目标检测pytorch版yolov3四——通过提取出来的特征获得预测结果
本篇博客是我学习某位up在b站讲的pytorch版的yolov3后写的,
那位up主的b站的传送门:
https://www.bilibili.com/video/BV1A7411976Z
他的博客的传送门:
https://blog.csdn.net/weixin_44791964/article/details/105310627
他的源码的传送门:
https://github.com/bubbliiiing/yolo3-pytorch
侵删
已经很久没有写博客了,想着以前写的yolov3博客还没有写完,现在有时间把他补充完整,这个博客补充完整后,我会再开一篇我用yolov3做项目的博客。话不多说,开肝。
首先还是把整体框架的图片放在这里。
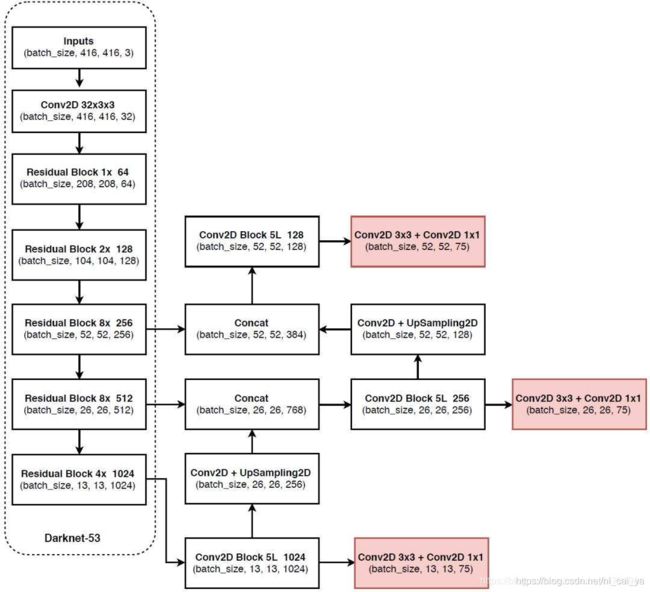
经过上一篇的学习,我们已经大概理解完左边虚线框内特征提取的代码的实现。现在开始理解提取到特征之后构建特征金字塔,然后进行分类和回归预测的代码。
下面的代码是位于net文件夹下的yolo3.py文件内。
import torch
import torch.nn as nn
from collections import OrderedDict
from nets.darknet import darknet53
def conv2d(filter_in, filter_out, kernel_size):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=1, padding=pad, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.LeakyReLU(0.1)),
]))
def make_last_layers(filters_list, in_filters, out_filter):
m = nn.ModuleList([
"""
首先是前面5个卷积是对应的Conv2D Block 5L部分
首先利用1x1的卷积调整通道数,
然后利用3x3的卷积进行特征提取,
然后再次利用1x1的卷积调整通道数,
再利用3x3的卷积进行特征提取,
这样有利于减少网络的参数量,并且有利于提取出网络的特征。
最后进行一次1x1的卷积把通道数调整为512,filters_list[0]的值是512
"""
conv2d(in_filters, filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
conv2d(filters_list[0], filters_list[1], 3),
conv2d(filters_list[1], filters_list[0], 1),
"""
最后两次卷积是对应的Conv2D 3x3 + Conv2D 1x1部分,
这里的两次卷积其实就是进行分类和回归预测的,下面有一个out_filter,这个所对应的值就是我们下面所定义的75,
"""
conv2d(filters_list[0], filters_list[1], 3),
nn.Conv2d(filters_list[1], out_filter, kernel_size=1,
stride=1, padding=0, bias=True)
])
return m
class YoloBody(nn.Module):
def __init__(self, config):
super(YoloBody, self).__init__()
self.config = config
# backbone
#首先我们利用darknet53(None)来获取道我们darknet.py所定义的darknet的结构。
self.backbone = darknet53(None)
out_filters = self.backbone.layers_out_filters
# last_layer0
"""
len(config["yolo"]["anchors"][0])这个的值是3,对应着我们默认的每个网格点有三个先验框,
5 + config["yolo"]["classes"]其实就是5+num_classes,其实也就是表示:
我们的先验框内部是否真实的包含物体,这个物体的种类,以及这个先验框的调整参数。
我们把5 + config["yolo"]["classes"]拆开来看(以voc数据集为例):
5 + config["yolo"]["classes"]=5+num_classes=5+20=4+1+20,
20这里表示会把我们先验框内部的物体分20个类,
4表示先验框的调整参数,每个先验框有四个调整参数,
1表示这个先验框内部是否真是的包含物体
则final_out_filter0=len(config["yolo"]["anchors"][0]) * (5 + config["yolo"]["classes"])=3*(4+1+20)=75
"""
"""
同理可得,final_out_filter1以及final_out_filter2的值也是75,
这个75所对应的值,也就是整体框架图的红色部分里面所包含的75
"""
final_out_filter0 = len(config["yolo"]["anchors"][0]) * (5 + config["yolo"]["classes"])
"""
这里的make_last_layers就是进行了7此卷积,分别是整体框架图中所对应的:
