【目标检测】YOLOv4特征提取网络——CSPDarkNet结构解析及PyTorch实现
【目标检测】YOLOv4特征提取网络——CSPDarkNet结构解析及PyTorch实现
- 1 YOLOv4目标检测模型
-
- 1.1 Mish激活函数
- 1.2 CSP结构和DarkNet
- 1.3 CSP-DarkNet
-
- 【讨论】
- 2 PyTorch实现CSPDarkNet
-
- 2.1 Mish激活函数和BN_CONV_Mish结构
- 2.2 Basic block
- 2.3 CSP-DarkNet
- 2.4 测试网络结构
1 YOLOv4目标检测模型
自从Redmon说他不在更新YOLO系列之后,我一度以为这么好用的框架就要慢慢淡入历史了,事实是我多虑了。YOLOv4在使用YOLO Loss的基础上,使用了新的backbone,并且集成了很多新的优化方法及模型策略,如Mosaic,PANet,CmBN,SAT训练,CIoU loss,Mish激活函数,label smoothing等等。可谓集SoAT之大成,也实现了很好的检测精度和速度。 这篇博客主要讨论YOLOv4中的backbone——CSP-DarkNet,以及其实现的所必需的Mish激活函数,CSP结构和DarkNet。
开源项目YOLOv5相比YOLOv4有了比较夸张的突破,成为了全方位吊打EfficientDet的存在,其特征提取网络也是CSP-DarkNet。
1.1 Mish激活函数
激活函数是为了提高网络的学习能力,提升梯度的传递效率。CNN常用的激活函数也在不断地发展,早期网络常用的有ReLU,LeakyReLU,softplus等,后来又有了Swish,Mish等。Mish激活函数的计算复杂度比ReLU要高不少,如果你的计算资源不是很够,可以考虑使用LeakyReLU代替Mish。在介绍之前,需要先了解softplus和tanh函数。
softplus激活函数的公式如下:
ζ ( x ) = l o g ( 1 + e x ) \zeta(x)=log(1+e^x) ζ(x)=log(1+ex)
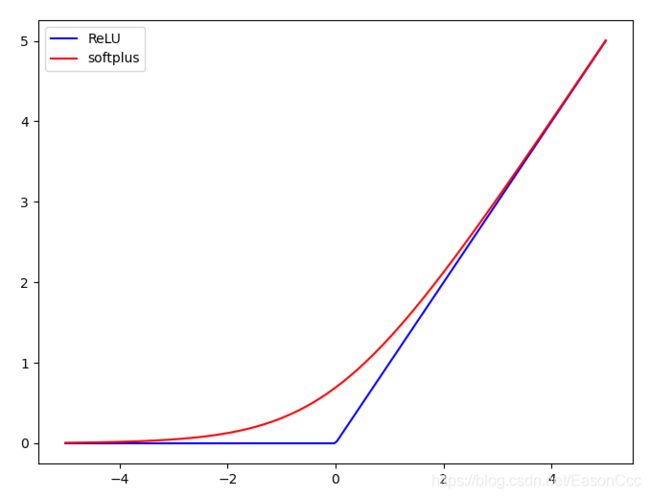
上图是其输出曲线,softplus和ReLU的曲线具有相似性,但是其比ReLU更为平滑。
目前的普遍看法是,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
tanh的公式如下:
t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} tanh(x)=ex+e−xex−e−x
Mish激活函数的公式为:
M i s h ( x ) = x × t a n h ( ζ ( x ) ) Mish(x) = x\times{tanh(\zeta(x))} Mish(x)=x×tanh(ζ(x))

上图为Mish的曲线。首先其和ReLU一样,都是无正向边界的,可以避免梯度饱和;其次Mish函数是处处光滑的,并且在绝对值较小的负值区域允许一些负值。
1.2 CSP结构和DarkNet
CSP和DarkNet的结构我在之前的博客中有介绍,如果不清楚的同学,欢迎戳链接:CSPNet,DarkNet。
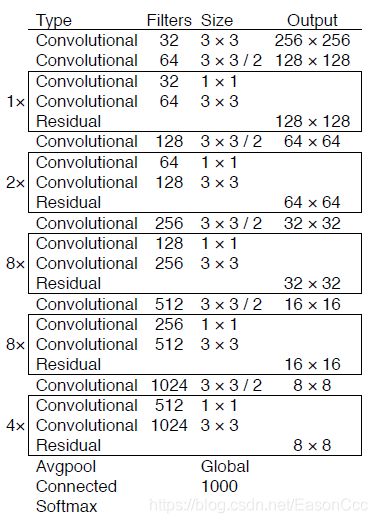
这里为了方便对比,给出DarkNet-53的架构图:
1.3 CSP-DarkNet
博客【darknet】darknet——CSPDarknet53网络结构图(YOLO V4使用)画出了DarkNet-53的结构图,画得很简明清晰,我借过来用一下:

CSP-DarkNet和CSP-ResNe(X)t的整体思路是差不多的,沿用网络的滤波器尺寸和整体结构,在每组Residual block加上一个Cross Stage Partial结构。并且,CSP-DarkNet中也取消了Bottleneck的结构,减少了参数使其更容易训练。
但是,有个地方看图还是不清楚——CSP输入的时候通道是什么比例划分的? 查看了一些源码,最终确认了结构,在一下部分进行讨论。
【讨论】
按照CSP论文中的思路,我开始认为的CSP结构应该是这样的——特征输入之后,通过一个比例将其分为两个部分(CSPNet中是二等份),然后再分别输入block结构,以及后面的Partial transition处理。这样符合CSPNet论文中的理论思路。

但是实际上,我参考了一些源码以及darknet配置文件中的网络参数,得到的结构是这样的:

和我所理解不同的是,实际的结构在输入后没有按照通道划分成两个部分,而是直接用两路的1x1卷积将输入特征进行变换。 可以理解的是,将全部的输入特征利用两路1x1进行transition,比直接划分通道能够进一步提高特征的重用性,并且在输入到resiudal block之前也确实通道减半,减少了计算量。虽然不知道这是否吻合CSP最初始的思想,但是其效果肯定是比我设想的那种情况更好的。性能是王道,我们也按照实际的结构来复现。
2 PyTorch实现CSPDarkNet
这个复现包括了全局池化和全连接层,YOLOv4中使用CSP-DarkNet只使用之前的卷积层用作特征提取。
2.1 Mish激活函数和BN_CONV_Mish结构
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(F.softplus(x))
class BN_Conv_Mish(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bias=False):
super(BN_Conv_Mish, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation=dilation,
groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.bn(self.conv(x))
return Mish()(out)
2.2 Basic block
使用的是残差结构,要注意的是:按照residual block的一贯思路,shortcut之前的最后一层卷积使用线性激活(不适使用激活函数)。
class ResidualBlock(nn.Module):
"""
basic residual block for CSP-Darknet
"""
def __init__(self, chnls, inner_chnnls=None):
super(ResidualBlock, self).__init__()
if inner_chnnls is None:
inner_chnnls = chnls
self.conv1 = BN_Conv_Mish(chnls, inner_chnnls, 1, 1, 0) # always use samepadding
self.conv2 = nn.Conv2d(inner_chnnls, chnls, 3, 1, 1, bias=False)
self.bn = nn.BatchNorm2d(chnls)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.bn(out) + x
return Mish()(out)
2.3 CSP-DarkNet
按照上图的结构实现CSP结构并搭建网络。需要注意的是,第一个CSP结构和后面的有略微差别:
class CSPFirst(nn.Module):
"""
First CSP Stage
"""
def __init__(self, in_chnnls, out_chnls):
super(CSPFirst, self).__init__()
self.dsample = BN_Conv_Mish(in_chnnls, out_chnls, 3, 2, 1) # same padding
self.trans_0 = BN_Conv_Mish(out_chnls, out_chnls, 1, 1, 0)
self.trans_1 = BN_Conv_Mish(out_chnls, out_chnls, 1, 1, 0)
self.block = ResidualBlock(out_chnls, out_chnls//2)
self.trans_cat = BN_Conv_Mish(2*out_chnls, out_chnls, 1, 1, 0)
def forward(self, x):
x = self.dsample(x)
out_0 = self.trans_0(x)
out_1 = self.trans_1(x)
out_1 = self.block(out_1)
out = torch.cat((out_0, out_1), 1)
out = self.trans_cat(out)
return out
class CSPStem(nn.Module):
"""
CSP structures including downsampling
"""
def __init__(self, in_chnls, out_chnls, num_block):
super(CSPStem, self).__init__()
self.dsample = BN_Conv_Mish(in_chnls, out_chnls, 3, 2, 1)
self.trans_0 = BN_Conv_Mish(out_chnls, out_chnls//2, 1, 1, 0)
self.trans_1 = BN_Conv_Mish(out_chnls, out_chnls//2, 1, 1, 0)
self.blocks = nn.Sequential(*[ResidualBlock(out_chnls//2) for _ in range(num_block)])
self.trans_cat = BN_Conv_Mish(out_chnls, out_chnls, 1, 1, 0)
def forward(self, x):
x = self.dsample(x)
out_0 = self.trans_0(x)
out_1 = self.trans_1(x)
out_1 = self.blocks(out_1)
out = torch.cat((out_0, out_1), 1)
out = self.trans_cat(out)
return out
class CSP_DarkNet(nn.Module):
"""
CSP-DarkNet
"""
def __init__(self, num_blocks: object, num_classes=1000) -> object:
super(CSP_DarkNet, self).__init__()
chnls = [64, 128, 256, 512, 1024]
self.conv0 = BN_Conv_Mish(3, 32, 3, 1, 1) # same padding
self.neck = CSPFirst(32, chnls[0])
self.body = nn.Sequential(
*[CSPStem(chnls[i], chnls[i+1], num_blocks[i]) for i in range(4)])
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(chnls[4], num_classes)
def forward(self, x):
out = self.conv0(x)
out = self.neck(out)
out = self.body(out)
out = self.global_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return F.softmax(out)
def csp_darknet_53(num_classes=1000):
return CSP_DarkNet([2, 8, 8, 4], num_classes)
2.4 测试网络结构
net = csp_darknet_53()
summary(net, (3, 256, 256))
