v v 的初始值以及沿预期方向运动的概率及沿预期方向左右方向运动的概率。
(2)利用贝尔曼方程,计算真正效用值:
假设 A g e n t Agent Agent 选择了最优行为,一个状态的效用值是在该状态下的立即回报,再加上在下一状态的期望折扣效用值:
V ( s ) = R ( s ) + γ m a x a ∑ s ′ P ( s ′ ∣ s , a ) V ( s ′ ) V(s) = R(s) + \gamma\underset{a}{max} \sum_{s'}P(s'|s,a)V(s') V(s)=R(s)+γamax∑s′P(s′∣s,a)V(s′)
也就是说,对于一个状态 s s s,求出通过进行向上、下、左、右四个方向前进的行动到下一个状态 s ′ s' s′的期望折扣效用值,就可以得到状态的效用值。
经过多次迭代,直到状态的效用值不再变化,即可求出真正的效用值。
在具体实现中,最大的难点在于判断何时会撞墙,这样才能正确确定从状态 s s s经过某一方向的运动到了哪一个状态 s ′ s' s′。
这里,我采取直接判断的方式。首先,我将整个空间每个状态的效用值用二维列表表示,表示为 X X X行 Y Y Y列形式。也就是说,如下图所示的状态空间的效用值,会表示为列表 v = [ [ 0 , 2 , 3 ] , [ 4 , ′ w a l l ′ , 5 ] , [ − 1 , 6 , 1 ] , [ 7 , 8 , 9 ] ] v=[[0,2,3],[4,'wall',5],[-1,6,1],[7,8,9]] v=[[0,2,3],[4,′wall′,5],[−1,6,1],[7,8,9]]。

我们知道, ( x 1 , y 1 ) (x_1,y_1) (x1,y1)为墙, ( x 2 , y 2 ) (x_2,y_2) (x2,y2)为 + 1 +1 +1 目标状态, ( x 3 , y 3 ) (x_3,y_3) (x3,y3)为 − 1 -1 −1 目标状态,并且在边界部分向出边界的方向运动也会撞墙。
记当前状态为 s_cur,当前状态的效用值为 v_cur,当前位置为 ( i , j ) (i,j) (i,j)。
定义向上运动后的状态为 s_up,当前状态的效用值为 v_up,其坐标为 ( i , j + 1 ) (i,j+1) (i,j+1);
向下运动后的状态为 s_down,当前状态的效用值为 v_down,其坐标为 ( i , j − 1 ) (i,j-1) (i,j−1);
向左运动后的状态为 s_left,当前状态的效用值为 v_left,其坐标为 ( i − 1 , j ) (i-1,j) (i−1,j);
向右运动后的状态为 s_right,当前状态的效用值为 v_right,其坐标为 ( i + 1 , j ) (i+1,j) (i+1,j)。
而对特殊情况需要对运动后的状态进行修正:
- 当 ( i , j ) = ( x 1 , y 1 ) (i,j)=(x_1,y_1) (i,j)=(x1,y1) 或 ( x 2 , y 2 ) (x_2,y_2) (x2,y2) 或 ( x 3 , y 3 ) (x_3,y_3) (x3,y3) 时,不进行运动;
- 当 ( i , j ) = ( x 1 − 1 , y 1 ) (i,j)=(x_1-1,y_1) (i,j)=(x1−1,y1)(即墙左边)时,若执行向右操作,得到的状态仍为当前状态;
- 当 ( i , j ) = ( x 1 + 1 , y 1 ) (i,j)=(x_1+1,y_1) (i,j)=(x1+1,y1)(即墙右边)时,若执行向右操作,得到的状态仍为当前状态;
- 当 ( i , j ) = ( x 1 , y 1 + 1 ) (i,j)=(x_1,y_1+1) (i,j)=(x1,y1+1)(即墙上边)时,若执行向下操作,得到的状态仍为当前状态;
- 当 ( i , j ) = ( x 1 , y 1 − 1 ) (i,j)=(x_1,y_1-1) (i,j)=(x1,y1−1)(即墙下边)时,若执行向上操作,得到的状态仍为当前状态。
由此即可求出各个位置所对应的向各个方向运动后的状态的效用值,参照贝尔曼方程,即可求解。
经过不断迭代,直到各个状态效用值不再变化即得到最终效用值。
(3)求解最优策略 π ∗ ( s ) \pi ^*(s) π∗(s)
求解最优策略的过程就是依据得到的真正效用值求解下式:
π ∗ ( s ) = a r g m a x a ∈ A ( s ) ) ∑ s ′ P ( s ′ ∣ ∣ s , a ) V ( s ′ ) \pi ^*(s) = arg \underset{a\in A(s))}{max} \sum_{s'}P(s'||s,a)V(s') π∗(s)=arga∈A(s))max∑s′P(s′∣∣s,a)V(s′)
这里求解的方法与(2)中十分类似。
我通过记向上运动得到的 v v v为 v 1 v_1 v1,向下运动得到的 v v v为 v 2 v_2 v2,向左运动得到的 v v v为 v 3 v_3 v3,向右运动得到的 v v v为 v 4 v_4 v4,判断 v m a x v_{max} vmax与哪个 v i ( i = 1 , 2 , 3 , 4 ) v_i(i=1,2,3,4) vi(i=1,2,3,4)相等,即可对应相应的方向,最后就可以得到每个状态所对应的策略,也就是最优策略。
四、实验结果
输出的实验结果以 X X X行 Y Y Y列的列表展示。
-
将实验结果与课件上内容进行对比(经查阅课本发现,课件上部分数据有误),故与课本数据进行比对,答案基本正确。
(注:部分位置值出现误差是由于小数点精度确定的不同,部分位置的千分位存在误差,即误差在 ± 0.001 \pm 0.001 ±0.001 之间)


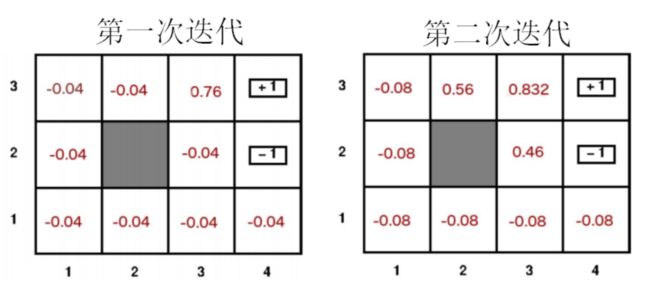
结果如上图,可以看到,经过19次价值迭代,才求出真正效用值。并且最终的最优策略也可以求出为[[‘up’, ‘up’, ‘right’], [‘left’, ‘wall’, ‘right’], [‘left’, ‘up’, ‘right’], [‘left’, -1, 1]],与课本中的内容相符。同时,将第1次和第2次迭代的结果于课本中相比较,也是相符的,故验证成功。 -
根据回报函数 R ( s ) R(s) R(s) 的取值不同,最终的最优策略不同,结果如下:


可以看到,
- 当 R < − 1.6284 R<-1.6284 R<−1.6284 时,取 R = − 2 R=-2 R=−2,得到的策略符合;
- 当 − 0.4278 < R < − 0.0850 -0.4278
- 当 − 0.0221 < R < 0 -0.0221
- 当 R > 0 R>0 R>0时,取 R = 0.5 R=0.5 R=0.5,得到的策略符合。
(注:这里的回报函数 R R R值可以在代码中进行更换试验)
- 针对不同的 X X X与 Y Y Y值,可以得到通用的求解方法。
这里以回报函数 R ( s ) = − 0.04 R(s)=-0.04 R(s)=−0.04,折扣因子 γ = 1 \gamma=1 γ=1为例:
可输入 X , Y X,Y X,Y 及墙、+1目标状态,-1目标状态的坐标值。
( 注:坐标起始位置为(0,0))
(1)状态空间: 4 × 3 4 \times 3 4×3,墙坐标(1,1),+1的坐标(3,2),-1的坐标(3,1)结果如图(此条件与实验1中相同,可验证结果与1.中相符):

(2)状态空间: 6 × 4 6 \times 4 6×4,墙坐标(3,2),+1坐标(4,1),-1坐标(3,1)结果如图

(因结果过长,不方便截图,故下面显示直接的结果)
真正效用值:
[ [ 0.529 , 0.575 , 0.62 , 0.664 ] , [ 0.563 , 0.612 , 0.67 , 0.72 ] , [ 0.605 , 0.582 , 0.72 , 0.776 ] , [[0.529, 0.575, 0.62, 0.664], [0.563, 0.612, 0.67, 0.72],[0.605, 0.582, 0.72,0.776], [[0.529,0.575,0.62,0.664],[0.563,0.612,0.67,0.72],[0.605,0.582,0.72,0.776], [ 0.658 , − 1 , ′ w a l l ′ , 0.833 ] , [ 0.915 , 1 , 0.944 , 0.883 ] , [ 0.892 , 0.939 , 0.895 , 0.849 ] ] [0.658, -1, 'wall', 0.833],[0.915, 1, 0.944, 0.883],[0.892, 0.939, 0.895, 0.849]] [0.658,−1,′wall′,0.833],[0.915,1,0.944,0.883],[0.892,0.939,0.895,0.849]]
最优策略:
[ [ ′ u p ′ , ′ u p ′ , ′ u p ′ , ′ r i g h t ′ ] , [ ′ u p ′ , ′ u p ′ , ′ u p ′ , ′ r i g h t ′ ] , [ ′ r i g h t ′ , ′ l e f t ′ , ′ u p ′ , ′ r i g h t ′ ] , [['up', 'up', 'up', 'right'], ['up', 'up', 'up', 'right'], ['right', 'left', 'up', 'right'], [[′up′,′up′,′up′,′right′],[′up′,′up′,′up′,′right′],[′right′,′left′,′up′,′right′], [ ′ r i g h t ′ , − 1 , ′ w a l l ′ , ′ r i g h t ′ ] , [ ′ u p ′ , 1 , ′ d o w n ′ , ′ d o w n ′ ] , [ ′ u p ′ , ′ l e f t ′ , ′ d o w n ′ , ′ d o w n ′ ] ] ['right', -1, 'wall', 'right'], ['up', 1, 'down', 'down'], ['up', 'left', 'down', 'down']] [′right′,−1,′wall′,′right′],[′up′,1,′down′,′down′],[′up′,′left′,′down′,′down′]]
(3)状态空间: 5 × 4 5 \times 4 5×4,墙坐标(2,3),+1坐标(0,2),-1坐标(3,0)结果如图

(因结果过长,不方便截图,故下面显示直接的结果)
真正效用值:
[ [ 0.888 , 0.944 , 1 , 0.944 ] , [ 0.844 , 0.893 , 0.939 , 0.899 ] , [ 0.799 , 0.843 , 0.884 , ′ w a l l ′ ] , [[0.888, 0.944, 1, 0.944], [0.844, 0.893, 0.939, 0.899], [0.799, 0.843, 0.884, 'wall'], [[0.888,0.944,1,0.944],[0.844,0.893,0.939,0.899],[0.799,0.843,0.884,′wall′], [ − 1 , 0.773 , 0.821 , 0.765 ] , [ 0.482 , 0.717 , 0.76 , 0.72 ] ] [-1, 0.773, 0.821, 0.765], [0.482, 0.717, 0.76, 0.72]] [−1,0.773,0.821,0.765],[0.482,0.717,0.76,0.72]]
最优策略:
[ [ ′ u p ′ , ′ u p ′ , 1 , ′ d o w n ′ ] , [ ′ l e f t ′ , ′ l e f t ′ , ′ l e f t ′ , ′ l e f t ′ ] , [ ′ l e f t ′ , ′ l e f t ′ , ′ l e f t ′ , ′ w a l l ′ ] , [['up', 'up', 1, 'down'], ['left', 'left', 'left', 'left'], ['left', 'left', 'left', 'wall'], [[′up′,′up′,1,′down′],[′left′,′left′,′left′,′left′],[′left′,′left′,′left′,′wall′], [ − 1 , ′ u p ′ , ′ l e f t ′ , ′ d o w n ′ ] , [ ′ u p ′ , ′ u p ′ , ′ l e f t ′ , ′ l e f t ′ ] ] [-1, 'up', 'left', 'down'], ['up', 'up', 'left', 'left']] [−1,′up′,′left′,′down′],[′up′,′up′,′left′,′left′]]
(4)状态空间: 3 × 3 3 \times 3 3×3,墙坐标(2,1),+1坐标(0,0),-1坐标(2,2)结果如图

其他不同条件试验均可得到正确的结果。
五、总结
本次实验让我对复杂决策有了更加深刻的理解,在解决问题的过程中对复杂决策的过程进行了清楚的梳理,并且罗列了各种特殊情况,提升了自己解决问题的能力。此外,解决问题后很有成就感!