Conv2D Block 5L 1024部分的五次卷积和Conv2D Block 5L 1024部分右边的Conv2D 3x3 + Conv2D 1x1部分的两次卷积
"""
self.last_layer0 = make_last_layers([512, 1024], out_filters[-1], final_out_filter0)
# embedding1
"""
下面就是我们定义的卷积和上采样,也就是Conv2D Block 5L 1024顺着箭头向上指的Conv2D + UpSampling2D
"""
final_out_filter1 = len(config["yolo"]["anchors"][1]) * (5 + config["yolo"]["classes"])
#首先利用1x1的卷积来调整通道数
self.last_layer1_conv = conv2d(512, 256, 1)
"""
然后利用上采样,把高和宽调整为26x26,这个过程结束以后我们就获得了26x26x256的特征层了
这里的26x26的高和宽和我们整体框架图的虚线框内(Darknet-53)的倒数第二个部分(Residual Block 8x 512)的高和宽是一样的。
我们就将这两个部分进行一个堆叠,也就是在整体框架图的虚线框内(Darknet-53)的倒数第二个部分(Residual Block 8x 512)向右指向的Concat。
堆叠的代码是在前向传播中实现的。
"""
self.last_layer1_upsample = nn.Upsample(scale_factor=2, mode='nearest')
"""
上面堆叠完成后,我们又要进行7次卷积了,分别是:
Conv2D Block 5L 256部分的五次卷积和Conv2D Block 5L 256部分右边的Conv2D 3x3 + Conv2D 1x1部分的两次卷积
还是通过make_last_layers实现
"""
self.last_layer1 = make_last_layers([256, 512], out_filters[-2] + 256, final_out_filter1)
# embedding2
"""
下面的操作就是卷积上采样,然后进行特征金字塔的堆叠,然后卷积,预测,和上面的过程是类似的,就不再赘述
"""
final_out_filter2 = len(config["yolo"]["anchors"][2]) * (5 + config["yolo"]["classes"])
self.last_layer2_conv = conv2d(256, 128, 1)
self.last_layer2_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.last_layer2 = make_last_layers([128, 256], out_filters[-3] + 128, final_out_filter2)
#这里的前向传播的过程就是将我们上面定义的各个小块(也就是整体框架图中除了虚线框以外的剩余的各个小块)
def forward(self, x):
"""
这里的branch函数主要是将make_last_layers函数里面定义的卷积操作分开,因为我们的前5次卷积和后两次卷积的使用方向是不同的。
"""
def _branch(last_layer, layer_in):
for i, e in enumerate(last_layer):
layer_in = e(layer_in)
if i == 4:
#将前五次卷积保存在out_branch里面,用于向下一步传递,
out_branch = layer_in
return layer_in, out_branch
# backbone
"""
首先用我们在darknet.py文件中定义的self.backbone(x)获得darknet框架中的最后三层(也就是整体框架图中的虚线框内的最后三个)
x2对应的是52x52x256的特征层,x1对应的是26x26x512的特征层,x0对应的是13x13x1024的特征层
"""
x2, x1, x0 = self.backbone(x)
# yolo branch 0
#预测结果保存在out0里面
out0, out0_branch = _branch(self.last_layer0, x0)
# yolo branch 1
#这里进行的是卷积和上采样
x1_in = self.last_layer1_conv(out0_branch)
x1_in = self.last_layer1_upsample(x1_in)
x1_in = torch.cat([x1_in, x1], 1)
out1, out1_branch = _branch(self.last_layer1, x1_in)
# yolo branch 2
x2_in = self.last_layer2_conv(out1_branch)
x2_in = self.last_layer2_upsample(x2_in)
x2_in = torch.cat([x2_in, x2], 1)
out2, _ = _branch(self.last_layer2, x2_in)
#最后的预测结果分贝保存在out0, out1, out2里面,用这些结果来判断里面是否含有物体,物体的种类是什么,如何调整先验框来获得最终的预测结果
return out0, out1, out2