六、源代码
(1)
import copy
R = -0.04 # 非终止状态回报
gamma = 1
v = [[0, 0, 0], [0, 'wall', 0], [0, 0, 0], [0, -1, 1]] # 初始化效用值
p = [0.8, 0.1, 0.1] # 按计划方向及其左右方向行动的概率
policy = copy.deepcopy(v)
# 首先计算真正效用值
num = 1
while True:
temp_v = copy.deepcopy(v)
for i in range(4):
for j in range(3):
if (i == 1 and j == 1) or (i == 3 and j == 1) or (i == 3 and j == 2):
continue
v_cur = v[i][j]
if i == 0:
v_left = v_cur
else:
v_left = v[i - 1][j]
if i == 3:
v_right = v_cur
else:
v_right = v[i + 1][j]
if j == 0:
v_down = v_cur
else:
v_down = v[i][j - 1]
if j == 2:
v_up = v_cur
else:
v_up = v[i][j + 1]
# 撞墙
if i == 1 and j == 0:
v_up = v_cur
if i == 0 and j == 1:
v_right = v_cur
if i == 1 and j == 2:
v_down = v_cur
if i == 2 and j == 1:
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
comp = [v1, v2, v3, v4]
temp_v[i][j] = round(R + gamma * max(comp), 3)
if v == temp_v:
break
v = copy.deepcopy(temp_v)
print('第{}次迭代:'.format(num), end='')
print(v)
num = num + 1
# 计算最优策略
for m in range(4):
for n in range(3):
if (m == 1 and n == 1) or (m == 3 and n == 1) or (m == 3 and n == 2):
continue
v_cur = v[m][n]
if m == 0:
v_left = v_cur
else:
v_left = v[m - 1][n]
if m == 3:
v_right = v_cur
else:
v_right = v[m + 1][n]
if n == 0:
v_down = v_cur
else:
v_down = v[m][n - 1]
if n == 2:
v_up = v_cur
else:
v_up = v[m][n + 1]
# 撞墙
if m == 1 and n == 0:
v_up = v_cur
if m == 0 and n == 1:
v_right = v_cur
if m == 1 and n == 2:
v_down = v_cur
if m == 2 and n == 1:
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
max_compare = [v1, v2, v3, v4]
max_v = max(max_compare)
if max_v == v1:
policy[m][n] = 'up'
elif max_v == v2:
policy[m][n] = 'left'
elif max_v == v3:
policy[m][n] = 'down'
else:
policy[m][n] = 'right'
print("最优策略:",end='')
print(policy)
(2)
import copy
gamma = 1
def solve(R):
if(R<=0):
v = [[0, 0, 0], [0, 'wall', 0], [0, 0, 0], [0, -1, 1]] # 初始化效用值
p = [0.8, 0.1, 0.1] # 按计划方向及其左右方向行动的概率
policy = [[0, 0, 0], [0, 'wall', 0], [0, 0, 0], [0, -1, 1]] # 初始化策略
# 首先计算真正效用值
while True:
temp_v = copy.deepcopy(v)
for i in range(4):
for j in range(3):
if (i == 1 and j == 1) or (i == 3 and j == 1) or (i == 3 and j == 2):
continue
v_cur = v[i][j]
if i == 0:
v_left = v_cur
else:
v_left = v[i - 1][j]
if i == 3:
v_right = v_cur
else:
v_right = v[i + 1][j]
if j == 0:
v_down = v_cur
else:
v_down = v[i][j - 1]
if j == 2:
v_up = v_cur
else:
v_up = v[i][j + 1]
# 撞墙
if i == 1 and j == 0:
v_up = v_cur
if i == 0 and j == 1:
v_right = v_cur
if i == 1 and j == 2:
v_down = v_cur
if i == 2 and j == 1:
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
comp = [v1, v2, v3, v4]
temp_v[i][j] = round(R + gamma * max(comp), 3)
if v == temp_v:
break
v = copy.deepcopy(temp_v)
# 计算最优策略
for m in range(4):
for n in range(3):
if (m == 1 and n == 1) or (m == 3 and n == 1) or (m == 3 and n == 2):
continue
v_cur = v[m][n]
if m == 0:
v_left = v_cur
else:
v_left = v[m - 1][n]
if m == 3:
v_right = v_cur
else:
v_right = v[m + 1][n]
if n == 0:
v_down = v_cur
else:
v_down = v[m][n - 1]
if n == 2:
v_up = v_cur
else:
v_up = v[m][n + 1]
# 撞墙
if m == 1 and n == 0:
v_up = v_cur
if m == 0 and n == 1:
v_right = v_cur
if m == 1 and n == 2:
v_down = v_cur
if m == 2 and n == 1:
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
max_compare = [v1, v2, v3, v4]
max_v = max(max_compare)
if max_v == v1:
policy[m][n] = 'up'
elif max_v == v2:
policy[m][n] = 'left'
elif max_v == v3:
policy[m][n] = 'down'
else:
policy[m][n] = 'right'
else:
policy = [['all','all','all'],['all','wall','all'],['all','left','left'],['down',-1,1]]
print(policy)
print("当R=-2时的最优策略:",end='')
solve(-2)
print("当R=-0.2时的最优策略:",end='')
solve(-0.2)
print("当R=-0.01时的最优策略:",end='')
solve(-0.01)
print("当R=0.5时的最优策略:",end='')
solve(0.5)
(3)
import copy
R = -0.04 # 非终止状态回报
gramma = 1
x = int(input("请输入X:"))
y = int(input("请输入Y:"))
x1 = int(input("请输入wall的x坐标:"))
y1 = int(input("请输入wall的y坐标:"))
x2 = int(input("请输入+1目标状态的x坐标:"))
y2 = int(input("请输入+1目标状态的y坐标:"))
x3 = int(input("请输入-1目标状态的x坐标:"))
y3 = int(input("请输入-1目标状态的y坐标:"))
v = [[0 for i in range(y)] for j in range(x)] # 初始化效用值
v[x1][y1] = 'wall'
v[x2][y2] = 1
v[x3][y3] = -1
p = [0.8, 0.1, 0.1] # 按计划方向及其左右方向行动的概率
policy = copy.deepcopy(v)
# 首先计算真正效用值
while True:
temp_v = copy.deepcopy(v)
for i in range(x):
for j in range(y):
if (i == x1 and j == y1) or (i == x2 and j == y2) or (i == x3 and j == y3):
continue
v_cur = v[i][j]
if i == 0:
v_left = v_cur
else:
v_left = v[i - 1][j]
if i == x-1:
v_right = v_cur
else:
v_right = v[i + 1][j]
if j == 0:
v_down = v_cur
else:
v_down = v[i][j - 1]
if j == y-1:
v_up = v_cur
else:
v_up = v[i][j + 1]
# 撞墙
if i == x1 and j == y1-1: # 墙下方
v_up = v_cur
if i == x1-1 and j == y1: # 墙左方
v_right = v_cur
if i == x1 and j == y1+1: # 墙上方
v_down = v_cur
if i == x1+1 and j == y1: # 墙右方
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
comp = [v1, v2, v3, v4]
temp_v[i][j] = round(R + gramma * max(comp), 3)
if v == temp_v:
break
v = copy.deepcopy(temp_v)
print('真正效用值:',end='')
print(v)
# 计算最优策略
for m in range(x):
for n in range(y):
if (m == x1 and n == y1) or (m == x2 and n == y2) or (m == x3 and n == y3):
continue
v_cur = v[m][n]
if m == 0:
v_left = v_cur
else:
v_left = v[m - 1][n]
if m == x-1:
v_right = v_cur
else:
v_right = v[m + 1][n]
if n == 0:
v_down = v_cur
else:
v_down = v[m][n - 1]
if n == y-1:
v_up = v_cur
else:
v_up = v[m][n + 1]
# 撞墙4
if m == x1 and n== y1-1: # 墙下方
v_up = v_cur
if m == x1-1 and n == y1: # 墙左方
v_right = v_cur
if m == x1 and n == y1+1: # 墙上方
v_down = v_cur
if m == x1+1 and n == y1: # 墙右方
v_left = v_cur
v1 = p[0] * v_up + p[1] * v_left + p[2] * v_right # up
v2 = p[0] * v_left + p[1] * v_down + p[2] * v_up # left
v3 = p[0] * v_down + p[1] * v_right + p[2] * v_left # down
v4 = p[0] * v_right + p[1] * v_up + p[2] * v_down # right
max_compare = [v1, v2, v3, v4]
max_v = max(max_compare)
if max_v == v1:
policy[m][n] = 'up'
elif max_v == v2:
policy[m][n] = 'left'
elif max_v == v3:
policy[m][n] = 'down'
else:
policy[m][n] = 'right'
print('最优策略:',end='')
print(policy)